- Amazon Redshiftは列指向ストレージと超並列処理で大規模データ分析を高速に実行できる
- 分散キー・ソートキー・カラム圧縮の設計がクエリ性能とコストに直結する
- Redshift案件はSES市場で単価70-95万円と高く、データエンジニアの需要が急増中
「数十億行のデータを分析したいけど、RDSでは遅すぎる…」
データ量が増え続ける現代のシステム開発において、**データウェアハウス(DWH)**の重要性は増す一方です。Amazon Redshiftは、ペタバイトスケールのデータを高速に分析できるフルマネージドDWHサービスで、多くの企業の分析基盤として採用されています。
この記事では、Redshiftの設計・構築・運用の実践ノウハウを、SESエンジニアの視点で体系的に解説します。
- Redshiftのアーキテクチャと特徴(列指向・MPP)
- テーブル設計(分散キー・ソートキー・圧縮)の実践テクニック
- クエリ最適化とパフォーマンスチューニング
- Redshift Serverless vs プロビジョンドの選択基準
- SES現場でのDWH案件の需要と必要スキル
Redshiftのアーキテクチャ
列指向ストレージとMPP
Redshiftが高速な分析クエリを実現する2つの技術的特徴を理解しましょう。
列指向ストレージ(Columnar Storage)
行指向データベース(MySQL、PostgreSQL)とは異なり、Redshiftはデータを列(カラム)単位で格納します。
-- 行指向(RDS): 1行のデータをまとめて格納
Row1: [id=1, name="田中", dept="開発", salary=600000]
Row2: [id=2, name="佐藤", dept="営業", salary=550000]
-- 列指向(Redshift): 各カラムのデータをまとめて格納
id列: [1, 2, 3, 4, ...]
name列: ["田中", "佐藤", "鈴木", "高橋", ...]
dept列: ["開発", "営業", "開発", "企画", ...]
salary列: [600000, 550000, 700000, 580000, ...]この構造により、SELECT AVG(salary) FROM employees WHERE dept = '開発' のような分析クエリでは、必要なカラムだけを読み込むため、大幅にI/Oが削減されます。
超並列処理(MPP: Massively Parallel Processing)
Redshiftクラスターは、1つのリーダーノードと複数のコンピュートノードで構成されます。クエリは自動的に分割され、各ノードで並列実行されます。
[クライアント]
↓
[リーダーノード] ← クエリ解析・実行計画作成
↓ ↓ ↓ ↓
[ノード1][ノード2][ノード3][ノード4] ← 並列実行
↓ ↓ ↓ ↓
[リーダーノード] ← 結果集約
↓
[クライアント]テーブル設計の実践
分散スタイル(Distribution Style)
Redshiftでのテーブル設計で最も重要なのが分散スタイルの選択です。データが各ノードにどのように分散されるかを決定します。
-- KEY分散: 指定したカラムのハッシュ値で分散
-- JOINの多いカラムに指定(データの偏りに注意)
CREATE TABLE orders (
order_id BIGINT NOT NULL,
customer_id BIGINT NOT NULL,
order_date DATE NOT NULL,
total_amount DECIMAL(12,2)
)
DISTKEY(customer_id) -- customer_idでJOINすることが多い
SORTKEY(order_date); -- 日付でフィルタすることが多い
-- ALL分散: 全ノードにコピー
-- 小さなマスタテーブルに使用
CREATE TABLE departments (
dept_id INT NOT NULL,
dept_name VARCHAR(100),
manager_id BIGINT
)
DISTSTYLE ALL; -- 全ノードにコピー(小テーブル向け)
-- EVEN分散: ラウンドロビンで均等分散
-- JOINしないテーブル or 最適な分散キーがない場合
CREATE TABLE event_logs (
log_id BIGINT IDENTITY(1,1),
event_type VARCHAR(50),
event_data SUPER,
created_at TIMESTAMP
)
DISTSTYLE EVEN;
-- AUTO分散(推奨): Redshiftが自動判断
CREATE TABLE products (
product_id BIGINT NOT NULL,
product_name VARCHAR(200),
category_id INT,
price DECIMAL(10,2)
)
DISTSTYLE AUTO;分散キー選択の判断基準
| 条件 | 推奨分散スタイル |
|---|---|
| テーブルサイズが小さい(数百万行以下) | ALL |
| 頻繁にJOINされるカラムがある | KEY(JOINカラム) |
| 特定のカラムに偏りが少ない | KEY |
| 明確な分散キーがない | EVEN or AUTO |
| 不明な場合 | AUTO(Redshiftに任せる) |
ソートキーの設計
ソートキーは、クエリの WHERE 句や ORDER BY で使われるカラムに設定します。
-- 単一ソートキー: 1つのカラムでソート
CREATE TABLE sales_daily (
sale_date DATE NOT NULL,
store_id INT,
product_id INT,
quantity INT,
revenue DECIMAL(12,2)
)
DISTKEY(store_id)
SORTKEY(sale_date);
-- WHERE sale_date BETWEEN ... のクエリが高速に
-- 複合ソートキー: 複数カラムの組み合わせ
CREATE TABLE access_logs (
log_date DATE NOT NULL,
user_id BIGINT,
page_url VARCHAR(2000),
response_time INT,
status_code INT
)
DISTKEY(user_id)
COMPOUND SORTKEY(log_date, user_id);
-- WHERE log_date = ... AND user_id = ... のクエリが高速に
-- インターリーブソートキー: どのカラムからでも高速検索
CREATE TABLE search_index (
category VARCHAR(50),
region VARCHAR(50),
price_range INT,
rating DECIMAL(2,1),
created_at DATE
)
INTERLEAVED SORTKEY(category, region, price_range);
-- WHERE category = ... OR WHERE region = ... どちらも高速カラム圧縮エンコーディング
Redshiftでは、各カラムに最適な圧縮方式を指定することで、ストレージサイズを削減しI/O性能を向上させます。
-- 圧縮エンコーディングの指定
CREATE TABLE transaction_history (
txn_id BIGINT ENCODE delta, -- 連番に最適
account_id BIGINT ENCODE az64, -- 数値のデフォルト
txn_type VARCHAR(20) ENCODE bytedict, -- カーディナリティが低い
amount DECIMAL(12,2) ENCODE az64, -- 数値
description VARCHAR(500) ENCODE zstd, -- 可変長テキスト
txn_date DATE ENCODE delta32k, -- 日付
created_at TIMESTAMP ENCODE az64 -- タイムスタンプ
);
-- 自動圧縮の分析(推奨)
ANALYZE COMPRESSION transaction_history;
-- Redshiftが各カラムの最適な圧縮方式を提案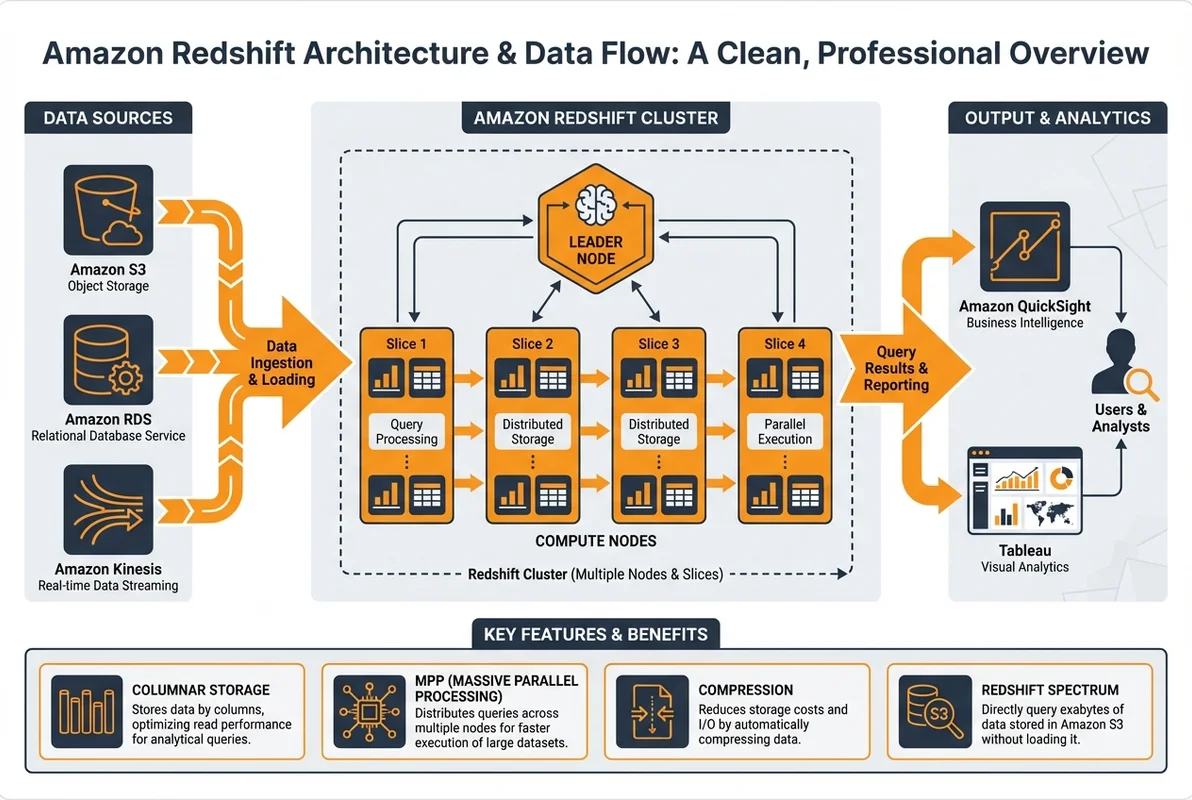
クエリ最適化
実行計画の分析
-- EXPLAIN でクエリの実行計画を確認
EXPLAIN
SELECT c.customer_name, SUM(o.total_amount) as total_spent
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
WHERE o.order_date >= '2025-01-01'
GROUP BY c.customer_name
ORDER BY total_spent DESC
LIMIT 100;
-- 出力例:
-- XN Limit (cost=1000.00..1000.25 rows=100)
-- -> XN Merge (cost=1000.00..1000.50 rows=200)
-- Merge Key: sum(o.total_amount)
-- -> XN Network (cost=1000.00..1000.50 rows=200)
-- Send to leader
-- -> XN Sort (cost=1000.00..1000.50 rows=200)
-- Sort Key: sum(o.total_amount)
-- -> XN HashAggregate (cost=800.00..850.00)
-- -> XN Hash Join DS_DIST_NONE ← 分散最適化済
-- -> XN Seq Scan on orders o
-- Filter: (order_date >= '2025-01-01')
-- -> XN Hash (cost=100.00..100.00)
-- -> XN Seq Scan on customers cよくある最適化パターン
1. ノード間データ転送の削減
-- ❌ DS_DIST_BOTH: 両テーブルの再分散が発生(遅い)
-- customersとordersのDISTKEYが異なる場合
-- ✅ 同じDISTKEYに揃える
ALTER TABLE customers ALTER DISTKEY customer_id;
ALTER TABLE orders ALTER DISTKEY customer_id;
-- → DS_DIST_NONE: 再分散なし(高速)2. ソートマージ結合の活用
-- ソートキーを活用した結合(SORTKEYがJOINカラムの場合)
-- Merge Joinが使われ、Hash Joinより高速
CREATE TABLE fact_sales (
sale_id BIGINT,
product_id INT,
sale_date DATE,
quantity INT
)
DISTKEY(product_id)
SORTKEY(product_id); -- JOINカラムでソート
CREATE TABLE dim_products (
product_id INT,
product_name VARCHAR(200)
)
DISTSTYLE ALL
SORTKEY(product_id); -- JOINカラムでソート3. 大規模集計の効率化
-- 近似集計関数で高速化(誤差2%以内)
-- 正確な値が不要な場合に有効
SELECT
category,
APPROXIMATE COUNT(DISTINCT user_id) as unique_users,
APPROXIMATE PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY amount) as median_amount
FROM sales
GROUP BY category;Redshift Serverless vs プロビジョンド
選択基準
| 観点 | Redshift Serverless | プロビジョンド |
|---|---|---|
| 課金体系 | RPU(使った分だけ) | ノード数 × 時間 |
| 適切な用途 | 間欠的なクエリ、開発/テスト | 常時高負荷、予測可能なワークロード |
| スケーリング | 自動 | 手動 or Elastic Resize |
| 初期コスト | 低い | 高い |
| 最大性能 | RPU上限あり | ノード数に比例 |
| 管理工数 | 低い | 中〜高 |
Serverlessの設定例
-- Redshift Serverless のワークグループ作成(Terraform)
resource "aws_redshiftserverless_workgroup" "analytics" {
workgroup_name = "analytics-workgroup"
namespace_name = aws_redshiftserverless_namespace.analytics.namespace_name
base_capacity = 32 # RPU(最小8、8単位で増加)
config_parameter {
parameter_key = "search_path"
parameter_value = "analytics,public"
}
config_parameter {
parameter_key = "query_group"
parameter_value = "default"
}
}
resource "aws_redshiftserverless_namespace" "analytics" {
namespace_name = "analytics-namespace"
admin_username = "admin"
admin_user_password = var.redshift_admin_password
db_name = "analytics"
iam_roles = [aws_iam_role.redshift_role.arn]
}ETL/ELTパイプライン
S3からのデータロード
-- COPYコマンドによる高速ロード
COPY sales_staging
FROM 's3://my-data-lake/sales/2026/04/'
IAM_ROLE 'arn:aws:iam::123456789012:role/RedshiftS3Access'
FORMAT AS PARQUET;
-- Parquet形式なら列指向のまま効率的にロード
-- CSVの場合
COPY event_logs
FROM 's3://my-data-lake/events/2026-04-01/'
IAM_ROLE 'arn:aws:iam::123456789012:role/RedshiftS3Access'
CSV
IGNOREHEADER 1
DATEFORMAT 'auto'
TIMEFORMAT 'auto'
MAXERROR 100
COMPUPDATE ON; -- 最適な圧縮を自動適用マテリアライズドビューの活用
-- 頻繁に実行される集計クエリをマテリアライズドビューで高速化
CREATE MATERIALIZED VIEW mv_monthly_sales
AUTO REFRESH YES -- データ変更時に自動更新
AS
SELECT
DATE_TRUNC('month', sale_date) as month,
store_id,
category_id,
COUNT(*) as transaction_count,
SUM(quantity) as total_quantity,
SUM(revenue) as total_revenue,
AVG(revenue) as avg_revenue
FROM fact_sales
JOIN dim_products USING (product_id)
GROUP BY 1, 2, 3;
-- マテリアライズドビューを使ったクエリ(自動リライト)
SELECT month, SUM(total_revenue)
FROM mv_monthly_sales
WHERE store_id = 101
GROUP BY month
ORDER BY month;
-- Redshiftが自動的にMVを使用(高速)Redshift Spectrum
S3上のデータを直接クエリ
Redshift Spectrumを使えば、S3に格納されたデータをRedshiftにロードせずに直接クエリできます。
-- 外部スキーマの作成
CREATE EXTERNAL SCHEMA spectrum_schema
FROM DATA CATALOG
DATABASE 'my_data_catalog'
IAM_ROLE 'arn:aws:iam::123456789012:role/RedshiftSpectrumRole'
CREATE EXTERNAL DATABASE IF NOT EXISTS;
-- S3上のParquetデータにアクセス
CREATE EXTERNAL TABLE spectrum_schema.historical_logs (
log_id BIGINT,
event_type VARCHAR(50),
user_id BIGINT,
event_data VARCHAR(MAX),
event_date DATE
)
STORED AS PARQUET
LOCATION 's3://my-data-lake/historical-logs/'
PARTITIONED BY (event_date DATE);
-- Redshiftのテーブルと結合
SELECT u.user_name, COUNT(h.log_id) as event_count
FROM users u
JOIN spectrum_schema.historical_logs h ON u.user_id = h.user_id
WHERE h.event_date >= '2025-01-01'
GROUP BY u.user_name
ORDER BY event_count DESC
LIMIT 100;コスト最適化
コスト削減のベストプラクティス
-- 1. 不要なテーブルの特定
SELECT "table", size, tbl_rows
FROM SVV_TABLE_INFO
WHERE "table" NOT LIKE 'pg_%'
ORDER BY size DESC
LIMIT 20;
-- 2. 使われていないテーブルの検出
SELECT t.table_name,
MAX(q.starttime) as last_queried
FROM information_schema.tables t
LEFT JOIN stl_query q ON q.querytxt LIKE '%' || t.table_name || '%'
WHERE t.table_schema = 'public'
GROUP BY t.table_name
HAVING MAX(q.starttime) < DATEADD(day, -90, GETDATE())
OR MAX(q.starttime) IS NULL;
-- 3. 圧縮率の確認と改善
SELECT "table" as tablename,
encoded,
diststyle,
sortkey1,
size as size_mb,
pct_used
FROM SVV_TABLE_INFO
WHERE encoded = 'N' -- 未圧縮のテーブル
ORDER BY size DESC;SES現場でのDWH案件
需要と単価
| スキル | 月単価目安 | 主な案件タイプ |
|---|---|---|
| Redshift設計・構築 | 75-95万円 | DWH新規構築、分析基盤設計 |
| ETLパイプライン開発 | 70-90万円 | Glue、Step Functions連携 |
| データモデリング | 70-85万円 | スタースキーマ、SCD設計 |
| Redshift運用・チューニング | 65-80万円 | 性能改善、コスト最適化 |
面談でアピールできるスキルセット
【DWH構築実績】
- Amazon Redshiftで日次10億行のDWHを設計・構築
- 分散キー・ソートキーの最適化でクエリ応答時間を85%削減
- Redshift Spectrumでコールド→ホットのデータ階層化を実装し
ストレージコストを60%削減
- Glue + Step Functionsで全自動ETLパイプラインを構築まとめ
Amazon Redshiftを活用したDWH構築は、以下のステップで進めるのが効果的です。
- アーキテクチャ選択: Serverless vs プロビジョンドの判断
- テーブル設計: 分散キー・ソートキー・圧縮の最適化
- ETLパイプライン: S3からの効率的なデータロード
- クエリ最適化: 実行計画分析とマテリアライズドビュー活用
- コスト管理: 不要データの特定とSpectrum活用
DWHスキルはSES市場で高い需要があります。Redshiftの設計・運用経験は、データエンジニアとして高単価案件を獲得するための重要なスキルです。
関連記事
- AWS Glue ETLデータパイプラインガイドでは、Glueを使ったETLの詳細を解説
- AWS DynamoDB NoSQLガイドでは、NoSQLデータベースの活用法を紹介
- AWS Kinesis リアルタイムデータ処理ガイドでは、ストリーミングデータの活用を解説