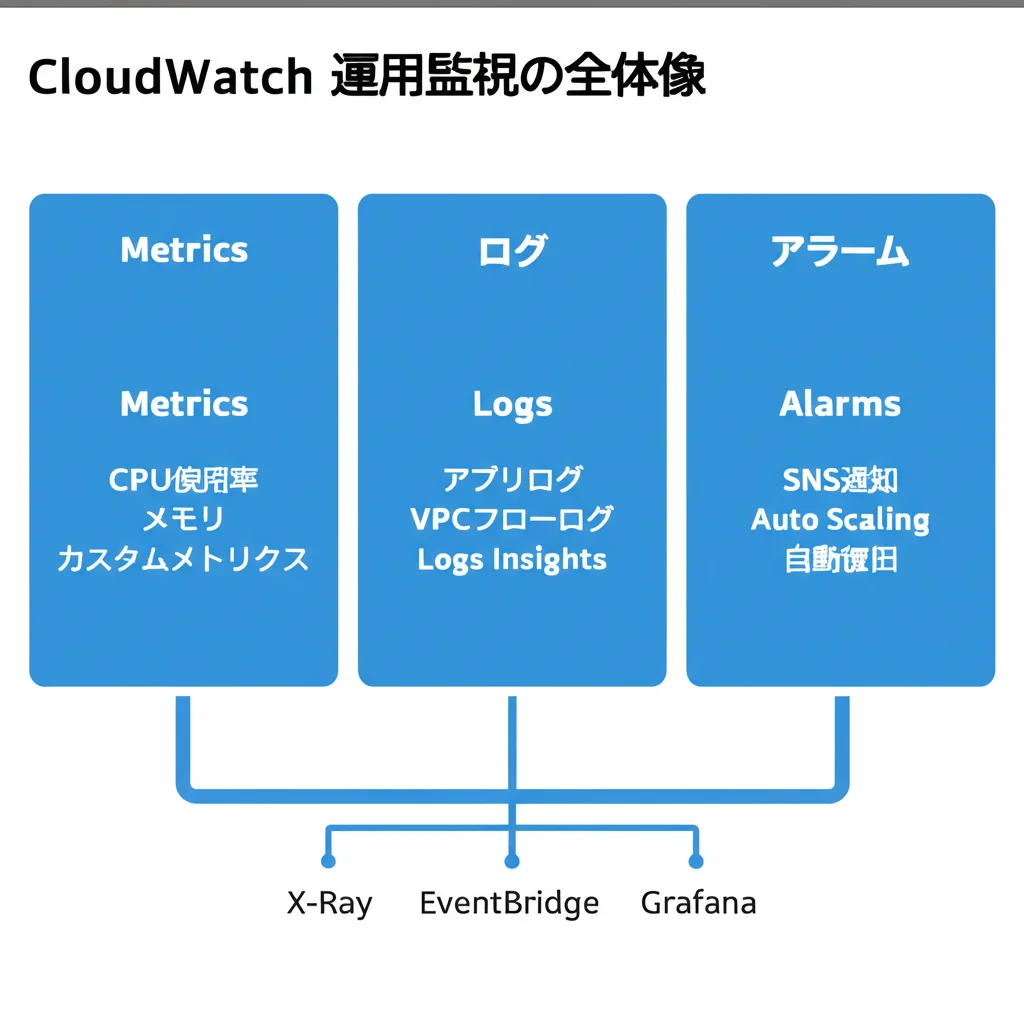
- AWS CloudWatchはインフラ・アプリケーション監視の中核。メトリクス・ログ・アラームの3本柱を押さえれば、運用フェーズの案件でも即戦力になれる。
- 「障害を検知して通知する」だけでなく、ダッシュボードで可視化しアクションにつなげる設計力がSES市場で高く評価される。月単価+5〜15万円の差も。
- CloudWatch単体にとどまらず、X-Ray・EventBridge・SNSとの連携を理解すれば「監視設計ができるエンジニア」として差別化が可能。
なぜSESエンジニアに運用監視スキルが必要なのか
クラウドインフラを構築できるエンジニアは増えていますが、構築した環境を安定運用するための監視設計までできる人材は依然として不足しています。SES市場では「作って終わり」ではなく、運用フェーズまで一貫して担当できるエンジニアの需要が高まっています。
AWSの監視基盤であるCloudWatchは、EC2やRDS、Lambda、ECSなどほぼすべてのAWSサービスと統合されています。CloudWatchを使いこなせるかどうかは、運用保守案件へのアサイン率に直結します。
IAM・セキュリティ設計がクラウドの「鍵と錠前」だとすれば、CloudWatchは「防犯カメラとセンサー」です。どんなに堅牢な設計をしても、異常を検知できなければ意味がありません。
SES案件の現場では、以下のようなシーンで監視スキルが求められます。
- 本番環境のリソース使用率モニタリングとキャパシティプランニング
- 障害発生時のアラート通知とエスカレーションフローの設計
- アプリケーションログの収集・分析・可視化
- コスト監視と異常課金の早期検知
CloudWatchの基本構成を理解する
メトリクス・ログ・アラームの3本柱
CloudWatchには大きく3つの機能領域があります。
| 機能 | 役割 | 具体例 |
|---|---|---|
| CloudWatch Metrics | 数値データの収集・蓄積 | CPU使用率、メモリ、リクエスト数 |
| CloudWatch Logs | ログの集約・検索・分析 | アプリログ、VPCフローログ、CloudTrailログ |
| CloudWatch Alarms | しきい値に基づく通知・自動アクション | CPU 80%超えでSNS通知、Auto Scaling発動 |
これらを組み合わせることで、「何が起きているか見える」→「異常を検知する」→「自動で対処する」という監視のサイクルを構築できます。
標準メトリクスとカスタムメトリクス
AWSサービスは多くの標準メトリクスを自動的にCloudWatchに送信します。たとえば、EC2であればCPU使用率、ディスクI/O、ネットワーク通信量などが何も設定しなくても記録されます。
ただし、メモリ使用率やディスク使用率は標準メトリクスに含まれません。これらを監視するにはCloudWatchエージェントをインストールしてカスタムメトリクスとして送信する必要があります。
# CloudWatch エージェントのインストール(Amazon Linux 2023)
sudo yum install -y amazon-cloudwatch-agent
# 設定ウィザードの実行
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizardカスタムメトリクスの設定例(JSON):
{
"metrics": {
"metrics_collected": {
"mem": {
"measurement": ["mem_used_percent"],
"metrics_collection_interval": 60
},
"disk": {
"measurement": ["disk_used_percent"],
"resources": ["/"],
"metrics_collection_interval": 60
}
}
}
}SES案件の面談で「EC2のメモリ監視はどう設定しますか?」と聞かれることは非常に多いため、この設定方法は確実に押さえておきましょう。
実務で使えるCloudWatch設計パターン
パターン1: アラーム設計とSNS通知
本番環境では、リソースの異常を即座に検知してチームに通知する仕組みが必須です。CloudWatch AlarmsとAmazon SNSを連携させるのが基本パターンです。
# CPU使用率が80%を5分間超えたらアラームを発報
aws cloudwatch put-metric-alarm \
--alarm-name "High-CPU-WebServer" \
--metric-name CPUUtilization \
--namespace AWS/EC2 \
--statistic Average \
--period 300 \
--threshold 80 \
--comparison-operator GreaterThanThreshold \
--evaluation-periods 2 \
--alarm-actions arn:aws:sns:ap-northeast-1:123456789012:ops-alerts \
--dimensions Name=InstanceId,Value=i-0123456789abcdef0アラーム設計のベストプラクティス:
- アラーム疲れを防ぐ: しきい値を厳しくしすぎると通知が多すぎて無視される。段階的な設定(Warning: 70%、Critical: 90%)が有効
- 複合アラーム(Composite Alarms): 複数のアラームをAND/OR条件で組み合わせ、誤報を減らす
- OK→ALARM→OKの遷移を記録し、障害のタイムラインを可視化する
パターン2: CloudWatch Logsによるログ集約と分析
アプリケーションログをCloudWatch Logsに集約することで、複数サーバーのログを一元管理できます。
Logs Insightsクエリを使えば、SQLライクな構文でログを分析できます。
-- 直近1時間のエラーログを発生頻度順に集計
fields @timestamp, @message
| filter @message like /ERROR/
| stats count(*) as errorCount by bin(5m)
| sort errorCount descECS/Fargate環境ではコンテナの標準出力が自動的にCloudWatch Logsに送信されるため、ログドライバーの設定さえ正しければ追加のエージェントは不要です。
パターン3: ダッシュボードによる可視化
CloudWatch Dashboardsを使えば、複数のメトリクスやログを1つの画面にまとめて可視化できます。運用チーム向けのオペレーションダッシュボードと、経営層向けのビジネスダッシュボードを分けて作成するのが一般的です。
オペレーションダッシュボードに含めるべき項目:
- EC2/ECSのCPU・メモリ使用率
- ALBのリクエスト数とレイテンシー
- RDSのコネクション数とレプリカ遅延
- Lambda関数のエラー率と実行時間
- 直近のアラーム一覧
ダッシュボードはCloudFormationやTerraformでコード管理することで、環境間の一貫性を保てます。
CloudWatchと連携する主要サービス
CloudWatch単体ではカバーしきれない領域を補完する、重要な連携サービスを紹介します。
AWS X-Ray — 分散トレーシング
マイクロサービスやサーバーレスアーキテクチャでは、1つのリクエストが複数のサービスを横断します。X-Rayを使えば、リクエストの全経路をトレースIDで追跡し、ボトルネックを特定できます。
Lambda関数にX-Rayトレーシングを有効化するのはワンクリックで済むため、導入コストは低い一方、トラブルシューティング時の効果は絶大です。
Amazon EventBridge — イベント駆動の自動化
CloudWatch Alarmsの通知先としてSNSだけでなく、EventBridgeを利用することで、より柔軟な自動化が可能になります。
- 障害検知時にLambda関数を起動して自動復旧
- 特定のAPI呼び出し(CloudTrail連携)をトリガーにSlack通知
- コスト異常検知時にEC2インスタンスを自動停止
Amazon Managed Grafana — 高度な可視化
CloudWatchのダッシュボードでは物足りない場合、Amazon Managed Grafanaを使えば、より高度でカスタマイズ性の高い可視化が実現できます。CloudWatch以外のデータソース(Prometheus、OpenSearchなど)も統合できるため、ハイブリッド監視環境にも対応できます。
監視スキルが単価に与える影響
SES市場において、監視・運用設計のスキルは安定した案件獲得に直結します。
| スキルレベル | 想定単価(月額) | 主な案件内容 |
|---|---|---|
| 基礎監視(アラーム設定・ログ確認) | 45〜60万円 | 運用保守、障害一次対応 |
| 監視設計(ダッシュボード・ログ分析) | 60〜75万円 | インフラ構築・監視基盤設計 |
| 統合監視(X-Ray・Grafana・自動復旧) | 75〜95万円 | SRE・プラットフォームエンジニア |
特に近年はSRE(Site Reliability Engineering) の考え方がSES案件にも浸透しており、SLI/SLO設計やエラーバジェットの運用経験があると、月額90万円以上の高単価案件も狙えます。
CloudWatch・運用監視スキルを効率的に学ぶロードマップ
ステップ1: CloudWatchの基本操作を体験する(1〜2週間)
AWSの無料枠を活用し、以下を実際に手を動かして設定してみましょう。
- EC2インスタンスの標準メトリクスをCloudWatchコンソールで確認
- CloudWatchエージェントでメモリ・ディスクのカスタムメトリクスを送信
- CPU使用率のアラームを作成し、SNSでメール通知を受け取る
- 簡単なダッシュボードを作成してメトリクスを可視化
ステップ2: ログ管理とInsightsクエリを習得する(1〜2週間)
CloudWatch Logsにアプリケーションログを送信し、Logs Insightsで分析する流れを実践します。
- Webアプリのアクセスログ・エラーログをCloudWatch Logsに送信
- Logs Insightsでエラー集計・レスポンスタイム分析
- メトリクスフィルターでログからカスタムメトリクスを生成
- サブスクリプションフィルターでS3やLambdaにログを転送
ステップ3: 実践的な監視基盤を構築する(2〜4週間)
VPC、ECS、Lambdaを組み合わせた環境で、統合的な監視基盤を設計・構築します。
- マルチサービス環境のオペレーションダッシュボード
- X-Rayによる分散トレーシングの導入
- EventBridgeを使った障害自動復旧フローの構築
- コスト監視とBudgetsアラームの設定
まとめ
AWS CloudWatch・運用監視は、SESエンジニアが「構築もできて運用もできる」オールラウンダーとして評価されるための重要スキルです。
- CloudWatchはメトリクス・ログ・アラームの3本柱。まずはこの基本構成を正確に理解する
- カスタムメトリクス(メモリ・ディスク)の設定は面談頻出。CloudWatchエージェントの導入手順を押さえる
- アラーム疲れを防ぐ設計と、ダッシュボードによる可視化でチームの運用品質を向上させる
- X-Ray・EventBridge・Grafanaとの連携で、監視スキルの幅を広げれば高単価案件が狙える
シリーズを通じて学んできたECS/Fargate、IaC、VPC、IAMの知識と組み合わせることで、AWSインフラの設計から構築・運用まで一気通貫で担当できるエンジニアを目指しましょう。
出典・参考: