- OpenClawはエージェント単位で異なるAIモデルを割り当てて最適化できる
- リサーチ→実装→レビューのパイプラインでモデルを使い分けると費用対効果が最大化
- フォールバック設定とCodexBarモニタリングでコスト管理も万全
「Claude Opusは高性能だけどコストが高い」「軽いタスクにも同じモデルを使うのはもったいない」——AIエージェントを運用していると、こうした課題に直面します。
OpenClawのマルチモデルオーケストレーションは、タスクの特性に応じて最適なAIモデルを自動的に使い分ける仕組みです。高度な推論にはClaude Opus、軽量タスクにはGPT-5.4 mini、マルチモーダルにはGeminiと、適材適所のモデル配置を実現できます。
この記事では、マルチモデル構成の設計から実装、コスト最適化まで徹底解説します。
- マルチモデルオーケストレーションの基本概念
- OpenClawでのモデル設定と切り替え方法
- モデル別の得意領域と使い分け戦略
- サブエージェント構成でのモデル分散パターン
- コスト最適化とトラブルシューティング
マルチモデルオーケストレーションとは
単一モデル運用の限界
AIエージェントを1つのモデルだけで運用する場合、以下の問題が生じます。
- コスト効率が悪い:簡単な返答にも高額なモデルを使ってしまう
- 得意分野の偏り:1つのモデルでは全タスクを最適にこなせない
- 耐障害性の欠如:APIダウン時にサービスが完全停止
OpenClawが実現するモデル連携アーキテクチャ
OpenClaw入門ガイドで基本を押さえた上で、マルチモデル構成を理解しましょう。OpenClawは以下のアーキテクチャでモデル連携を実現します。
- エージェント層:各エージェントに最適なモデルを割り当て
- セッション層:タスクに応じてセッション内でモデルを切り替え
- フォールバック層:API障害時に別モデルに自動切り替え
OpenClawのモデル設定と切り替え
エージェント別モデル設定(openclaw.json)
openclaw.jsonでエージェントごとにデフォルトモデルを指定できます。
{
"agents": {
"main": {
"model": "anthropic/claude-opus-4-6",
"description": "メインエージェント - 高度な推論タスク向け"
},
"researcher": {
"model": "google/gemini-2.5-pro",
"description": "リサーチエージェント - 検索・要約向け"
},
"assistant": {
"model": "openai/gpt-5.4-mini",
"description": "軽量アシスタント - 定型タスク向け"
}
}
}タスク別モデルオーバーライド
Cronジョブやサブエージェントのスポーンでは、タスク単位でモデルをオーバーライドできます。
{
"schedule": { "kind": "cron", "expr": "0 8 * * *" },
"payload": {
"kind": "agentTurn",
"message": "今日のニュースをまとめて",
"model": "google/gemini-2.5-flash"
}
}定期的な軽量タスクにはFlashモデルを指定することで、コストを最大80%削減できます。
セッション内での動的モデル切り替え
OpenClawのスラッシュコマンドを使えば、セッション中にモデルを切り替えることも可能です。
/model anthropic/claude-sonnet-4OpenClawセッション・サブエージェントガイドも参考にしてください。
モデル別の得意領域と使い分け戦略
Claude Opus 4.6 — 高度な推論・長時間タスク
| 項目 | 詳細 |
|---|---|
| 得意領域 | 複雑な推論、大規模コード生成、アーキテクチャ設計 |
| コンテキスト | 100万トークン |
| コスト | 高($15/$75 per 1M tokens) |
| 推奨タスク | 設計判断、難易度の高いデバッグ、長文コンテンツ |
GPT-5.4 mini — 軽量タスク・高速応答
| 項目 | 詳細 |
|---|---|
| 得意領域 | 定型処理、分類タスク、簡単なQ&A |
| コンテキスト | 128Kトークン |
| コスト | 低($0.15/$0.60 per 1M tokens) |
| 推奨タスク | データ整形、テンプレート生成、日常的な応答 |
Gemini 2.5 Pro — マルチモーダル・検索連携
| 項目 | 詳細 |
|---|---|
| 得意領域 | 画像解析、Web検索連携、多言語処理 |
| コンテキスト | 100万トークン |
| コスト | 中(Google AI Pro契約で実質無制限) |
| 推奨タスク | リサーチ、画像分析、翻訳、SEO調査 |
サブエージェント構成でのモデル分散
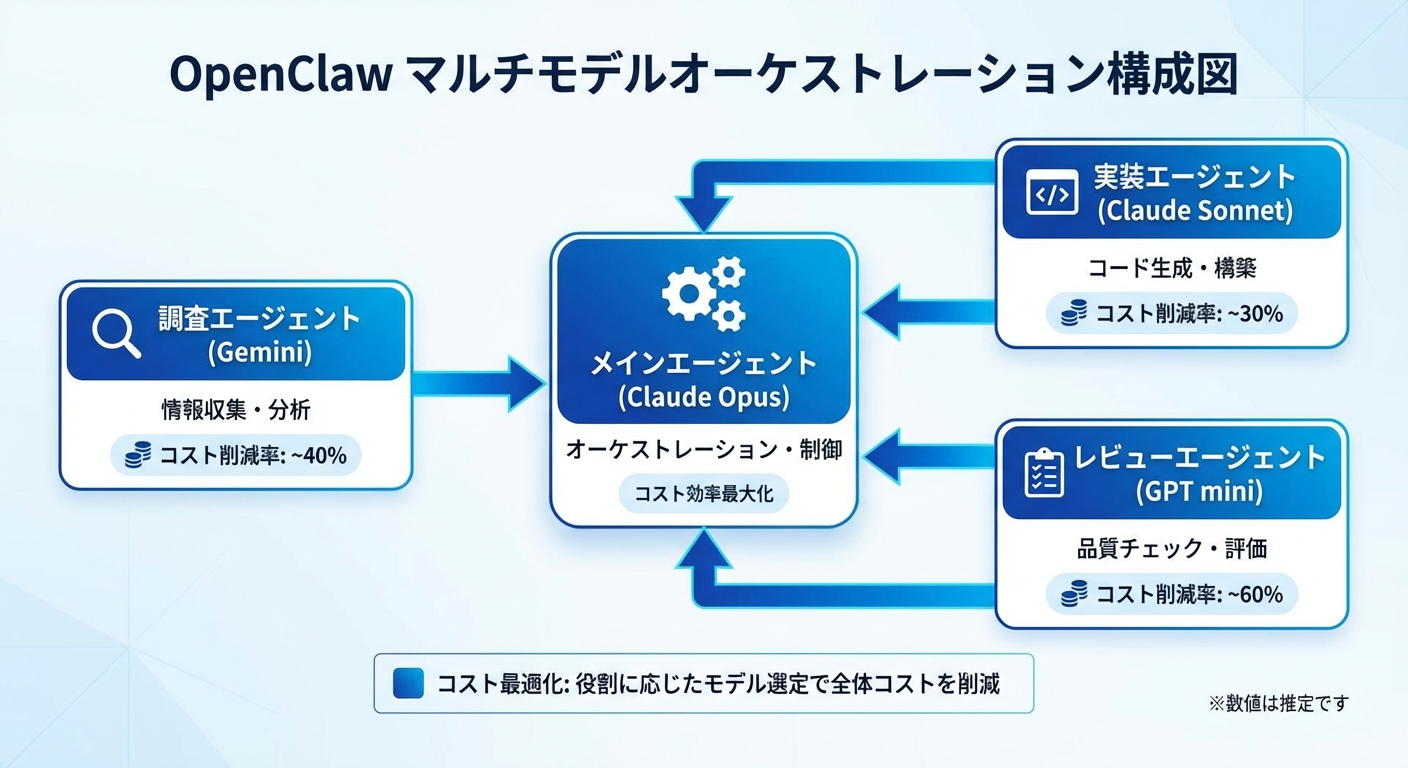
メインエージェント+サブエージェントの設計パターン
最もコスト効率の良い構成は「賢いオーケストレーター + 特化型ワーカー」パターンです。
メインエージェント(Claude Opus)
├─ リサーチサブエージェント(Gemini Pro)
├─ 実装サブエージェント(Claude Sonnet)
└─ レビューサブエージェント(GPT-5.4 mini)ACP(Agent Communication Protocol)の活用
OpenClawスキル開発ガイドで解説しているACP(Agent Communication Protocol)を使うと、サブエージェント間の通信が標準化され、モデルに依存しないエージェント間連携が実現します。
実践例: リサーチ(Gemini)→ 実装(Claude)→ レビュー(GPT)
具体的なパイプライン例です。
- リサーチフェーズ(Gemini 2.5 Pro):Web検索で最新情報を収集・要約
- 実装フェーズ(Claude Sonnet 4):リサーチ結果をもとにコードを実装
- レビューフェーズ(GPT-5.4 mini):チェックリストに基づいた定型レビュー
- 最終判断(Claude Opus 4.6):重要な設計判断のみ高性能モデルで実行
コスト最適化とトークン管理
モデル別コスト比較と予算設計
月間のAIコストを抑えるには、タスクの80%を低コストモデル、20%を高性能モデルで処理するのが目安です。
| モデル | 月間タスク比率 | 月間コスト目安 |
|---|---|---|
| Claude Opus 4.6 | 10% | $50〜100 |
| Claude Sonnet 4 | 30% | $30〜60 |
| Gemini 2.5 Pro | 40% | AI Pro $50固定 |
| GPT-5.4 mini | 20% | $5〜15 |
OpenClawコスト最適化ガイドで詳しい計算方法を解説しています。
CodexBarでの使用量モニタリング
CodexBarを使えば、モデル別の使用量・コストをリアルタイムでモニタリングできます。予算上限の設定やアラート通知も可能です。
マルチモデル構成のトラブルシューティング
フォールバック設定
API障害に備えたフォールバック設定は以下のように行います。
{
"models": {
"fallback": [
"anthropic/claude-opus-4-6",
"google/gemini-2.5-pro",
"openai/gpt-5.4"
]
}
}プライマリモデルがダウンした場合、自動的に次のモデルに切り替わります。
レート制限への対処
複数のエージェントが同時にAPIを呼び出すと、レート制限に達する場合があります。OpenClawマルチエージェント設計ガイドで解説しているキューイング機構を活用しましょう。
まとめ — 適材適所のモデル活用
OpenClawのマルチモデルオーケストレーションは、AIエージェント運用のコストパフォーマンスと信頼性を大幅に向上させます。
- エージェント別モデル設定でタスクに最適なモデルを自動適用
- サブエージェント構成でリサーチ・実装・レビューを分散
- フォールバック設定でAPI障害への耐障害性を確保
- CodexBarでコストをリアルタイムモニタリング
単一モデルに依存する運用から卒業し、適材適所のモデル活用を始めてみましょう。





