「データ分析基盤を構築したいが、ETLの設計が複雑で手が出ない」「既存のバッチ処理をクラウドネイティブに移行したい」「AWS Glueを聞いたことはあるが、何から始めれば良いかわからない」——データエンジニアリングに踏み出そうとするエンジニアがよく抱える悩みです。
AWS Glueは、データの抽出・変換・ロード(ETL)をサーバーレスで実行できるフルマネージドサービスです。インフラ管理不要でSparkベースのETLジョブを実行でき、データカタログによるメタデータ管理も統合されています。本記事では、設計から実装・運用まで実践的に解説します。
この記事を3秒でまとめると
- AWS Glueはサーバーレス+Sparkで大規模ETLをインフラ管理なしに実行可能
- データカタログとクローラーでメタデータを自動管理
- SES案件でデータエンジニアリングスキルは高単価の差別化ポイント
AWS Glueとは
AWS Glueは、AWSが提供するフルマネージドのETL(Extract, Transform, Load)サービスです。2016年のリリース以降、継続的に機能が強化され、2026年現在ではGlue 5.0が最新バージョンとなっています。
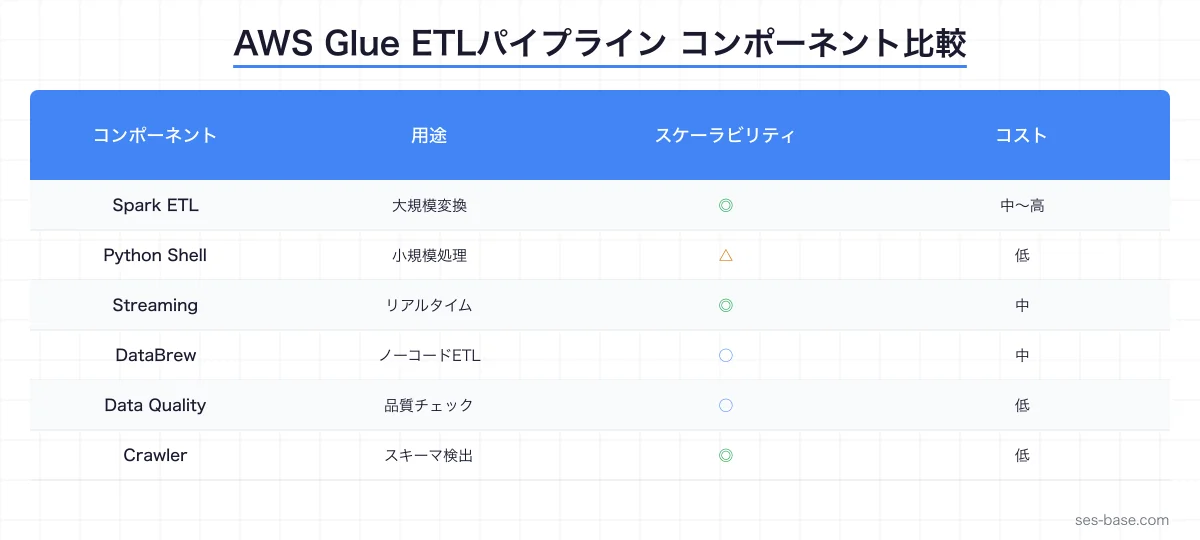
主要コンポーネント
| コンポーネント | 役割 | 特徴 |
|---|---|---|
| データカタログ | メタデータ管理 | Hive Metastore互換・Athena/Redshift連携 |
| クローラー | スキーマ自動検出 | S3・RDS・DynamoDB等を自動スキャン |
| ETLジョブ | データ変換処理 | PySpark / Scala / Python Shell |
| ワークフロー | ジョブオーケストレーション | DAG形式のジョブ依存管理 |
| DataBrew | ノーコードETL | GUIでの変換定義 |
| Data Quality | データ品質チェック | DQDL言語でルール定義 |
なぜAWS Glueなのか
- サーバーレス: EC2やEMRのクラスタ管理が不要
- Spark内蔵: 大規模データを分散処理
- データカタログ: Athena・Redshift・EMRと共有できるメタデータストア
- コスト: DPU(Data Processing Unit)単位の従量課金
- AWSエコシステム: S3・Redshift・RDS・DynamoDB等とのネイティブ連携
データカタログの構築
クローラーによるスキーマ自動検出
AWS Glueクローラーは、データソースをスキャンしてスキーマを自動検出し、データカタログに登録します。
import boto3
glue = boto3.client('glue')
# S3データソース用クローラーの作成
glue.create_crawler(
Name='ses-project-data-crawler',
Role='arn:aws:iam::123456789012:role/GlueServiceRole',
DatabaseName='ses_data_lake',
Targets={
'S3Targets': [
{
'Path': 's3://ses-base-data-lake/raw/projects/',
'Exclusions': ['**/_temporary/**', '**/.spark-staging/**']
},
{
'Path': 's3://ses-base-data-lake/raw/engineers/',
}
]
},
Schedule='cron(0 6 * * ? *)', # 毎朝6時に実行
SchemaChangePolicy={
'UpdateBehavior': 'UPDATE_IN_DATABASE',
'DeleteBehavior': 'LOG'
},
Configuration=json.dumps({
'Version': 1.0,
'Grouping': {
'TableGroupingPolicy': 'CombineCompatibleSchemas'
}
})
)カタログテーブルの管理
クローラーが検出したテーブルは、Athenaから直接クエリできます:
-- Athenaからデータカタログのテーブルをクエリ
SELECT
skill_name,
COUNT(*) as project_count,
AVG(unit_price) as avg_price
FROM ses_data_lake.projects
WHERE year = '2026' AND month = '03'
GROUP BY skill_name
ORDER BY project_count DESC
LIMIT 20;ポイント: Glueデータカタログは、Athena・Redshift Spectrum・EMRの共通メタデータストアとして機能します。一度カタログに登録すれば、複数のサービスから同じテーブル定義でデータにアクセスできます。
ETLジョブの設計と実装
PySparkによるETLジョブ
AWS GlueのETLジョブは、PySpark(Python + Apache Spark)で記述します。Glue独自のDynamicFrameと標準のDataFrameの両方が使えます。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.context import SparkContext
from pyspark.sql import functions as F
# 初期化
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# 1. Extract: データカタログからデータを読み込み
projects_dyf = glueContext.create_dynamic_frame.from_catalog(
database="ses_data_lake",
table_name="raw_projects"
)
engineers_dyf = glueContext.create_dynamic_frame.from_catalog(
database="ses_data_lake",
table_name="raw_engineers"
)
# DynamicFrame → DataFrame に変換
projects_df = projects_dyf.toDF()
engineers_df = engineers_dyf.toDF()
# 2. Transform: データクレンジングと変換
# 単価を正規化(万円単位に統一)
projects_cleaned = projects_df \
.filter(F.col("unit_price").isNotNull()) \
.filter(F.col("unit_price") > 0) \
.withColumn("unit_price_normalized",
F.when(F.col("price_unit") == "yen", F.col("unit_price") / 10000)
.otherwise(F.col("unit_price"))
) \
.withColumn("processed_at", F.current_timestamp()) \
.dropDuplicates(["project_id"])
# スキル情報をフラットに展開
skills_exploded = projects_cleaned \
.withColumn("skill", F.explode("required_skills")) \
.select(
"project_id",
"title",
"unit_price_normalized",
F.col("skill.name").alias("skill_name"),
F.col("skill.level").alias("skill_level"),
"remote_policy",
"prefecture",
"processed_at"
)
# 3. Load: 変換済みデータをS3に書き出し(Parquet形式)
skills_exploded.write \
.mode("overwrite") \
.partitionBy("skill_name") \
.parquet("s3://ses-base-data-lake/processed/project_skills/")
# ジョブブックマーク更新
job.commit()ジョブブックマークによる増分処理
Glueのジョブブックマーク機能を有効にすると、前回処理済みのデータをスキップして増分データのみを処理できます。毎回全データを再処理する必要がなくなり、処理時間とコストを大幅に削減できます。
データ品質管理
Glue Data Qualityの活用
AWS Glue Data Qualityは、ETLパイプラインにデータ品質チェックを組み込む機能です。
# DQDL(Data Quality Definition Language)でルール定義
dqdl_rules = """
Rules = [
RowCount > 100,
Completeness "project_id" = 1.0,
Completeness "title" >= 0.99,
ColumnValues "unit_price" between 30 and 200,
Uniqueness "project_id" = 1.0,
ColumnLength "title" between 5 and 200,
CustomSql "SELECT COUNT(*) FROM primary WHERE processed_at >= current_date - interval 1 day" > 0
]
"""品質チェックのパイプライン組み込み
- 入力データチェック: 生データの品質を検証してから変換処理
- 変換後チェック: 変換結果が期待通りか確認
- 出力データチェック: ロード先のデータ整合性を確認
- アラート: 品質基準を下回った場合にSNS/Slackに通知
ワークフローによるジョブオーケストレーション
Glue Workflowの設計
複数のETLジョブを依存関係に基づいて実行するワークフローを設計します。
# ワークフローの作成
glue.create_workflow(
Name='ses-daily-etl-pipeline',
Description='SES案件データの日次ETLパイプライン',
DefaultRunProperties={
'processing_date': '${CURRENT_DATE}'
}
)
# トリガーの作成(スケジュール起動)
glue.create_trigger(
Name='daily-schedule-trigger',
WorkflowName='ses-daily-etl-pipeline',
Type='SCHEDULED',
Schedule='cron(0 7 * * ? *)',
Actions=[
{'JobName': 'crawl-raw-data'},
]
)
# 条件付きトリガー(前ジョブ成功後に実行)
glue.create_trigger(
Name='transform-after-crawl',
WorkflowName='ses-daily-etl-pipeline',
Type='CONDITIONAL',
Predicate={
'Conditions': [
{
'LogicalOperator': 'EQUALS',
'JobName': 'crawl-raw-data',
'State': 'SUCCEEDED'
}
]
},
Actions=[
{'JobName': 'transform-project-data'},
{'JobName': 'transform-engineer-data'},
]
)Step Functionsとの連携
より複雑なオーケストレーションが必要な場合は、AWS Step Functionsと組み合わせます:
{
"StartAt": "CrawlRawData",
"States": {
"CrawlRawData": {
"Type": "Task",
"Resource": "arn:aws:states:::glue:startJobRun.sync",
"Parameters": {
"JobName": "crawl-raw-data"
},
"Next": "ParallelTransform"
},
"ParallelTransform": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "TransformProjects",
"States": {
"TransformProjects": {
"Type": "Task",
"Resource": "arn:aws:states:::glue:startJobRun.sync",
"Parameters": { "JobName": "transform-project-data" },
"End": true
}
}
},
{
"StartAt": "TransformEngineers",
"States": {
"TransformEngineers": {
"Type": "Task",
"Resource": "arn:aws:states:::glue:startJobRun.sync",
"Parameters": { "JobName": "transform-engineer-data" },
"End": true
}
}
}
],
"Next": "DataQualityCheck"
},
"DataQualityCheck": {
"Type": "Task",
"Resource": "arn:aws:states:::glue:startJobRun.sync",
"Parameters": { "JobName": "data-quality-check" },
"End": true
}
}
}コスト最適化
DPU設定の最適化
AWS GlueのコストはDPU(Data Processing Unit)× 実行時間で決まります。
| ジョブタイプ | DPU範囲 | 料金(東京リージョン) |
|---|---|---|
| Spark ETL | 2〜100 DPU | $0.44/DPU-Hour |
| Python Shell | 0.0625〜1 DPU | $0.44/DPU-Hour |
| Streaming | 2〜100 DPU | $0.14/DPU-Hour |
コスト削減のベストプラクティス
- Auto Scaling有効化: Glue 3.0以降で利用可能。必要なDPUを自動調整
- ジョブブックマーク: 増分処理でデータ量を削減
- Parquet/ORC形式: カラムナーフォーマットで読み取りデータ量を削減
- パーティショニング: 日付やカテゴリでパーティション分割
- Python Shell: 小規模データ処理にはSparkではなくPython Shellを使用
- Flex実行: 優先度の低いバッチジョブにはFlex実行タイプ(最大60%コスト削減)
特にFlex実行タイプは、夜間バッチなど実行開始時刻に柔軟性がある場合に最大60%のコスト削減が可能です。SES案件でコスト最適化の提案ができれば、クライアントからの評価が上がります。
監視とトラブルシューティング
CloudWatch連携
import boto3
cloudwatch = boto3.client('cloudwatch')
# カスタムメトリクスの発行
cloudwatch.put_metric_data(
Namespace='SESBase/ETL',
MetricData=[
{
'MetricName': 'ProcessedRecords',
'Value': processed_count,
'Unit': 'Count',
'Dimensions': [
{'Name': 'JobName', 'Value': 'transform-project-data'},
{'Name': 'Environment', 'Value': 'production'},
]
}
]
)よくあるエラーと対処法
| エラー | 原因 | 対処法 |
|---|---|---|
| OutOfMemoryError | DPU不足 or データスキュー | DPU増加 or パーティション見直し |
| S3 Throttling | リクエスト集中 | プレフィックス分散 |
| Schema Mismatch | ソースデータの変更 | クローラー再実行 + スキーマ更新 |
| Job Timeout | 処理時間超過 | タイムアウト延長 or ジョブ分割 |
SES案件でのデータエンジニアリング需要
市場動向
データエンジニアリングスキルはSES市場で急速に需要が拡大しています。
| スキル | 需要レベル | 案件例 |
|---|---|---|
| AWS Glue + S3 | ★★★★★ | データレイク構築 |
| Glue + Athena | ★★★★★ | 分析基盤構築 |
| Glue + Redshift | ★★★★ | DWH構築・移行 |
| Step Functions連携 | ★★★★ | ETLオーケストレーション |
| Spark最適化 | ★★★ | パフォーマンスチューニング |
単価相場(2026年目安)
| レベル | 月額単価目安 | 求められるスキル |
|---|---|---|
| データ基盤初級 | 55〜70万円 | Glue基本操作・S3・Athena |
| データ基盤中級 | 70〜90万円 | ETL設計・コスト最適化・監視 |
| データ基盤上級 | 90〜120万円 | 大規模パイプライン・リアルタイム処理 |
まとめ
- データカタログとクローラーでメタデータ自動管理 — Athena/Redshiftから即クエリ可能
- PySparkでスケーラブルなETLジョブ — DynamicFrame/DataFrameの使い分け
- Data Qualityで品質チェックを自動化 — DQDLルールでパイプラインに組み込み
- Workflowで複数ジョブを依存管理 — Step Functionsとの連携も可能
- コスト最適化を徹底 — Flex実行・ジョブブックマーク・Auto Scalingの活用
AWS Glueを使ったデータパイプライン構築は、SES市場で高い需要と単価が見込めるスキルです。サーバーレスでインフラ管理の負担が少ない点も、スキル習得のハードルを下げてくれます。