
- ドライラン・サンドボックス実行でエージェントの動作を本番影響なく検証できる
- セッションログの構造化分析で「なぜその判断をしたか」を遡及的にトレースできる
- 回帰テストとCI連携でスキル変更時の品質劣化を自動検知し、SES現場の信頼性を担保する
「エージェントが突然おかしな動きをし始めたが、何が原因かわからない」——AIエージェントを業務に導入していると、必ずこの壁にぶつかります。
従来のソフトウェアと違い、AIエージェントは非決定的な出力を返します。同じ入力でも異なる結果が出ることがあり、従来のユニットテストだけでは品質を保証できません。
この記事では、OpenClawエージェントのテスト戦略とデバッグ手法を体系的に解説します。ドライランによる安全な検証から、セッションログの分析、プロンプトの回帰テスト、CI/CDパイプラインへの組み込みまで、SES現場で使える実践的なテクニックを紹介します。
AIエージェントのテストが難しい3つの理由
非決定性:同じ入力でも出力が変わる
従来のプログラムなら f(x) = y が保証されますが、LLMベースのエージェントは確率的に動作します。同じプロンプトでも、実行のたびに異なる文面・判断・ツール呼び出し順序になる可能性があります。
副作用の連鎖:外部システムへの影響
OpenClawエージェントはSlack投稿、GitHub PR作成、メール送信など実世界への副作用を持ちます。テスト中に意図せず本番環境に影響を与えるリスクがあります。
コンテキスト依存:メモリと状態による動作変化
メモリ管理で解説した通り、エージェントはMEMORY.mdやセッション履歴に基づいて判断を変えます。テスト時と本番時でコンテキストが異なれば、同じスキルでも違う動作をします。
テスト戦略の全体像
OpenClawエージェントのテストは、以下の4層で設計します。
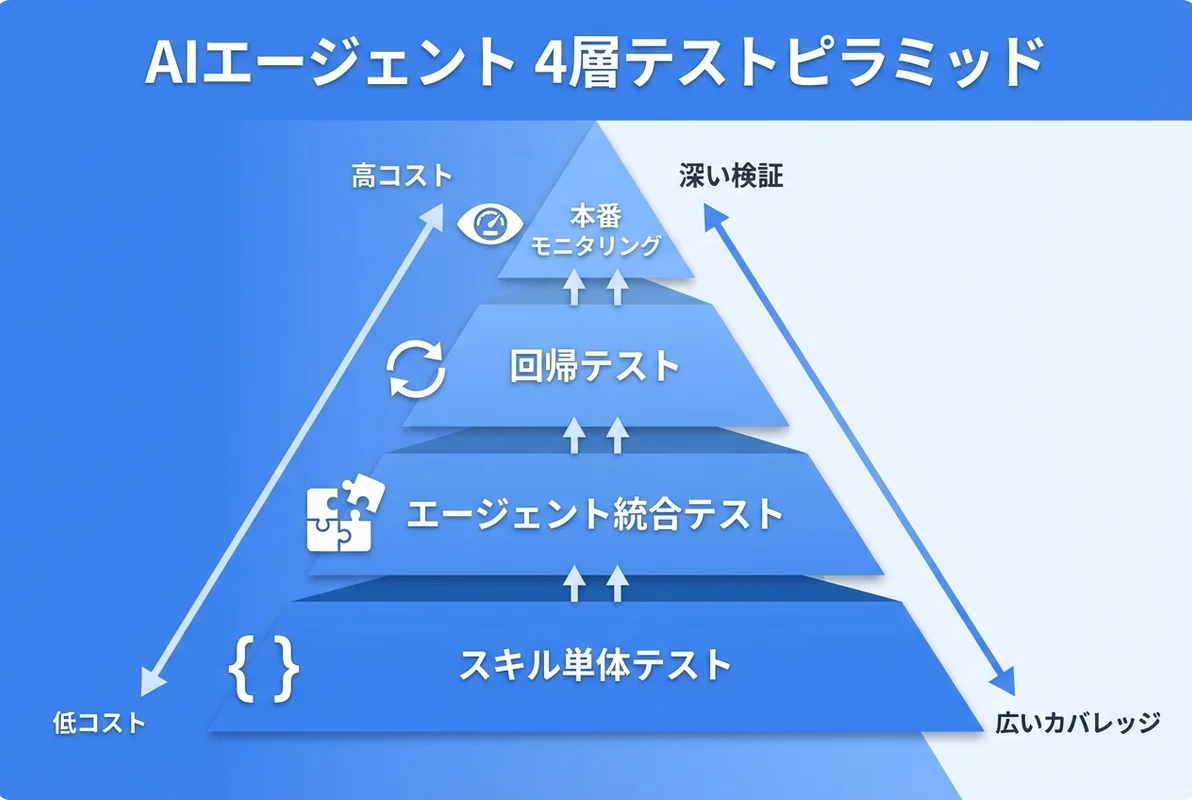
レイヤー1:スキル単体テスト
個々のスキル(SKILL.md + スクリプト)が正しく動作するかを検証します。
# スキルのスクリプトを直接実行してテスト
cd ~/.openclaw/skills/my-skill/scripts/
echo '{"input": "テストデータ"}' | python3 process.py
# 期待する出力パターンをチェック
echo '{"input": "テストデータ"}' | python3 process.py | jq '.status' | grep -q "success"スキル内のスクリプトは純粋な関数として設計すると、テストが格段に楽になります。外部API呼び出しはモック可能な構造にしておきましょう。
レイヤー2:エージェント統合テスト(ドライラン)
エージェント全体の動作を、副作用なしで検証する方法です。
# cronジョブをドライランで実行
openclaw cron run <job-name> --dry-run
# テスト用ワークスペースで隔離実行
openclaw session start --workspace test-workspaceドライランでは、エージェントが「何をしようとしたか」のログが出力されます。実際のSlack投稿やGitHub操作は行われないため、安全に動作確認できます。
レイヤー3:回帰テスト
スキルやプロンプトを変更した際に、既存の動作が壊れていないかを検証します。
# テストケースファイル: tests/test-cases.jsonl
{"scenario": "日次レポート生成", "input": "GA4データ取得", "expect_contains": ["PV", "セッション"]}
{"scenario": "記事要約", "input": "3000字のブログ記事", "expect_max_length": 500}#!/bin/bash
# scripts/regression-test.sh
PASS=0; FAIL=0
while IFS= read -r tc; do
scenario=$(echo "$tc" | jq -r '.scenario')
expected=$(echo "$tc" | jq -r '.expect_contains[]' 2>/dev/null)
# エージェントの出力を取得
output=$(openclaw run --input "$(echo "$tc" | jq -r '.input')" 2>&1)
# 期待するキーワードが含まれるか検証
all_found=true
for keyword in $expected; do
if ! echo "$output" | grep -q "$keyword"; then
echo "❌ FAIL: $scenario — '$keyword' not found"
all_found=false
FAIL=$((FAIL + 1))
break
fi
done
if $all_found; then
echo "✅ PASS: $scenario"
PASS=$((PASS + 1))
fi
done < tests/test-cases.jsonl
echo "Results: $PASS passed, $FAIL failed"
[ "$FAIL" -eq 0 ] || exit 1レイヤー4:本番モニタリング
テストを通過したエージェントでも、本番環境では予期せぬ動作をすることがあります。モニタリングとアラート通知設計と組み合わせて、継続的に品質を監視しましょう。
デバッグ手法:セッションログの読み方
セッションログの取得と構造
OpenClawは各セッションの実行ログを保存しています。問題が発生した際は、まずログを確認します。
# 最新セッションのログを確認
ls -lt ~/.openclaw/sessions/ | head -5
# 特定セッションのログを読む
cat ~/.openclaw/sessions/<session-id>/log.jsonl | jq '.'ログの各エントリには以下の情報が含まれます:
- タイムスタンプ: いつ実行されたか
- ツール呼び出し: どのツールをどのパラメータで呼んだか
- モデル応答: LLMがどのような判断をしたか
- エラー情報: 失敗した場合のエラー詳細
ツール呼び出しチェーンのトレース
エージェントの判断過程を追跡する最も効果的な方法は、ツール呼び出しの連鎖を時系列で見ることです。
# ツール呼び出しだけを抽出
cat ~/.openclaw/sessions/<session-id>/log.jsonl \
| jq 'select(.type == "tool_call") | {tool: .name, params: .params | keys}' 「なぜこのツールを呼んだのか」「なぜこの順序になったのか」を理解することで、プロンプトやスキルの改善ポイントが見えてきます。
よくあるデバッグパターン
パターン1: ツールが呼ばれない
エージェントがスキルを使わずにテキストだけで回答してしまうケース。SKILL.mdのdescriptionが不明確な場合に発生しやすいです。
# ❌ 悪い例:曖昧なdescription
description: データを処理するスキル
# ✅ 良い例:具体的なトリガー条件を記載
description: GA4のアクセスデータを取得し、日次レポートを生成する。
Use when: ユーザーがGA4データやアクセス解析を求めた場合。パターン2: 無限ループ
エージェントが同じ操作を繰り返すケース。セッション管理の設計が不適切な場合や、エラーハンドリングの欠如が原因です。
# ログからツール呼び出し回数を集計
cat log.jsonl | jq -r 'select(.type=="tool_call") | .name' | sort | uniq -c | sort -rn
# 例: 同じツールが50回以上呼ばれていたらループの可能性大パターン3: コンテキスト溢れ
長いセッションでコンテキストウィンドウが埋まり、古い指示が忘れられるケース。タスクをサブエージェントに分割して対処します。
プロンプト品質のテスト手法
A/Bテストによるプロンプト最適化
AGENTS.mdやSOUL.mdの変更が出力品質に与える影響を定量的に測定します。
#!/bin/bash
# プロンプトA/Bテスト
PROMPT_A="agents-v1.md"
PROMPT_B="agents-v2.md"
SCENARIOS=("日次レポートを作成して" "記事を要約して" "バグを修正して")
for scenario in "${SCENARIOS[@]}"; do
echo "=== Scenario: $scenario ==="
# Prompt Aで実行
cp "$PROMPT_A" AGENTS.md
output_a=$(openclaw run --input "$scenario" 2>&1 | tail -20)
# Prompt Bで実行
cp "$PROMPT_B" AGENTS.md
output_b=$(openclaw run --input "$scenario" 2>&1 | tail -20)
echo "A: $(echo "$output_a" | wc -c) chars"
echo "B: $(echo "$output_b" | wc -c) chars"
doneチェックリストベースの品質評価
出力が一定の品質基準を満たしているかを自動チェックします。
# 記事生成の品質チェック
validate_article_output() {
local output="$1"
local score=0
# H2見出しが3つ以上あるか
h2_count=$(echo "$output" | grep -c '^## ')
[ "$h2_count" -ge 3 ] && score=$((score + 1))
# 文字数が3000字以上か
char_count=${#output}
[ "$char_count" -ge 3000 ] && score=$((score + 1))
# 内部リンクが含まれるか
link_count=$(echo "$output" | grep -co '/articles/')
[ "$link_count" -ge 3 ] && score=$((score + 1))
echo "品質スコア: $score/3"
[ "$score" -ge 3 ] && return 0 || return 1
}CI/CDパイプラインへの組み込み
GitHub Actionsでの自動テスト
GitHub連携と組み合わせ、PRマージ前にエージェント品質を自動検証します。
# .github/workflows/agent-test.yml
name: Agent Quality Check
on:
pull_request:
paths:
- '.openclaw/**'
- 'skills/**'
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: スキルバリデーション
run: |
# 全SKILL.mdの構文チェック
for skill_md in skills/*/SKILL.md; do
echo "Checking $skill_md..."
grep -q '^name:' "$skill_md" || { echo "❌ name missing"; exit 1; }
grep -q '^description:' "$skill_md" || { echo "❌ description missing"; exit 1; }
done
echo "✅ All skills valid"
- name: AGENTS.md構文チェック
run: |
[ -f .openclaw/AGENTS.md ] || { echo "❌ AGENTS.md missing"; exit 1; }
grep -q '## Safety' .openclaw/AGENTS.md || echo "⚠️ Safety section missing"
echo "✅ AGENTS.md structure OK"
- name: 回帰テスト実行
run: bash scripts/regression-test.shステージング環境でのスモークテスト
本番デプロイ前に、ステージング環境でエージェントの主要機能を検証します。
#!/bin/bash
# scripts/smoke-test.sh
echo "🔥 スモークテスト開始"
# 1. エージェントが起動するか
openclaw gateway status > /dev/null 2>&1
[ $? -eq 0 ] && echo "✅ Gateway起動OK" || { echo "❌ Gateway起動失敗"; exit 1; }
# 2. スキルが読み込まれるか
skill_count=$(openclaw skills list 2>/dev/null | wc -l)
[ "$skill_count" -gt 0 ] && echo "✅ スキル読み込みOK ($skill_count個)" || echo "⚠️ スキル0個"
# 3. cronジョブが設定されているか
cron_count=$(openclaw cron list 2>/dev/null | wc -l)
echo "📋 cronジョブ: $cron_count個"
echo "🔥 スモークテスト完了"SES現場でのテスト運用ベストプラクティス
段階的ロールアウト
エージェントの変更は一度に全環境へ適用せず、段階的に展開します。
- 開発環境: テスト用ワークスペースで動作確認
- ステージング: 本番データのサブセットで検証
- カナリアリリース: 本番の一部タスクにのみ適用
- 全面展開: 問題なければ全タスクに適用
テストのコスト最適化
AIエージェントのテストはAPI呼び出しコストがかかります。コスト最適化の考え方を適用し、テストコストを抑えます。
- ユニットテスト: スクリプト単体テストはAPI不要(コストゼロ)
- 統合テスト: 低コストモデル(Claude Haiku等)でドライラン
- 回帰テスト: 変更されたスキルに関連するテストケースのみ実行
- 本番モニタリング: 既存のセッションログを活用(追加コスト最小)
エラーパターンのナレッジベース化
デバッグで発見した問題と解決策は、チーム全体で共有可能な形で記録しておきます。
<!-- debug-knowledge.md -->
## よくあるエラーと対処法
### E001: ツール呼び出しタイムアウト
- 原因: 外部APIのレスポンス遅延
- 対処: timeoutMsパラメータを調整(デフォルト10000→30000)
- 参考: [ワークフロー自動化ガイド](/articles/openclaw-workflow-automation-guide/)
### E002: コンテキスト長超過
- 原因: MEMORY.mdの肥大化
- 対処: 定期的なメモリ整理をcronジョブ化
- 参考: [メモリ管理ガイド](/articles/openclaw-memory-management-guide/)まとめ:テスト文化がエージェント品質を決める
OpenClawエージェントのテストは、従来のソフトウェアテストとは異なるアプローチが必要です。本記事で紹介した4層テスト戦略を導入することで、エージェントの出力品質を安定的に保証できます。
今日から始められるアクション:
- セッションログの確認習慣をつける — 問題が起きたらまずログを見る
- スキルのスクリプトにテストを追加 — 純粋関数として設計し、ユニットテスト可能にする
- 変更時の回帰テストを自動化 — CI/CDに品質チェックを組み込む
- デバッグ知見をナレッジベース化 — 同じ問題に二度悩まない仕組みを作る
AIエージェントは「作って終わり」ではなく、継続的にテスト・改善するものです。テスト文化を根付かせることが、SES現場でのAI活用を成功に導く鍵となります。
OpenClaw 完全攻略シリーズの他の記事:
- Ep.1: OpenClaw使い方入門
- Ep.2: スキル開発ガイド
- Ep.3: マーケティング自動化
- Ep.4: GitHub連携とPR自動化
- Ep.5: マルチエージェント設計
- Ep.6: cronジョブとスケジュール自動化
- Ep.7: ブラウザ自動化
- Ep.8: コスト最適化とモデル選定
- Ep.9: ワークスペース設計
- Ep.10: セッション管理とサブエージェント
- Ep.11: モニタリングとアラート通知
出典・参考リンク:





