- OpenClaw × ローカルLLMでAPI費用を月数万円削減しながらプライバシーを完全保護
- Ollama・vLLM・LM StudioをOpenAI互換APIとして接続 — 設定は数行で完了
- ローカルとクラウドのハイブリッド運用で、コストと品質のバランスを最適化できる
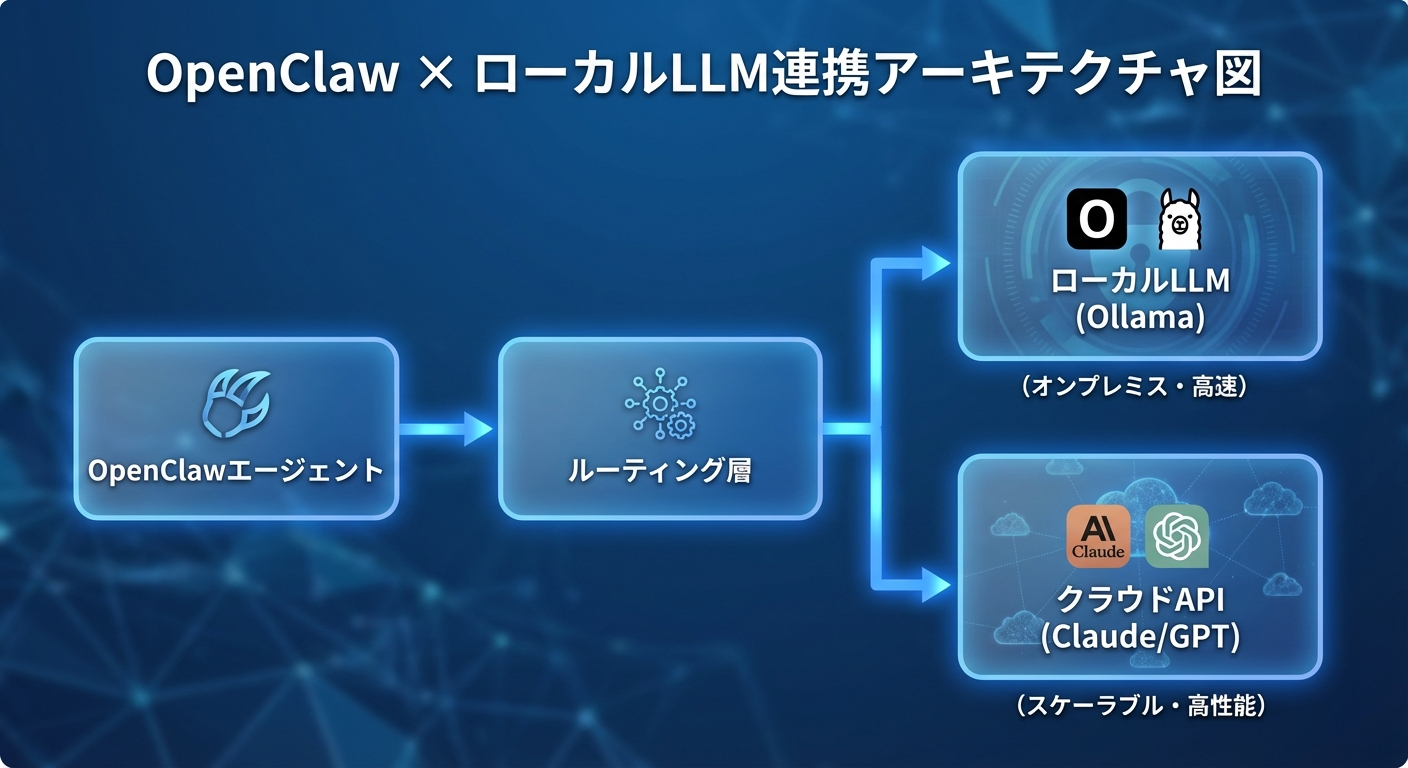
OpenClawは複数のLLMプロバイダーを柔軟に切り替えて使えるAIエージェントプラットフォームです。クラウドAPIだけでなく、ローカルで動作するLLMとの連携も可能です。
この記事では、Ollama・vLLMなどのローカルLLMをOpenClawに接続し、コスト削減とプライバシー保護を両立する方法を解説します。
- ローカルLLM連携のメリットとユースケース
- Ollama・vLLM・LM Studioの接続方法
- タスク別のおすすめモデル選定ガイド
- ローカル × クラウドのハイブリッド運用術
OpenClaw × ローカルLLMのメリット
コスト削減とプライバシー保護
ローカルLLMを活用する最大のメリットは、APIコストの削減とデータのプライバシー保護です。
| 比較項目 | クラウドAPI | ローカルLLM |
|---|---|---|
| 月額コスト | $50〜$200+ | 電気代のみ($5〜$15) |
| データの送信先 | 外部サーバー | ローカルマシン内 |
| レスポンス速度 | ネットワーク依存 | GPU性能依存 |
| 品質(2026年) | 最高品質 | 中〜高品質 |
| 可用性 | API障害リスク | ハードウェア依存 |
日常的な軽量タスク(メール下書き、スケジュール確認、簡単なコード補完)をローカルLLMに任せるだけで、月$30〜$80のAPI費用削減が見込めます。
オフライン環境での自律運用
出張先やネットワーク制限のある環境でも、ローカルLLMがあればOpenClawの基本機能を利用できます。
- 機内でのコーディング支援
- セキュリティが厳しい客先での利用
- ネットワーク障害時のフォールバック
対応するローカルLLMプロバイダー
Ollama(Llama 3.x / Mistral / Gemma)
Ollamaは最も手軽にローカルLLMを実行できるツールです。
# Ollamaのインストール
curl -fsSL https://ollama.ai/install.sh | sh
# モデルのダウンロード
ollama pull llama3.3:70b # 高品質(要40GB+ VRAM)
ollama pull llama3.3:8b # 軽量(8GB VRAMで動作)
ollama pull mistral-nemo # バランス型
ollama pull gemma2:27b # Google製、日本語性能高いOllamaの特徴は以下の通りです。
- ワンコマンドでインストール・モデルダウンロード
- macOS(Metal)/ Linux(CUDA)/ Windows対応
- OpenAI互換APIを自動で提供(
http://localhost:11434) - モデルの切り替えが
ollama runコマンドで即座に可能
vLLM / llama.cpp / LM Studio
より高度なカスタマイズが必要な場合は、以下のツールも選択肢に入ります。
| ツール | 特徴 | 推奨環境 |
|---|---|---|
| vLLM | 高スループット推論エンジン | NVIDIA GPU搭載サーバー |
| llama.cpp | CPU推論に最適化 | GPU非搭載マシン |
| LM Studio | GUIでモデル管理 | 初心者向け |
OpenAI互換APIとしての接続方式
すべてのローカルLLMツールは、OpenAI互換APIエンドポイントを提供します。これにより、OpenClawからは通常のOpenAI APIと同じように呼び出すことができます。
POST http://localhost:11434/v1/chat/completions
Content-Type: application/json
{
"model": "llama3.3:8b",
"messages": [{"role": "user", "content": "Hello!"}]
}
セットアップ手順
Ollamaのインストールとモデルダウンロード
macOSでの最短セットアップ手順は以下の通りです。
# 1. Ollamaをインストール
brew install ollama
# 2. Ollamaサーバーを起動
ollama serve &
# 3. 推奨モデルをダウンロード
ollama pull llama3.3:8b # 日常タスク用
ollama pull deepseek-coder-v2 # コーディング用
# 4. 動作確認
curl http://localhost:11434/v1/chat/completions \
-d '{"model":"llama3.3:8b","messages":[{"role":"user","content":"テスト"}]}'openclaw.jsonのモデル設定
OpenClawの設定ファイルにローカルモデルを追加します。
{
"models": {
"local-llama": {
"provider": "openai-compatible",
"baseUrl": "http://localhost:11434/v1",
"model": "llama3.3:8b",
"maxTokens": 4096
},
"local-coder": {
"provider": "openai-compatible",
"baseUrl": "http://localhost:11434/v1",
"model": "deepseek-coder-v2",
"maxTokens": 8192
}
}
}カスタムエンドポイントの指定
vLLMやLM Studioを使う場合も、同じ形式でエンドポイントを指定するだけです。
{
"models": {
"vllm-server": {
"provider": "openai-compatible",
"baseUrl": "http://192.168.1.100:8000/v1",
"model": "meta-llama/Meta-Llama-3.3-70B",
"maxTokens": 4096
}
}
}OpenClaw導入ガイドで、基本的なOpenClawの設定方法を確認できます。
モデル選定ガイド — タスク別おすすめ
日常タスク向け(7B-13Bモデル)
日常的なタスクには、軽量で高速なモデルが最適です。
| モデル | パラメータ | 必要VRAM | 推奨タスク |
|---|---|---|---|
| Llama 3.3 8B | 8B | 6GB | チャット、要約、翻訳 |
| Gemma 2 9B | 9B | 7GB | 日本語タスク全般 |
| Mistral Nemo | 12B | 8GB | 分析、レポート |
コーディング向け(CodeLlama / DeepSeek Coder)
コーディングタスクには、コード特化モデルが効果的です。
- DeepSeek Coder V2: コード補完、バグ修正、テスト生成
- CodeLlama 34B: 大規模コードベースの理解
- Qwen2.5-Coder 7B: 軽量でバランスの良いコード生成
長文処理向け(大コンテキストモデル)
長いドキュメントの処理には、コンテキスト長の大きいモデルを選びます。
- Llama 3.3 8B(128K): 大量のログ分析
- Mistral Nemo(128K): 長文レポートの要約
- Gemma 2 27B: 高品質な長文生成
ハイブリッド運用のベストプラクティス
ローカル × クラウドの自動切り替え
OpenClawでは、タスクの複雑さに応じてローカルLLMとクラウドAPIを自動切り替えする設定が可能です。
{
"routing": {
"default": "local-llama",
"complex": "anthropic/claude-sonnet-4.6",
"coding": "local-coder",
"creative": "anthropic/claude-opus-4"
}
}軽量タスクはローカル、複雑タスクはクラウドへ
実用的な使い分けの例は以下の通りです。
| タスクの複雑さ | 使用モデル | 理由 |
|---|---|---|
| 簡単な質問応答 | ローカル(8B) | コスト削減、高速応答 |
| メール下書き | ローカル(8B) | プライバシー保護 |
| コード生成 | ローカル(Coder系) | 高速、十分な品質 |
| 複雑な分析 | クラウド(Claude) | 高い推論能力が必要 |
| クリエイティブ作業 | クラウド(Claude/GPT) | 最高品質が必要 |
OpenClawコスト最適化で、さらに詳しいコスト削減テクニックを解説しています。
パフォーマンスチューニング
GPU/Metal活用の最適化
ローカルLLMのパフォーマンスは、GPU設定によって大きく変わります。
macOS(Apple Silicon)の場合:
# Metal GPUを使用(デフォルトで有効)
OLLAMA_NUM_GPU=999 ollama serveLinux(NVIDIA CUDA)の場合:
# CUDA GPUを使用
CUDA_VISIBLE_DEVICES=0,1 ollama serveコンテキスト長とメモリ管理
コンテキスト長を増やすとメモリ消費が増加します。タスクに応じて適切に設定しましょう。
# コンテキスト長を指定してモデル実行
ollama run llama3.3:8b --ctx-size 8192 # デフォルト
ollama run llama3.3:8b --ctx-size 32768 # 長文処理時OpenClawマルチモデル運用で、モデル管理の詳細な手法を確認できます。
まとめ — ローカルLLMで完全自律AIアシスタントを構築
OpenClaw × ローカルLLMの組み合わせは、コスト削減・プライバシー保護・可用性向上を同時に実現する強力な選択肢です。
実践のポイントを整理します。
- ✅ まずはOllamaでLlama 3.3 8Bを試す(最も手軽)
- ✅ openclaw.jsonにローカルモデルのエンドポイントを追加する
- ✅ 日常タスクはローカル、複雑タスクはクラウドのハイブリッド運用にする
- ✅ コーディング用にはDeepSeek CoderやCodeLlamaを別途用意する
- ✅ GPU設定とコンテキスト長を調整してパフォーマンスを最適化する
ローカルLLMの性能は日々向上しています。まずは小さく始めて、自分のワークフローに最適な構成を見つけてください。





