
⚡ 3秒でわかる!この記事のポイント
- AWS AthenaでS3上のデータをSQLで直接クエリする方法を基礎から実践まで解説
- パーティション設計・Parquet変換・クエリ最適化でコストを90%削減するテクニック
- SES現場で活用できるデータ分析基盤の構築パターンとキャリア戦略
「S3に大量のログデータが溜まっているけど、分析する手段がない」——SES案件でデータ基盤を担当するエンジニアにとって、馴染みのある悩みではないでしょうか。従来のRDBにデータをロードしてからクエリを実行する方式では、ETLパイプラインの構築に時間がかかり、インフラコストもかさみます。
AWS Athenaは、S3上のデータに対して標準SQLで直接クエリを実行できるサーバーレスクエリサービスです。インフラの構築・管理が不要で、スキャンしたデータ量に応じた従量課金のため、コスト効率に優れています。
この記事では、AWS Athenaを使ったサーバーレスデータ分析の実践手法を、セットアップからコスト最適化まで詳しく解説します。
この記事でわかること
- AWS Athenaの基礎と仕組み(Presto/Trino ベース)
- S3上の各種フォーマット(CSV、JSON、Parquet)のクエリ方法
- パーティション設計によるクエリ性能とコストの最適化
- Glue Data Catalogとの連携によるスキーマ管理
- 実践的なログ分析・アクセス解析のクエリパターン
- SES現場でのデータ分析エンジニアのキャリア戦略
AWS Athenaとは?|サーバーレスクエリエンジンの基礎
Athenaのアーキテクチャ
AWS AthenaはPresto/Trinoをベースとしたサーバーレスクエリエンジンです。S3上のデータに対してスキーマを定義し、標準SQLでクエリを実行します。
AWS Athena のアーキテクチャ:
クライアント → Athena API → Trino クエリエンジン
↓
Glue Data Catalog
(スキーマ管理)
↓
S3 バケット
(データストア)
↓
クエリ結果を S3 に出力他のサービスとの比較
| 特性 | Athena | Redshift | BigQuery | RDS |
|---|---|---|---|---|
| タイプ | サーバーレスクエリ | データウェアハウス | サーバーレスDWH | リレーショナルDB |
| 課金 | スキャンデータ量 | インスタンス時間 | スキャン量+ストレージ | インスタンス時間 |
| 最小コスト | $0(未使用時) | 〜$200/月 | $0(未使用時) | 〜$30/月 |
| セットアップ | 即時 | 10〜30分 | 即時 | 5〜15分 |
| スケーリング | 自動 | 手動/自動 | 自動 | 手動 |
| 適したユースケース | アドホック分析 | 定常的な大規模分析 | 大規模分析 | トランザクション処理 |
Athenaのセットアップと基本クエリ
初期設定
-- 1. データベースの作成
CREATE DATABASE IF NOT EXISTS ses_analytics;
-- 2. クエリ結果の出力先を設定(Athenaコンソールまたは CLI で設定)
-- s3://ses-base-athena-results/query-output/CSV データのクエリ
S3上のCSVデータに対するテーブル定義:
-- ALBアクセスログのテーブル定義
CREATE EXTERNAL TABLE IF NOT EXISTS ses_analytics.alb_access_logs (
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code int,
target_status_code int,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
LOCATION 's3://ses-base-alb-logs/AWSLogs/123456789012/elasticloadbalancing/ap-northeast-1/'
TBLPROPERTIES ('has_encrypted_data'='false');JSONデータのクエリ
-- CloudTrailイベントログのテーブル定義
CREATE EXTERNAL TABLE IF NOT EXISTS ses_analytics.cloudtrail_logs (
eventversion string,
useridentity struct<
type: string,
principalid: string,
arn: string,
accountid: string,
invokedby: string,
accesskeyid: string,
username: string
>,
eventtime string,
eventsource string,
eventname string,
awsregion string,
sourceipaddress string,
useragent string,
errorcode string,
errormessage string,
requestparameters string,
responseelements string,
additionaleventdata string,
requestid string,
eventid string,
resources array<struct<
arn: string,
accountid: string,
type: string
>>,
eventtype string,
recipientaccountid string
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES ('ignore.malformed.json' = 'true')
LOCATION 's3://ses-base-cloudtrail/AWSLogs/123456789012/CloudTrail/ap-northeast-1/'
TBLPROPERTIES ('has_encrypted_data'='false');パーティション設計|クエリ性能とコストの最適化
なぜパーティションが重要か
Athenaはスキャンしたデータ量に応じて課金されます($5/TB)。パーティションなしでは全データをスキャンしてしまい、コストが膨大になります。
パーティションなし:
クエリ → S3全体をスキャン(例: 1TB → $5.00)
パーティションあり(年/月/日で分割):
クエリ → 該当日のデータのみスキャン(例: 10GB → $0.05)
→ コスト99%削減!パーティションテーブルの作成
-- パーティション付きテーブルの作成
CREATE EXTERNAL TABLE IF NOT EXISTS ses_analytics.app_logs_partitioned (
timestamp string,
level string,
service string,
message string,
trace_id string,
user_id string,
request_method string,
request_path string,
response_status int,
response_time_ms int,
error_type string,
error_message string
)
PARTITIONED BY (
year string,
month string,
day string
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 's3://ses-base-app-logs/structured/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'projection.enabled' = 'true',
'projection.year.type' = 'integer',
'projection.year.range' = '2024,2030',
'projection.month.type' = 'integer',
'projection.month.range' = '1,12',
'projection.month.digits' = '2',
'projection.day.type' = 'integer',
'projection.day.range' = '1,31',
'projection.day.digits' = '2',
'storage.location.template' = 's3://ses-base-app-logs/structured/${year}/${month}/${day}/'
);パーティションプロジェクション vs MSCK REPAIR
-- 方法1: パーティションプロジェクション(推奨)
-- テーブル定義時に projection.* プロパティを設定するだけ
-- 新しいパーティションを自動認識、ALTER TABLE不要
-- 方法2: MSCK REPAIR TABLE(手動管理)
MSCK REPAIR TABLE ses_analytics.app_logs_partitioned;
-- 注意: 大量のパーティションがあると実行に時間がかかる
-- 方法3: ALTER TABLE で個別追加
ALTER TABLE ses_analytics.app_logs_partitioned
ADD PARTITION (year='2026', month='04', day='01')
LOCATION 's3://ses-base-app-logs/structured/2026/04/01/';データ形式の最適化|Parquet変換
CSV → Parquet変換によるパフォーマンス改善
Parquet形式はカラムナー(列指向)ストレージで、特定の列だけを効率的に読み取れます:
-- CSVテーブルからParquetテーブルへの変換(CTAS)
CREATE TABLE ses_analytics.app_logs_parquet
WITH (
format = 'PARQUET',
parquet_compression = 'SNAPPY',
external_location = 's3://ses-base-app-logs/parquet/',
partitioned_by = ARRAY['year', 'month']
) AS
SELECT
timestamp,
level,
service,
message,
trace_id,
user_id,
request_method,
request_path,
response_status,
response_time_ms,
year,
month
FROM ses_analytics.app_logs_partitioned
WHERE year = '2026';形式別パフォーマンス比較
| データ形式 | 圧縮率 | クエリ速度 | スキャン量 | 適したユースケース |
|---|---|---|---|---|
| CSV | 1x | 遅い | 大 | 小規模データ、互換性重視 |
| JSON | 1x | 遅い | 大 | 半構造化データ |
| Parquet | 5-10x | 速い | 小 | 分析クエリ(推奨) |
| ORC | 5-10x | 速い | 小 | Hiveエコシステム |
| Avro | 2-3x | 中 | 中 | スキーマ進化が必要な場合 |
実践的なクエリパターン
アクセスログ分析
-- 1. 時間帯別アクセス数の分析
SELECT
DATE_FORMAT(FROM_ISO8601_TIMESTAMP(timestamp), '%Y-%m-%d %H:00') as hour,
COUNT(*) as request_count,
AVG(response_time_ms) as avg_response_time,
APPROX_PERCENTILE(response_time_ms, 0.95) as p95_response_time,
COUNT(CASE WHEN response_status >= 500 THEN 1 END) as error_count,
ROUND(COUNT(CASE WHEN response_status >= 500 THEN 1 END) * 100.0 / COUNT(*), 2) as error_rate
FROM ses_analytics.app_logs_parquet
WHERE year = '2026' AND month = '04'
GROUP BY 1
ORDER BY 1;
-- 2. エラー頻度の高いエンドポイントTOP10
SELECT
request_path,
request_method,
COUNT(*) as total_requests,
COUNT(CASE WHEN response_status >= 400 THEN 1 END) as error_count,
ROUND(COUNT(CASE WHEN response_status >= 400 THEN 1 END) * 100.0 / COUNT(*), 2) as error_rate,
AVG(response_time_ms) as avg_response_time
FROM ses_analytics.app_logs_parquet
WHERE year = '2026' AND month = '04'
GROUP BY 1, 2
HAVING COUNT(*) > 100
ORDER BY error_rate DESC
LIMIT 10;
-- 3. レスポンスタイムの遅いリクエストの詳細
SELECT
timestamp,
request_method,
request_path,
response_status,
response_time_ms,
user_id,
trace_id
FROM ses_analytics.app_logs_parquet
WHERE year = '2026' AND month = '04'
AND response_time_ms > 3000
ORDER BY response_time_ms DESC
LIMIT 50;セキュリティ監査クエリ
-- 4. 不審なAPIアクセスの検出
SELECT
sourceipaddress,
useridentity.username,
eventname,
COUNT(*) as event_count,
MIN(eventtime) as first_seen,
MAX(eventtime) as last_seen
FROM ses_analytics.cloudtrail_logs
WHERE eventtime >= '2026-04-01'
AND errorcode IS NOT NULL
AND errorcode IN ('AccessDenied', 'UnauthorizedAccess', 'Client.UnauthorizedAccess')
GROUP BY 1, 2, 3
HAVING COUNT(*) > 10
ORDER BY event_count DESC;
-- 5. IAMポリシー変更の監査
SELECT
eventtime,
useridentity.arn as who,
eventname as what,
requestparameters as details,
sourceipaddress as from_ip
FROM ses_analytics.cloudtrail_logs
WHERE eventtime >= '2026-04-01'
AND eventsource = 'iam.amazonaws.com'
AND eventname LIKE '%Policy%'
ORDER BY eventtime DESC;コスト分析クエリ
-- 6. S3ストレージのコスト分析
-- CUR(Cost and Usage Report)テーブルに対するクエリ
SELECT
line_item_product_code,
line_item_usage_type,
SUM(line_item_unblended_cost) as cost,
SUM(line_item_usage_amount) as usage_amount
FROM ses_analytics.cost_and_usage_report
WHERE year = '2026' AND month = '03'
AND line_item_product_code = 'AmazonS3'
GROUP BY 1, 2
ORDER BY cost DESC;Glue Data Catalogとの連携
スキーマの自動検出
# AWS Glueクローラーの設定
aws glue create-crawler \
--name ses-base-log-crawler \
--role AWSGlueServiceRole \
--database-name ses_analytics \
--targets '{
"S3Targets": [
{
"Path": "s3://ses-base-app-logs/structured/",
"Exclusions": ["**/_temporary/**"]
}
]
}' \
--schedule 'cron(0 1 * * ? *)' \
--schema-change-policy '{
"UpdateBehavior": "UPDATE_IN_DATABASE",
"DeleteBehavior": "LOG"
}'
# クローラーの実行
aws glue start-crawler --name ses-base-log-crawlerGlue ETLジョブでのデータ変換
# Glue ETLジョブ: CSV → Parquet変換
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# ソースデータの読み込み
source = glueContext.create_dynamic_frame.from_catalog(
database="ses_analytics",
table_name="app_logs_csv"
)
# データ変換
transformed = ApplyMapping.apply(
frame=source,
mappings=[
("timestamp", "string", "timestamp", "string"),
("level", "string", "level", "string"),
("service", "string", "service", "string"),
("message", "string", "message", "string"),
("response_time_ms", "string", "response_time_ms", "int"),
("response_status", "string", "response_status", "int"),
]
)
# Parquet形式で出力(パーティション付き)
glueContext.write_dynamic_frame.from_options(
frame=transformed,
connection_type="s3",
connection_options={
"path": "s3://ses-base-app-logs/parquet/",
"partitionKeys": ["year", "month", "day"]
},
format="parquet",
format_options={"compression": "snappy"}
)
job.commit()コスト最適化のベストプラクティス
Athenaのコスト構造
Athenaの課金: $5.00 / TB(スキャンデータ量)
最低課金: 10MB / クエリ
コスト削減の3本柱:
1. パーティション → 不要なデータのスキャンを回避
2. カラムナーフォーマット(Parquet/ORC) → 必要な列のみスキャン
3. 圧縮 → データサイズ自体を削減コスト最適化チェックリスト
-- クエリごとのスキャン量を確認
-- Athenaコンソールで「Query stats」を確認
-- またはCloudWatchメトリクス: DataScannedInBytes
-- 改善前: SELECT * はNG
SELECT * FROM ses_analytics.app_logs_parquet
WHERE year = '2026';
-- → 全列をスキャン、コスト大
-- 改善後: 必要な列だけ選択
SELECT timestamp, service, response_status, response_time_ms
FROM ses_analytics.app_logs_parquet
WHERE year = '2026' AND month = '04' AND day = '01';
-- → 特定列 + 特定パーティションのみスキャン、コスト最小Athena ワークグループによるコスト管理
# ワークグループの作成(クエリコスト上限付き)
aws athena create-work-group \
--name ses-dev-team \
--configuration '{
"ResultConfiguration": {
"OutputLocation": "s3://ses-base-athena-results/ses-dev-team/"
},
"EnforceWorkGroupConfiguration": true,
"BytesScannedCutoffPerQuery": 1073741824,
"RequesterPaysEnabled": false
}' \
--description "SES開発チーム用(1GB/クエリ上限)"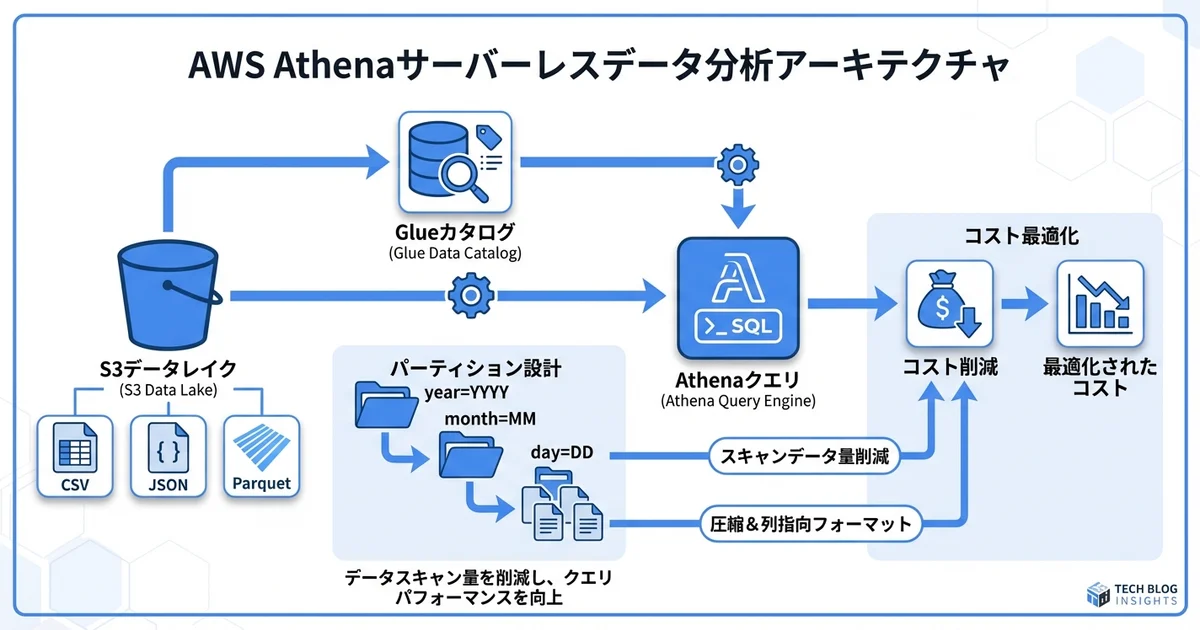
Terraformによるインフラ定義
Athena環境のIaC化
# Athena ワークグループ
resource "aws_athena_workgroup" "ses_analytics" {
name = "ses-analytics"
configuration {
enforce_workgroup_configuration = true
bytes_scanned_cutoff_per_query = 10737418240 # 10GB上限
result_configuration {
output_location = "s3://${aws_s3_bucket.athena_results.bucket}/output/"
encryption_configuration {
encryption_option = "SSE_S3"
}
}
}
tags = {
Environment = "production"
Project = "ses-base"
}
}
# Glue データベース
resource "aws_glue_catalog_database" "ses_analytics" {
name = "ses_analytics"
create_table_default_permission {
permissions = ["ALL"]
principal {
data_lake_principal_identifier = "IAM_ALLOWED_PRINCIPALS"
}
}
}
# クエリ結果用S3バケット
resource "aws_s3_bucket" "athena_results" {
bucket = "ses-base-athena-results"
}
resource "aws_s3_bucket_lifecycle_configuration" "athena_results" {
bucket = aws_s3_bucket.athena_results.id
rule {
id = "cleanup-old-results"
status = "Enabled"
expiration {
days = 30 # 30日後に自動削除
}
}
}
# Glueクローラー
resource "aws_glue_crawler" "app_logs" {
database_name = aws_glue_catalog_database.ses_analytics.name
name = "ses-base-app-logs-crawler"
role = aws_iam_role.glue_role.arn
s3_target {
path = "s3://ses-base-app-logs/structured/"
}
schedule = "cron(0 1 * * ? *)"
schema_change_policy {
update_behavior = "UPDATE_IN_DATABASE"
delete_behavior = "LOG"
}
}SES現場でのAthenaスキルの市場価値
データ分析エンジニアの需要と単価
| スキルレベル | 対応可能範囲 | 月単価目安 |
|---|---|---|
| 基本レベル | Athenaの基本クエリ・テーブル定義 | 60〜75万円 |
| 中級レベル | パーティション設計・Parquet変換・Glue連携 | 75〜90万円 |
| 上級レベル | データレイク設計・ETLパイプライン・コスト最適化 | 90〜110万円 |
| エキスパート | データメッシュ・リアルタイム分析・MLパイプライン | 110〜130万円 |
学習ロードマップ
STEP 1: Athenaの基礎(1-2週間)
├── テーブル定義と基本クエリ
├── CSV/JSONデータのクエリ
└── パーティションの基礎
STEP 2: 最適化テクニック(2-3週間)
├── Parquet変換とCTAS
├── パーティションプロジェクション
└── クエリパフォーマンスチューニング
STEP 3: データレイク構築(3-4週間)
├── Glue Data Catalog管理
├── ETLパイプラインの設計
└── Terraformによるインフラ定義
STEP 4: 高度な分析(継続的)
├── Window関数・CTE活用
├── フェデレーテッドクエリ
└── QuickSightとの連携まとめ|AWS Athenaでサーバーレスデータ分析を始めよう
AWS Athenaを活用することで、インフラ管理なしにS3上の大量データを効率的に分析できます。
この記事で紹介した主なポイント:
- Athena基礎: S3データに対するSQLクエリの基本と各種フォーマット対応
- パーティション設計: クエリコストを90%以上削減するパーティション戦略
- データ最適化: Parquet変換による性能・コストの同時改善
- 実践クエリ: ログ分析・セキュリティ監査・コスト分析のパターン
- Glue連携: スキーマ自動検出とETLジョブ
- IaC: Terraformによるインフラの一元管理
サーバーレスデータ分析のスキルは、2026年のSES市場で高い需要があります。Athenaを起点にデータエンジニアリングのスキルを磨いていきましょう。
💡 SES BASEでデータ分析案件を探す
AWS Athena・データレイク・データ分析のスキルを活かせるSES案件をお探しなら、SES BASEで最新案件をチェックしましょう。





