
- OpenClawのcron・ハートビート・Webhookを組み合わせて「24時間自律監視」を構築できる
- Slack・Discord・メールなど複数チャネルにアラートを自動振り分けし、対応漏れをゼロにする
- 障害検知→通知→自動復旧→事後レポートまでの完全自動化パイプラインで運用コストを80%削減
「サーバーが落ちていたのに、誰も気づかず丸一日放置してしまった」——SES現場でこんな経験はありませんか?
手動のモニタリングには限界があります。人間は24時間ダッシュボードを監視し続けることはできませんし、深夜帯や休日にアラートを見逃すことも珍しくありません。しかし、OpenClawを活用すれば、AIエージェントが常時監視し、異常を検知し、自動で復旧処理まで行う仕組みを構築できます。
本記事では、OpenClawのモニタリング・アラート通知設計の全体像から、SES現場で即座に使える実践的な構成パターンまでを網羅的に解説します。
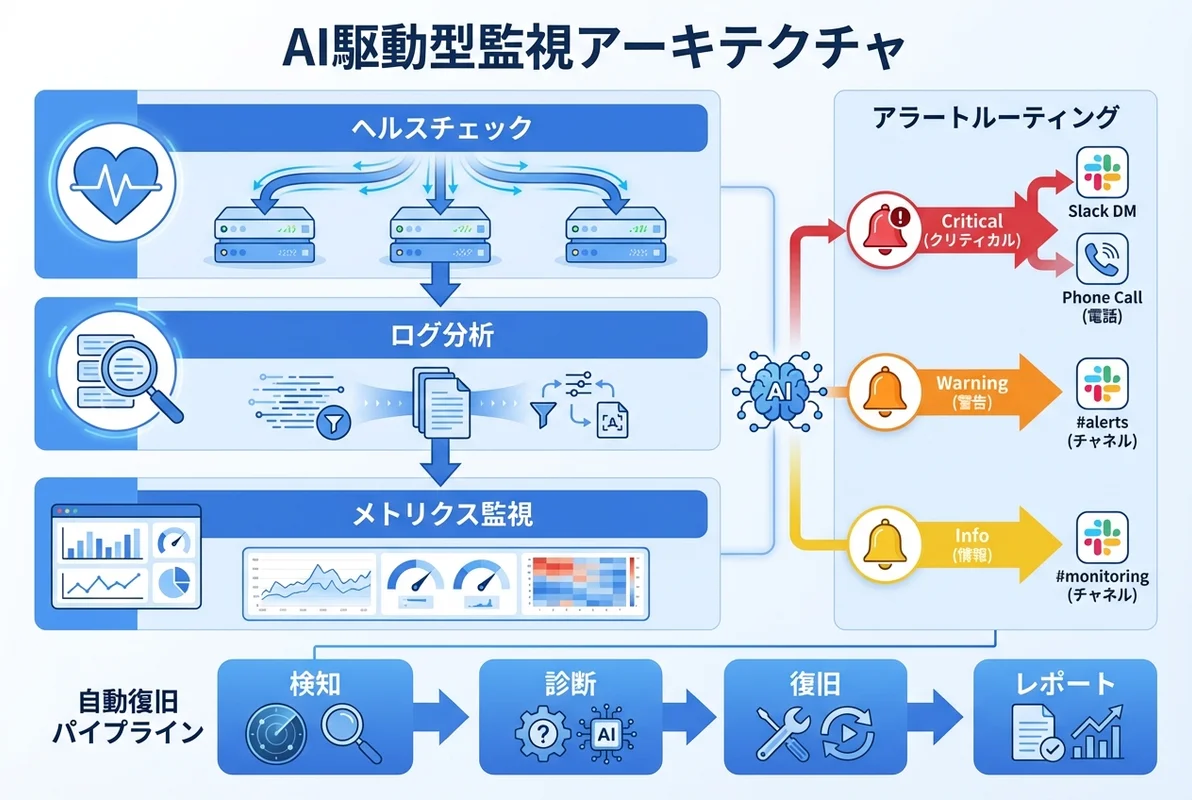
モニタリングの全体設計——3層アーキテクチャ
OpenClawによるモニタリングは、以下の3層で設計するのが最も効果的です。
第1層:ヘルスチェック(定期ポーリング)
最も基本的な監視手法です。OpenClawのcronジョブ機能を活用して、対象システムに定期的にリクエストを送信し、レスポンスの正常性を確認します。
# openclaw.json - cronジョブ設定例
{
"cron": [
{
"name": "health-check-api",
"schedule": "*/5 * * * *",
"prompt": "curl -s -o /dev/null -w '%{http_code}' https://api.example.com/health をチェックし、200以外ならSlackの #alerts チャネルに通知してください",
"model": "anthropic/claude-sonnet-4-20250514"
}
]
}ポイントは軽量モデルを使うことです。ヘルスチェックは頻度が高いため、コスト最適化の観点からSonnetクラスのモデルで十分です。
第2層:ログ分析(イベントドリブン)
アプリケーションログやシステムログをリアルタイムで解析し、異常パターンを検出する層です。OpenClawのWebhook連携を使って、ログ集約ツール(Fluentd、CloudWatch Logs等)からイベントを受け取ります。
# ログ監視スキルの例
# skills/log-monitor/scripts/analyze.sh
tail -f /var/log/app/error.log | while read line; do
echo "$line" | curl -X POST http://localhost:3000/webhook/log-alert \
-H "Content-Type: application/json" \
-d "{\"log\": \"$line\"}"
done第3層:メトリクス監視(閾値ベース)
CPU使用率、メモリ消費量、ディスク使用量、レスポンスタイムなどの数値メトリクスに閾値を設定し、超過時にアラートを発火させます。
// スキルスクリプト例:メトリクス取得と閾値判定
const metrics = {
cpu: await getCpuUsage(), // %
memory: await getMemoryUsage(), // %
disk: await getDiskUsage(), // %
responseTime: await ping(url), // ms
};
const thresholds = {
cpu: { warn: 70, critical: 90 },
memory: { warn: 80, critical: 95 },
disk: { warn: 85, critical: 95 },
responseTime: { warn: 2000, critical: 5000 },
};アラート通知の設計——重要度別ルーティング
すべての異常を同じチャネルに同じ優先度で通知すると、アラート疲れが発生し、本当に重要な通知を見逃す原因になります。OpenClawではSlack・Discord連携と組み合わせて、重要度に応じた通知ルーティングを設計できます。
重要度レベルの定義
| レベル | 条件 | 通知先 | 対応期限 |
|---|---|---|---|
| 🔴 Critical | サービス停止・データ損失リスク | Slack DM + 電話 + PagerDuty | 即時 |
| 🟠 Warning | パフォーマンス劣化・閾値超過 | Slack #alerts チャネル | 1時間以内 |
| 🟡 Info | 軽微な異常・予兆検知 | Slack #monitoring チャネル | 翌営業日 |
| 🔵 Debug | デバッグ情報・統計レポート | ログファイルのみ | 不要 |
通知テンプレートの設計
アラート通知は5W1Hを意識して設計します。
🔴 **[CRITICAL] API応答異常**
- **What**: api.example.com が HTTP 503 を返却
- **When**: 2026-03-07 14:32:15 JST
- **Where**: 本番環境 / ap-northeast-1
- **Impact**: ユーザーログイン不可(推定影響: 約500ユーザー/時)
- **Action**: 自動再起動を実行中...
- **Runbook**: https://wiki.example.com/runbook/api-503ハートビートを活用した自律監視パターン
OpenClawのハートビート機能は、定期的にエージェントを起動して任意のチェックを実行する仕組みです。cronジョブとの違いは、会話コンテキストを維持できる点です。
HEARTBEAT.md による監視チェックリスト
# HEARTBEAT.md
## 監視タスク(ローテーション実行)
- [ ] API ヘルスチェック(5分ごと → cronに委任済み)
- [ ] SSL証明書の有効期限確認(日次)
- [ ] ディスク使用率チェック(日次)
- [ ] 未処理エラーログの要約(4時間ごと)
- [ ] 依存サービスのステータス確認(4時間ごと)ハートビートとcronの使い分けについては、Ep.6のcronジョブ解説も参考にしてください。
自動復旧パイプラインの構築
モニタリングの真価は、異常を検知した後の自動復旧にあります。OpenClawのマルチエージェント設計を活用すると、以下のような自動復旧パイプラインを構築できます。
Step 1:異常検知と初期診断
# cronジョブで異常検知
{
"name": "api-health-monitor",
"schedule": "*/3 * * * *",
"prompt": "以下を順にチェックして異常があれば対応してください: 1) curl -s https://api.example.com/health の応答確認 2) 異常時はログを確認 3) 復旧アクションを実行 4) 結果をSlackに報告"
}Step 2:復旧アクションの実行
OpenClawのサブエージェント機能を使えば、復旧処理をメインセッションとは分離して実行できます。
# 復旧スキル例:サービス再起動
#!/bin/bash
# skills/auto-recover/scripts/restart-service.sh
SERVICE_NAME="$1"
MAX_RETRIES=3
RETRY_COUNT=0
while [ $RETRY_COUNT -lt $MAX_RETRIES ]; do
echo "🔄 ${SERVICE_NAME} を再起動中... (試行 $((RETRY_COUNT+1))/$MAX_RETRIES)"
systemctl restart "$SERVICE_NAME"
sleep 10
if systemctl is-active --quiet "$SERVICE_NAME"; then
echo "✅ ${SERVICE_NAME} の再起動に成功"
exit 0
fi
RETRY_COUNT=$((RETRY_COUNT + 1))
done
echo "❌ ${SERVICE_NAME} の再起動に${MAX_RETRIES}回失敗"
exit 1Step 3:事後レポートの自動生成
障害対応後にインシデントレポートを自動生成することで、振り返りと改善サイクルを回せます。
## インシデントレポート自動生成テンプレート
### 概要
- **発生日時**: {detected_at}
- **復旧日時**: {recovered_at}
- **ダウンタイム**: {downtime_minutes}分
- **影響範囲**: {impact_description}
### タイムライン
1. {detected_at} - 異常検知({detection_method})
2. {action_at} - 自動復旧開始
3. {recovered_at} - サービス復旧確認
### 根本原因
{root_cause_analysis}
### 再発防止策
{preventive_measures}SES現場で使えるモニタリングレシピ集
レシピ1:開発環境の死活監視
SES現場では開発環境が不安定なことが多く、定期的なヘルスチェックが重要です。
{
"name": "dev-env-monitor",
"schedule": "*/10 * * * *",
"prompt": "開発環境 (dev.internal.example.com) の各エンドポイントをチェック。ダウンしているサービスがあればSlack #dev-alerts に通知",
"model": "anthropic/claude-sonnet-4-20250514"
}レシピ2:SSL証明書の有効期限監視
証明書切れによるサービス停止はSES案件で致命的な信頼低下につながります。
# skills/ssl-monitor/scripts/check-ssl.sh
#!/bin/bash
DOMAIN="$1"
EXPIRY=$(echo | openssl s_client -servername "$DOMAIN" -connect "$DOMAIN":443 2>/dev/null \
| openssl x509 -noout -enddate 2>/dev/null \
| cut -d= -f2)
EXPIRY_EPOCH=$(date -j -f "%b %d %T %Y %Z" "$EXPIRY" "+%s" 2>/dev/null)
NOW_EPOCH=$(date "+%s")
DAYS_LEFT=$(( (EXPIRY_EPOCH - NOW_EPOCH) / 86400 ))
if [ "$DAYS_LEFT" -lt 30 ]; then
echo "⚠️ SSL証明書の有効期限が残り${DAYS_LEFT}日です: $DOMAIN"
fiレシピ3:デプロイ後の自動スモークテスト
GitHub PR自動化と連携して、デプロイ完了後に自動でスモークテストを実行します。
{
"name": "post-deploy-smoke",
"schedule": "webhook",
"trigger": "github_deployment_status",
"prompt": "デプロイ完了を検知しました。以下のスモークテストを実行: 1) トップページの表示確認 2) API認証フローの確認 3) 主要機能の動作確認。結果をSlack #deployments に報告"
}レシピ4:コスト異常検知
コスト最適化の一環として、API利用料の急増を自動検知します。
// 日次のAPI利用料チェック
const todayCost = await getApiCostToday();
const avgCost = await getApiCostAverage(7); // 過去7日平均
if (todayCost > avgCost * 1.5) {
await notify('warning',
`API利用料が平均の${Math.round(todayCost/avgCost*100)}%に達しています`
);
}モニタリングダッシュボードの構築
OpenClawのモニタリング結果を一元的に可視化するためには、ダッシュボードの構築が有効です。ワークスペース設計と組み合わせて、memory/ ディレクトリに監視データを蓄積し、定期レポートとして出力する方法が実用的です。
メモリファイルによるデータ蓄積
// memory/monitoring-state.json
{
"lastCheck": "2026-03-07T14:30:00+09:00",
"services": {
"api": { "status": "healthy", "responseTime": 145, "uptime": 99.98 },
"web": { "status": "healthy", "responseTime": 89, "uptime": 99.99 },
"db": { "status": "degraded", "responseTime": 2300, "uptime": 99.85 }
},
"alerts": {
"today": 3,
"critical": 0,
"warning": 2,
"info": 1
}
}日次レポートの自動生成
{
"name": "daily-monitoring-report",
"schedule": "0 9 * * *",
"prompt": "memory/monitoring-state.json を読み込み、過去24時間の監視サマリーレポートを作成してSlack #daily-report に投稿。稼働率・インシデント数・パフォーマンストレンドを含めること"
}ベストプラクティスと注意点
やるべきこと
- 段階的な導入: まずヘルスチェックから始め、徐々にログ分析・自動復旧を追加する
- アラートの重要度分類: すべてをCriticalにしない。本当に即時対応が必要なものだけにする
- 定期的な閾値見直し: システムの成長に合わせて閾値を調整する
- 復旧手順のコード化: 手動で復旧している手順はスキル化して自動化する
- 監視の監視: モニタリングシステム自体が停止していないかを別経路で確認する
やってはいけないこと
- アラートの無視: 通知が多すぎて無視するようになったら、閾値設計を見直す
- 過剰な監視: 1秒間隔でポーリングするとAPIコストが膨大になる
- 復旧の自動化しすぎ: 根本原因を調べずに再起動だけ繰り返すのは危険
- 個人チャネルへの通知集中: チーム全体で共有できるチャネルを使う
まとめ
OpenClawのモニタリング・アラート通知設計は、**3層アーキテクチャ(ヘルスチェック・ログ分析・メトリクス監視)**を軸に、重要度別の通知ルーティングと自動復旧パイプラインを組み合わせることで、SES現場の運用負荷を大幅に削減できます。
特に重要なのは以下の3点です。
- cronジョブとハートビートの適切な使い分けで、コストを抑えながら網羅的な監視を実現する
- アラートの重要度分類で、通知疲れを防ぎ、本当に重要なインシデントに集中する
- 自動復旧パイプラインで、深夜・休日でも即座に障害対応を行う
まずはヘルスチェックの設定から始めて、段階的に監視体制を拡充していきましょう。
📚 OpenClaw 完全攻略シリーズ
| Ep. | タイトル |
|---|---|
| 1 | OpenClaw使い方入門 |
| 2 | スキル開発ガイド |
| 3 | マーケティング自動化パイプライン |
| 4 | GitHub連携とPR自動化 |
| 5 | マルチエージェント設計 |
| 6 | cronジョブとスケジュール自動化 |
| 7 | ブラウザ自動化 |
| 8 | コスト最適化とモデル選定 |
| 9 | ワークスペース設計 |
| 10 | セッション管理とサブエージェント |
| 11 | モニタリングとアラート通知設計(本記事) |
出典・参考資料:





