
- OpenClawのスキルシステムとMCP連携で、社内ドキュメントを自動検索するRAGナレッジベースを構築できる
- Notion・Slack・Google Drive・GitHubなど複数のデータソースを統合し、一つのチャットインターフェースで横断検索が可能
- ベクトルDBの選定からチャンク分割・埋め込み生成・検索精度チューニングまで、実装の全工程をカバー
「社内のドキュメントが散乱していて、必要な情報を見つけるのに毎回30分かかる…」 「新しいメンバーが入るたびに同じ質問に答えている…ナレッジが属人化している…」
組織の知識を効率的に活用することは、生産性向上の鍵です。OpenClawとRAG(Retrieval-Augmented Generation)を組み合わせれば、社内のあらゆる情報ソースを統合したAIナレッジベースを構築できます。Slackで質問するだけで、関連ドキュメントを自動検索し、正確な回答を返すアシスタントが作れるのです。
この記事では、OpenClawでRAGナレッジベースを構築する方法を、アーキテクチャ設計から実装・運用まで体系的に解説します。
- RAGの基本概念とOpenClawでの実装アーキテクチャ
- ベクトルデータベースの選定とセットアップ方法
- ドキュメントのチャンク分割・埋め込み生成のベストプラクティス
- Notion・Slack・Google Drive等のデータソース統合手順
- 検索精度の改善テクニックとハルシネーション対策
RAGとは何か — なぜOpenClawに必要か
RAGの基本概念
RAG(Retrieval-Augmented Generation)は、LLMの回答生成プロセスに外部知識の検索を組み込むアーキテクチャです。通常のLLMは学習データに基づいて回答しますが、RAGでは以下のステップで精度を向上させます。
- 質問の受信: ユーザーからの質問をベクトル化
- 関連文書の検索: ベクトルDBから類似度の高いドキュメントを取得
- コンテキスト付き生成: 検索結果をLLMのプロンプトに含めて回答生成
- ソース引用: 回答の根拠となったドキュメントを明示
OpenClawでRAGを構築するメリット
OpenClawは、RAGナレッジベースの構築に以下の利点を持っています。
| 特徴 | メリット |
|---|---|
| マルチチャネル対応 | Slack・Discord・Web等から同一ナレッジベースに質問可能 |
| スキルシステム | RAG検索をスキルとして実装し、他の機能と組み合わせ可能 |
| MCP連携 | MCPサーバー経由でベクトルDBやデータソースに接続 |
| マルチモデル | 埋め込み生成と回答生成で異なるモデルを使い分け可能 |
| メモリシステム | 過去の質問と回答を記憶し、コンテキストを維持 |
| Cronジョブ | ドキュメントの定期的な再インデックスを自動実行 |
アーキテクチャ設計
全体構成図
OpenClawベースのRAGナレッジベースは、以下のコンポーネントで構成されます。
┌─────────────────────────────────────────────────┐
│ OpenClaw Agent │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────────┐ │
│ │ Slack │ │ Discord │ │ Web Chat │ │
│ │ Channel │ │ Channel │ │ Channel │ │
│ └─────┬─────┘ └────┬─────┘ └──────┬───────┘ │
│ │ │ │ │
│ └──────────────┼───────────────┘ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ RAG Skill │ │
│ │ (SKILL.md) │ │
│ └────────┬────────┘ │
│ │ │
│ ┌───────────┼───────────┐ │
│ ▼ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Query │ │ Retrieval│ │ Response │ │
│ │ Analyzer │ │ Engine │ │ Generator│ │
│ └──────────┘ └─────┬────┘ └──────────┘ │
│ │ │
└──────────────────────┼───────────────────────────┘
│
┌────────────┼────────────┐
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ Vector │ │ Notion │ │ Google │
│ DB │ │ API │ │ Drive │
│(Qdrant) │ │ │ │ │
└──────────┘ └──────────┘ └──────────┘ベクトルデータベースの選定
RAGの心臓部であるベクトルDBの選定は重要です。OpenClawとの連携を考慮した比較を行います。
| ベクトルDB | 特徴 | コスト | OpenClaw連携 |
|---|---|---|---|
| Qdrant | 高性能・Rust製・セルフホスト可能 | 無料(OSS) | MCP経由 |
| Pinecone | フルマネージド・スケーラブル | 従量課金 | REST API |
| Weaviate | GraphQL対応・ハイブリッド検索 | 無料(OSS) | MCP経由 |
| pgvector | PostgreSQL拡張・既存DBと統合 | 無料(OSS) | SQL経由 |
| Chroma | Python特化・シンプル | 無料(OSS) | REST API |
小〜中規模のチームにはQdrant(セルフホスト)またはpgvector(既存DBと統合)を推奨します。
OpenClawスキルとしてRAGを実装する
RAGスキルのディレクトリ構造
~/.openclaw/skills/rag-knowledge-base/
├── SKILL.md # スキル定義
├── scripts/
│ ├── index-documents.sh # ドキュメントインデックス
│ ├── search.sh # ベクトル検索
│ └── reindex-cron.sh # 定期再インデックス
└── references/
├── chunking-strategies.md # チャンク分割戦略
└── prompt-templates.md # RAGプロンプトテンプレートSKILL.md の定義
---
name: rag-knowledge-base
description: >
社内ドキュメントをベクトル検索し、質問に対して関連情報を
検索・引用付きで回答する。Notion・Slack・Google Drive・
GitHubのドキュメントを統合インデックスする。
---
# RAG Knowledge Base Skill
## トリガー条件
以下のいずれかに該当する場合にこのスキルを使用する:
- ユーザーが社内情報について質問した
- 「ナレッジ」「ドキュメント」「手順」「マニュアル」に関する質問
- 「〜のやり方」「〜はどこに書いてある」系の質問
## 検索フロー
### 1. クエリ分析
ユーザーの質問を分析し、検索クエリを最適化する。
- 質問の意図を抽出(手順確認/仕様確認/トラブルシューティング)
- 検索キーワードを3〜5個生成
- 必要に応じてクエリを複数に分割
### 2. ベクトル検索の実行
```bash
# Qdrant APIでベクトル検索
scripts/search.sh "検索クエリ" --top-k 5 --score-threshold 0.753. 回答生成ルール
- 検索結果をコンテキストとしてLLMに渡す
- 必ず情報ソース(ドキュメント名・URL)を引用する
- 検索結果に該当情報がない場合は「見つかりませんでした」と正直に回答
- 推測で補完しない(ハルシネーション防止)
4. 回答フォーマット
[回答本文]
📚 参考ドキュメント:
- [ドキュメント名](URL) — 関連セクション名
- [ドキュメント名](URL) — 関連セクション名インデックス更新
Cronジョブ rag-reindex で毎日3:00 JSTに自動更新。
手動実行: scripts/index-documents.sh --source all
### ベクトル検索スクリプトの実装
```bash
#!/bin/bash
# scripts/search.sh — ベクトル検索実行
set -euo pipefail
QDRANT_URL="${QDRANT_URL:-http://localhost:6333}"
COLLECTION="knowledge_base"
OPENAI_API_KEY="${OPENAI_API_KEY}"
TOP_K="${2:-5}"
THRESHOLD="${3:-0.75}"
QUERY="$1"
# 1. クエリをベクトル化(OpenAI Embeddings API)
EMBEDDING=$(curl -s https://api.openai.com/v1/embeddings \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d "{
\"model\": \"text-embedding-3-small\",
\"input\": \"$QUERY\"
}" | jq -r '.data[0].embedding')
# 2. Qdrantでベクトル検索
RESULTS=$(curl -s "$QDRANT_URL/collections/$COLLECTION/points/search" \
-H "Content-Type: application/json" \
-d "{
\"vector\": $EMBEDDING,
\"limit\": $TOP_K,
\"score_threshold\": $THRESHOLD,
\"with_payload\": true
}")
# 3. 結果をフォーマットして出力
echo "$RESULTS" | jq -r '.result[] | "---\nScore: \(.score)\nSource: \(.payload.source)\nTitle: \(.payload.title)\nURL: \(.payload.url)\nContent: \(.payload.content)\n"'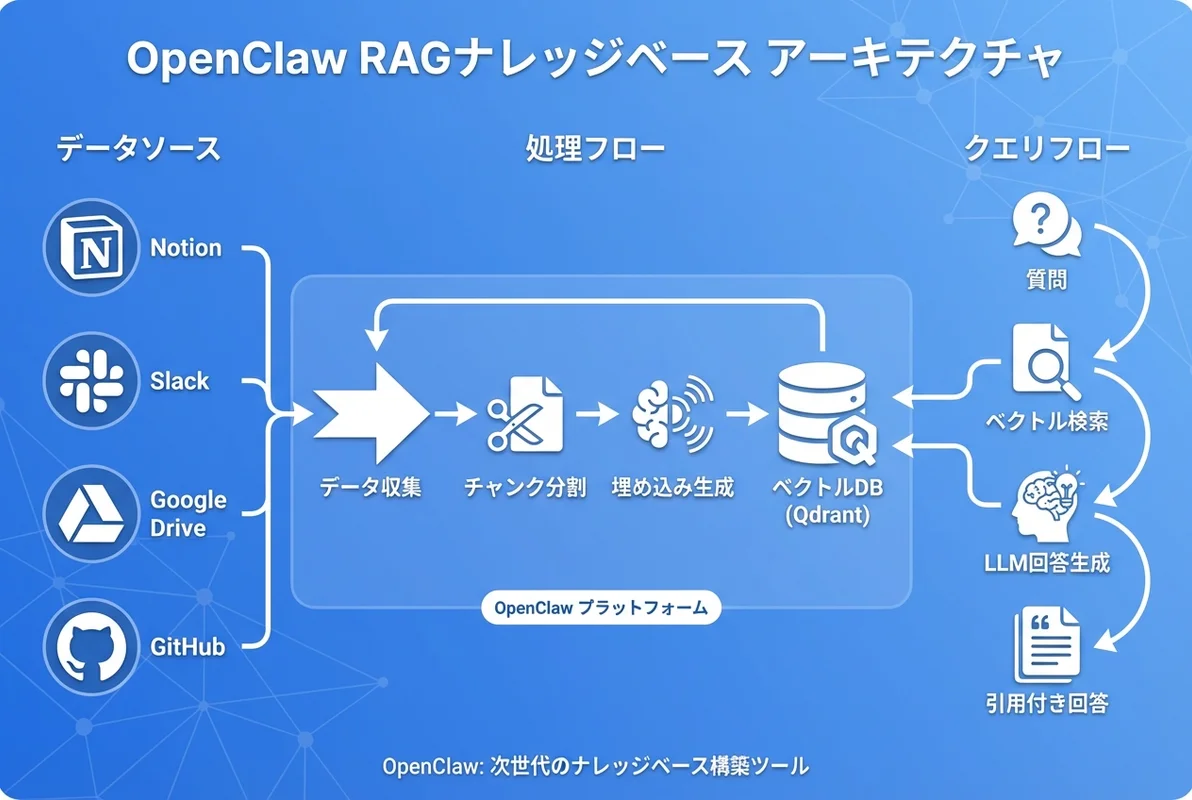
ドキュメントのインデックス作成
チャンク分割戦略
ドキュメントを適切なサイズに分割(チャンキング)することは、RAGの精度に直結します。
| 戦略 | チャンクサイズ | 適用場面 |
|---|---|---|
| 固定サイズ | 500〜1000トークン | 汎用(最もシンプル) |
| 段落ベース | 段落単位 | 構造化された文書 |
| 見出しベース | セクション単位 | マニュアル・ドキュメント |
| セマンティック | 意味のまとまり単位 | 技術文書・FAQ |
| オーバーラップ付き | 固定 + 前後50トークン重複 | 文脈の切断を防ぎたい場合 |
OpenClawでのインデックススクリプト例:
#!/usr/bin/env python3
# scripts/index-documents.py — ドキュメントインデックス作成
import os
import json
import hashlib
from typing import Generator
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance, PointStruct
import openai
from notion_client import Client as NotionClient
# 設定
QDRANT_URL = os.environ.get("QDRANT_URL", "http://localhost:6333")
COLLECTION = "knowledge_base"
CHUNK_SIZE = 800 # トークン数
CHUNK_OVERLAP = 100
EMBEDDING_MODEL = "text-embedding-3-small"
EMBEDDING_DIM = 1536
# クライアント初期化
qdrant = QdrantClient(url=QDRANT_URL)
openai_client = openai.OpenAI()
notion = NotionClient(auth=os.environ["NOTION_TOKEN"])
def create_collection():
"""コレクション作成(存在しない場合)"""
collections = [c.name for c in qdrant.get_collections().collections]
if COLLECTION not in collections:
qdrant.create_collection(
collection_name=COLLECTION,
vectors_config=VectorParams(
size=EMBEDDING_DIM,
distance=Distance.COSINE,
),
)
print(f"Collection '{COLLECTION}' created")
def chunk_text(text: str, source: str, title: str, url: str) -> Generator:
"""テキストをオーバーラップ付きチャンクに分割"""
words = text.split()
for i in range(0, len(words), CHUNK_SIZE - CHUNK_OVERLAP):
chunk_words = words[i:i + CHUNK_SIZE]
if len(chunk_words) < 50: # 短すぎるチャンクはスキップ
continue
chunk_text = " ".join(chunk_words)
chunk_id = hashlib.md5(f"{source}:{title}:{i}".encode()).hexdigest()
yield {
"id": chunk_id,
"text": chunk_text,
"source": source,
"title": title,
"url": url,
"chunk_index": i,
}
def generate_embeddings(texts: list[str]) -> list[list[float]]:
"""バッチで埋め込みベクトル生成"""
response = openai_client.embeddings.create(
model=EMBEDDING_MODEL,
input=texts,
)
return [item.embedding for item in response.data]
def index_notion_pages(database_id: str):
"""Notionデータベースのページをインデックス"""
pages = notion.databases.query(database_id=database_id)
all_chunks = []
for page in pages["results"]:
title = page["properties"]["Name"]["title"][0]["plain_text"]
url = page["url"]
# ページ本文を取得
blocks = notion.blocks.children.list(block_id=page["id"])
content = extract_text_from_blocks(blocks["results"])
for chunk in chunk_text(content, "notion", title, url):
all_chunks.append(chunk)
# バッチで埋め込み生成(100件ずつ)
batch_size = 100
for i in range(0, len(all_chunks), batch_size):
batch = all_chunks[i:i + batch_size]
texts = [c["text"] for c in batch]
embeddings = generate_embeddings(texts)
points = [
PointStruct(
id=c["id"],
vector=emb,
payload={
"content": c["text"],
"source": c["source"],
"title": c["title"],
"url": c["url"],
"chunk_index": c["chunk_index"],
},
)
for c, emb in zip(batch, embeddings)
]
qdrant.upsert(collection_name=COLLECTION, points=points)
print(f"Indexed {len(points)} chunks from Notion (batch {i // batch_size + 1})")
def extract_text_from_blocks(blocks: list) -> str:
"""Notionブロックからテキストを抽出"""
texts = []
for block in blocks:
block_type = block["type"]
if block_type in ("paragraph", "heading_1", "heading_2", "heading_3",
"bulleted_list_item", "numbered_list_item"):
rich_texts = block[block_type].get("rich_text", [])
text = "".join(rt["plain_text"] for rt in rich_texts)
if text:
texts.append(text)
return "\n".join(texts)
if __name__ == "__main__":
import sys
create_collection()
source = sys.argv[1] if len(sys.argv) > 1 else "all"
if source in ("all", "notion"):
database_id = os.environ["NOTION_DATABASE_ID"]
index_notion_pages(database_id)
print("Indexing complete!")複数データソースの統合
NotionだけでなくSlack・Google Drive・GitHubも統合インデックスします。
# Slack履歴のインデックス
def index_slack_messages(channel_ids: list[str], days: int = 30):
"""Slackチャンネルの直近メッセージをインデックス"""
from slack_sdk import WebClient
import time
slack = WebClient(token=os.environ["SLACK_BOT_TOKEN"])
oldest = str(int(time.time()) - days * 86400)
all_chunks = []
for channel_id in channel_ids:
result = slack.conversations_history(
channel=channel_id,
oldest=oldest,
limit=1000,
)
channel_info = slack.conversations_info(channel=channel_id)
channel_name = channel_info["channel"]["name"]
for msg in result["messages"]:
if msg.get("subtype"): # システムメッセージをスキップ
continue
text = msg.get("text", "")
if len(text) < 50: # 短すぎるメッセージをスキップ
continue
# スレッドの返信も取得
thread_ts = msg.get("thread_ts")
if thread_ts:
replies = slack.conversations_replies(
channel=channel_id,
ts=thread_ts,
)
thread_text = "\n".join(
r["text"] for r in replies["messages"]
if not r.get("subtype")
)
text = thread_text
ts = msg["ts"]
url = f"https://slack.com/archives/{channel_id}/p{ts.replace('.', '')}"
for chunk in chunk_text(text, "slack", f"#{channel_name}", url):
all_chunks.append(chunk)
# バッチインデックス
index_chunks(all_chunks)
print(f"Indexed {len(all_chunks)} chunks from Slack")
# Google Driveのインデックス
def index_google_drive(folder_id: str):
"""Google Driveフォルダ内のドキュメントをインデックス"""
from google.oauth2 import service_account
from googleapiclient.discovery import build
import io
credentials = service_account.Credentials.from_service_account_file(
os.environ["GOOGLE_SERVICE_ACCOUNT_KEY"],
scopes=["https://www.googleapis.com/auth/drive.readonly"],
)
drive = build("drive", "v3", credentials=credentials)
results = drive.files().list(
q=f"'{folder_id}' in parents and trashed=false",
fields="files(id, name, mimeType, webViewLink)",
).execute()
all_chunks = []
for file in results.get("files", []):
if file["mimeType"] == "application/vnd.google-apps.document":
# Google Docsをプレーンテキストとしてエクスポート
content = drive.files().export(
fileId=file["id"],
mimeType="text/plain",
).execute().decode("utf-8")
for chunk in chunk_text(content, "gdrive", file["name"], file["webViewLink"]):
all_chunks.append(chunk)
index_chunks(all_chunks)
print(f"Indexed {len(all_chunks)} chunks from Google Drive")検索精度の改善テクニック
ハイブリッド検索の実装
ベクトル検索だけでなく、キーワード検索(BM25)と組み合わせるハイブリッド検索で精度を向上させます。
def hybrid_search(query: str, top_k: int = 5) -> list:
"""ベクトル検索 + キーワード検索のハイブリッド"""
# 1. ベクトル検索
query_embedding = generate_embeddings([query])[0]
vector_results = qdrant.search(
collection_name=COLLECTION,
query_vector=query_embedding,
limit=top_k * 2, # 多めに取得してリランク
)
# 2. キーワード検索(Qdrantのフィルタ機能)
keywords = extract_keywords(query) # 形態素解析でキーワード抽出
keyword_results = qdrant.scroll(
collection_name=COLLECTION,
scroll_filter={
"should": [
{"key": "content", "match": {"text": kw}}
for kw in keywords
]
},
limit=top_k * 2,
)
# 3. RRF(Reciprocal Rank Fusion)でスコア統合
rrf_scores = {}
k = 60 # RRFパラメータ
for rank, result in enumerate(vector_results):
doc_id = result.id
rrf_scores[doc_id] = rrf_scores.get(doc_id, 0) + 1 / (k + rank + 1)
for rank, result in enumerate(keyword_results[0]):
doc_id = result.id
rrf_scores[doc_id] = rrf_scores.get(doc_id, 0) + 1 / (k + rank + 1)
# 4. スコア順にソートしてtop_k件を返す
sorted_ids = sorted(rrf_scores, key=rrf_scores.get, reverse=True)[:top_k]
return [r for r in vector_results if r.id in sorted_ids]クエリ拡張(Query Expansion)
ユーザーの質問を拡張して検索精度を向上させます。
def expand_query(original_query: str) -> list[str]:
"""LLMでクエリを複数のバリエーションに拡張"""
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{
"role": "system",
"content": """ユーザーの質問を、同じ意味だが異なる表現の検索クエリに3つ変換してください。
JSON配列で出力してください。例: ["クエリ1", "クエリ2", "クエリ3"]"""
}, {
"role": "user",
"content": original_query,
}],
temperature=0.3,
)
queries = json.loads(response.choices[0].message.content)
return [original_query] + queries # 元のクエリも含めるハルシネーション対策
RAGで最も重要な課題の一つが、LLMが検索結果にない情報を「でっち上げる」ハルシネーションです。
対策1: プロンプトでの明示的な指示
以下のドキュメントのみに基づいて回答してください。
ドキュメントに記載されていない情報は「該当する情報が見つかりませんでした」と回答してください。
推測や一般的な知識での補完は行わないでください。
検索結果:
{retrieved_documents}
質問: {user_query}対策2: 信頼度スコアの活用
def should_answer(search_results: list, threshold: float = 0.75) -> bool:
"""検索結果の信頼度が十分か判定"""
if not search_results:
return False
max_score = max(r.score for r in search_results)
return max_score >= threshold対策3: 回答の根拠チェック
def verify_answer(answer: str, sources: list[str]) -> dict:
"""回答が検索結果に基づいているか検証"""
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{
"role": "system",
"content": """回答がソースドキュメントに基づいているか検証してください。
各文について「supported」「not_supported」「partial」を判定し、
JSON形式で返してください。"""
}, {
"role": "user",
"content": f"回答:\n{answer}\n\nソース:\n{chr(10).join(sources)}",
}],
)
return json.loads(response.choices[0].message.content)OpenClawでのCronによる定期更新
自動再インデックス設定
OpenClawのCronジョブで、ナレッジベースを定期的に更新します。
# openclaw.json への設定追加
openclaw cron add rag-reindex \
--schedule "0 3 * * *" \
--command "~/.openclaw/skills/rag-knowledge-base/scripts/index-documents.py --source all" \
--description "RAGナレッジベースの全ソース再インデックス"差分更新でコストと時間を最適化:
def incremental_index(source: str, since: str):
"""差分インデックス — 更新されたドキュメントのみ再インデックス"""
if source == "notion":
# Notionのlast_edited_timeでフィルタ
pages = notion.databases.query(
database_id=os.environ["NOTION_DATABASE_ID"],
filter={
"property": "Last edited time",
"last_edited_time": {"after": since},
},
)
# 更新されたページのみインデックス
for page in pages["results"]:
reindex_page(page)
elif source == "slack":
# 指定日時以降のメッセージのみ取得
index_slack_messages(
channel_ids=SLACK_CHANNELS,
since_timestamp=since,
)実践的なユースケース
1. 新入社員オンボーディングBot
Q: 「勤怠の申請方法を教えて」
A: 勤怠の申請はFreeeから行います。
1. Freee人事労務にログイン(https://hr.freee.co.jp)
2. 左メニューの「勤怠」→「打刻修正」を選択
3. 該当日を選んで出退勤時刻を入力
4. 「申請」ボタンをクリック
※リモートワークの場合は「備考」に「在宅」と記入してください。
※月末締めなので、翌月3日までに当月分を全て申請してください。
📚 参考ドキュメント:
- [勤怠管理マニュアル](https://notion.so/xxx) — 第3章: 申請方法
- [リモートワーク規定](https://notion.so/yyy) — 勤怠ルール2. 技術トラブルシューティング
Q: 「本番のDBが遅くなった時の対応手順は?」
A: 本番DB(PostgreSQL)のパフォーマンス劣化時の対応手順:
**初動確認(5分以内):**
1. CloudWatchでDB CPU/メモリ/接続数を確認
2. `pg_stat_activity`でロングランニングクエリを特定
3. 直近のデプロイ・スキーマ変更を確認
**一次対応:**
- ロングランニングクエリの強制終了: `SELECT pg_terminate_backend(pid);`
- Read Replicaへのトラフィック切り替え
- 接続プールの空き確保
**エスカレーション基準:**
- 30分以内に改善しない場合 → DBチームリーダーに連絡
- データ損失の疑いがある場合 → 即座にCTOに報告
📚 参考ドキュメント:
- [DB運用ランブック](https://notion.so/xxx) — PostgreSQLトラブルシューティング
- [インシデント対応フロー](https://notion.so/yyy) — エスカレーション基準3. SES契約・営業サポート
Q: 「○○社との契約更新の条件は?」
A: 検索結果に○○社の契約情報は見つかりませんでした。
契約情報は機密データのため、ナレッジベースの対象外となっています。
営業担当の△△さん、または契約管理システム(https://crm.example.com)で
直接ご確認ください。コスト最適化
埋め込み生成コストの管理
| モデル | 次元数 | 1Mトークンあたりコスト | 精度 |
|---|---|---|---|
| text-embedding-3-small | 1536 | $0.02 | ○ 十分 |
| text-embedding-3-large | 3072 | $0.13 | ◎ 高い |
| text-embedding-ada-002 | 1536 | $0.10 | ○ 標準 |
多くのユースケースではtext-embedding-3-smallで十分な精度が得られます。ドキュメント数が多い場合は、まずsmallで構築し、精度不足を感じたらlargeに移行しましょう。
月間コスト試算例
| 項目 | 数量 | コスト |
|---|---|---|
| ドキュメント埋め込み(初回) | 100万トークン | $0.02 |
| 日次差分更新 | 5万トークン/日 | $0.03/月 |
| クエリ埋め込み | 1000クエリ/月 | $0.002/月 |
| LLM回答生成 | 1000回/月 | $3〜15/月 |
| Qdrant(セルフホスト) | 1インスタンス | $0(サーバー費のみ) |
| 合計 | $5〜20/月 |
まとめ — 社内ナレッジをAIで活性化する
OpenClawでRAGナレッジベースを構築することで、社内の知識を効率的に活用できるAIアシスタントが実現します。
- マルチソース統合: Notion・Slack・Google Drive・GitHubのドキュメントを一つのインターフェースで検索
- 高精度な検索: ハイブリッド検索・クエリ拡張・リランキングで関連度の高い情報を取得
- ハルシネーション対策: 信頼度スコア・ソース引用・回答検証で正確性を担保
- 運用自動化: OpenClawのCronジョブで定期的なインデックス更新を自動化
OpenClaw入門ガイドでOpenClawの基本を押さえ、スキル開発ガイドとMCP連携ガイドを参考にRAGスキルを構築してください。メモリ管理ガイドの知識と組み合わせれば、より高度なナレッジ活用が可能になります。





