
- OpenClawのcronジョブとスキルでKubernetesクラスタの常時監視を自動化できる
- Pod障害・リソース枯渇・デプロイ失敗を検出し、Slackへの即座通知と自動復旧が可能
- スケーリング判断のAI支援で過不足のないリソース管理を実現
「Kubernetesクラスタの監視に張り付いている時間が長い」「障害発生時の初動対応を自動化したい」「オートスケーリングの設定が適切かどうか判断できない」
結論から言えば、OpenClawのエージェント自動化機能を活用することでKubernetes運用の監視・障害対応・スケーリング管理を大幅に効率化できます。本記事では、実践的な運用自動化パターンを体系的に解説します。
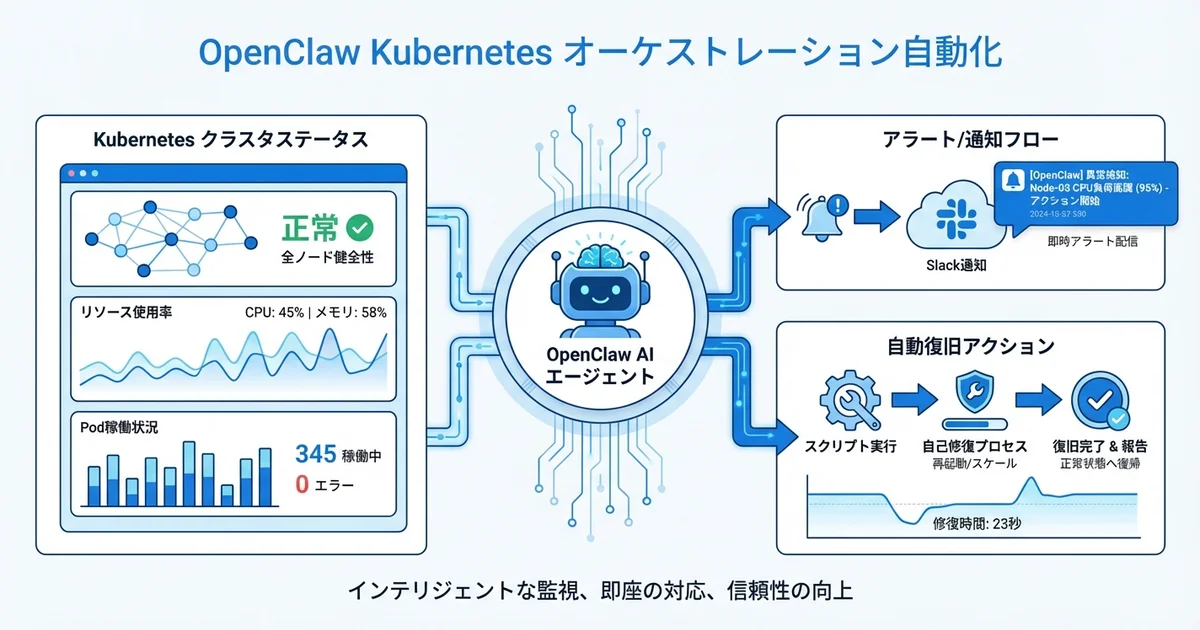
OpenClaw × Kubernetesの運用自動化アーキテクチャ
OpenClawは、AIエージェントが自律的にタスクを実行する基盤です。Kubernetesの運用自動化では、以下のコンポーネントを組み合わせます。
┌─────────────────────────────────────────────────┐
│ OpenClaw │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Cronジョブ │ │ スキル │ │ メモリ │ │
│ │ (定期監視) │ │ (K8s操作) │ │ (履歴) │ │
│ └─────┬────┘ └─────┬────┘ └─────┬────┘ │
│ │ │ │ │
│ └──────────────┼──────────────┘ │
│ │ │
│ ┌────────▼────────┐ │
│ │ AIエージェント │ │
│ │ (判断・実行) │ │
│ └────────┬────────┘ │
│ │ │
│ ┌─────────────┼─────────────┐ │
│ │ │ │ │
│ ┌────▼───┐ ┌─────▼────┐ ┌────▼───┐ │
│ │ kubectl │ │ Slack │ │ GitHub │ │
│ │ 実行 │ │ 通知 │ │ Issue │ │
│ └────────┘ └──────────┘ └────────┘ │
└─────────────────────────────────────────────────┘
│
┌────────▼────────┐
│ Kubernetes │
│ クラスタ │
└─────────────────┘クラスタ監視スキルの作成
基本的な監視スキル
OpenClawのスキルとして、Kubernetesクラスタの状態チェックを定義します。
# skills/k8s-monitor/SKILL.md
---
name: k8s-monitor
description: Kubernetesクラスタの状態監視と異常検出
---
## 概要
kubectl を使用してクラスタの状態を監視し、異常を検出してSlackに通知する。
## 実行手順
### 1. ノード状態チェック
```bash
kubectl get nodes -o wide --no-headers- NotReady ノードがあれば即座に警告
2. Pod状態チェック
kubectl get pods --all-namespaces --field-selector=status.phase!=Running,status.phase!=Succeeded --no-headers- CrashLoopBackOff / ImagePullBackOff / Pending を検出
3. リソース使用率
kubectl top nodes --no-headers
kubectl top pods --all-namespaces --sort-by=cpu --no-headers | head -20- CPU/メモリ使用率が80%超で警告、90%超で緊急通知
4. デプロイメント状態
kubectl get deployments --all-namespaces -o json | jq '.items[] | select(.status.unavailableReplicas > 0)'- unavailableReplicas > 0 のデプロイメントを検出
通知ルール
- 🟢 正常: ログのみ記録(Slack通知なし)
- 🟡 警告: Slackに警告メッセージ
- 🔴 緊急: Slackに即座通知 + 自動復旧試行
### Cronジョブの設定
OpenClawのcron機能でKubernetesの定期監視を設定します。
```json
{
"cron": [
{
"name": "k8s-health-check",
"schedule": "*/5 * * * *",
"prompt": "k8s-monitorスキルを実行して、クラスタの状態をチェックしてください。異常があればSlackの #infra-alerts チャンネルに通知してください。",
"channel": "slack",
"target": "C0AF55LV0B0"
}
]
}この設定により、5分ごとにクラスタの状態がチェックされます。
障害検出と自動復旧
CrashLoopBackOff の自動対応
Podがクラッシュループに陥った場合の自動対応フローです。
# 障害Pod検出スクリプト
#!/bin/bash
# scripts/detect-crashloop.sh
CRASHLOOP_PODS=$(kubectl get pods --all-namespaces \
--field-selector=status.phase=Running \
-o json | jq -r '
.items[] |
select(.status.containerStatuses[]?.state.waiting.reason == "CrashLoopBackOff") |
"\(.metadata.namespace)/\(.metadata.name)"
')
if [ -n "$CRASHLOOP_PODS" ]; then
echo "ALERT: CrashLoopBackOff detected"
echo "$CRASHLOOP_PODS"
for pod in $CRASHLOOP_PODS; do
NAMESPACE=$(echo "$pod" | cut -d'/' -f1)
POD_NAME=$(echo "$pod" | cut -d'/' -f2)
echo "--- Logs for $pod ---"
kubectl logs "$POD_NAME" -n "$NAMESPACE" --tail=50 2>/dev/null
echo "--- Events for $pod ---"
kubectl describe pod "$POD_NAME" -n "$NAMESPACE" | grep -A 10 "Events:"
done
else
echo "OK: No CrashLoopBackOff pods"
fiOpenClawエージェントは、このスクリプトの出力を受け取り、以下の判断を自動で行います。
- ログ分析: エラーメッセージのパターンから原因を推定
- 過去の履歴照合: メモリに記録された過去の障害パターンと照合
- 自動復旧: 可能な場合はPodの再起動やロールバックを実行
- 通知: Slackに障害内容と対応状況を通知
リソース枯渇の予兆検知
# scripts/resource-forecast.sh
#!/bin/bash
echo "=== ノードリソース使用状況 ==="
kubectl top nodes --no-headers | while read line; do
NODE=$(echo "$line" | awk '{print $1}')
CPU_PERCENT=$(echo "$line" | awk '{print $3}' | tr -d '%')
MEM_PERCENT=$(echo "$line" | awk '{print $5}' | tr -d '%')
if [ "$CPU_PERCENT" -gt 90 ]; then
echo "CRITICAL: $NODE CPU=${CPU_PERCENT}%"
elif [ "$CPU_PERCENT" -gt 80 ]; then
echo "WARNING: $NODE CPU=${CPU_PERCENT}%"
fi
if [ "$MEM_PERCENT" -gt 90 ]; then
echo "CRITICAL: $NODE Memory=${MEM_PERCENT}%"
elif [ "$MEM_PERCENT" -gt 80 ]; then
echo "WARNING: $NODE Memory=${MEM_PERCENT}%"
fi
done
echo ""
echo "=== Pending Pods ==="
PENDING=$(kubectl get pods --all-namespaces \
--field-selector=status.phase=Pending --no-headers 2>/dev/null | wc -l)
echo "Pending pods: $PENDING"
if [ "$PENDING" -gt 0 ]; then
kubectl get pods --all-namespaces \
--field-selector=status.phase=Pending --no-headers
fiデプロイ監視の自動化
ローリングアップデートの追跡
デプロイメント更新時の自動監視を設定します。
# scripts/watch-deployment.sh
#!/bin/bash
DEPLOYMENT=$1
NAMESPACE=${2:-default}
TIMEOUT=${3:-300}
echo "Watching deployment: $NAMESPACE/$DEPLOYMENT"
kubectl rollout status deployment/"$DEPLOYMENT" \
-n "$NAMESPACE" \
--timeout="${TIMEOUT}s" 2>&1
EXIT_CODE=$?
if [ $EXIT_CODE -eq 0 ]; then
echo "SUCCESS: Deployment $DEPLOYMENT rolled out successfully"
NEW_IMAGE=$(kubectl get deployment "$DEPLOYMENT" \
-n "$NAMESPACE" \
-o jsonpath='{.spec.template.spec.containers[0].image}')
REPLICAS=$(kubectl get deployment "$DEPLOYMENT" \
-n "$NAMESPACE" \
-o jsonpath='{.status.readyReplicas}')
echo "Image: $NEW_IMAGE"
echo "Ready replicas: $REPLICAS"
else
echo "FAILED: Deployment $DEPLOYMENT rollout failed"
echo "--- Recent Events ---"
kubectl get events -n "$NAMESPACE" \
--sort-by='.lastTimestamp' \
--field-selector="involvedObject.name=$DEPLOYMENT" | tail -10
echo "--- Pod Status ---"
kubectl get pods -n "$NAMESPACE" -l "app=$DEPLOYMENT" --no-headers
fi
exit $EXIT_CODEデプロイ失敗時の自動ロールバック
# scripts/auto-rollback.sh
#!/bin/bash
DEPLOYMENT=$1
NAMESPACE=${2:-default}
echo "Checking deployment health: $NAMESPACE/$DEPLOYMENT"
UNAVAILABLE=$(kubectl get deployment "$DEPLOYMENT" \
-n "$NAMESPACE" \
-o jsonpath='{.status.unavailableReplicas}')
if [ -n "$UNAVAILABLE" ] && [ "$UNAVAILABLE" -gt 0 ]; then
echo "ALERT: $UNAVAILABLE replicas unavailable"
REVISION=$(kubectl rollout history deployment/"$DEPLOYMENT" \
-n "$NAMESPACE" | tail -2 | head -1 | awk '{print $1}')
echo "Rolling back to previous revision..."
kubectl rollout undo deployment/"$DEPLOYMENT" -n "$NAMESPACE"
kubectl rollout status deployment/"$DEPLOYMENT" \
-n "$NAMESPACE" --timeout=120s
echo "ROLLBACK COMPLETE"
else
echo "OK: All replicas available"
fiスケーリング管理のAI支援
HPAの最適化分析
OpenClawエージェントにHPAの現在の設定と実際の負荷パターンを分析させることで、最適なスケーリング設定を導出できます。
# scripts/analyze-hpa.sh
#!/bin/bash
echo "=== HPA Status ==="
kubectl get hpa --all-namespaces -o wide
echo ""
echo "=== HPA Details ==="
kubectl get hpa --all-namespaces -o json | jq '
.items[] | {
namespace: .metadata.namespace,
name: .metadata.name,
minReplicas: .spec.minReplicas,
maxReplicas: .spec.maxReplicas,
currentReplicas: .status.currentReplicas,
desiredReplicas: .status.desiredReplicas,
metrics: [.status.currentMetrics[]? | {
type: .type,
current: (.resource.current.averageUtilization // .pods.current.averageValue // "N/A")
}]
}
'
echo ""
echo "=== 過去24時間のスケーリングイベント ==="
kubectl get events --all-namespaces \
--field-selector=reason=SuccessfulRescale \
--sort-by='.lastTimestamp' | tail -20OpenClawエージェントはこの情報を分析し、以下のような提案を行います。
- 閾値の最適化: 「CPU閾値70%でスケールアウトが頻発しています。80%に引き上げることでコスト削減が見込めます」
- 最小レプリカ数の見直し: 「夜間のトラフィックが少ないため、夜間はminReplicasを1に下げることを推奨します」
- スケーリング速度の調整: 「急激なトラフィック増加に対応するため、scaleUp.stabilizationWindowSecondsを60秒から30秒に短縮すべきです」
Slack通知のフォーマット
OpenClawからのK8s監視通知は、以下のフォーマットで送信されます。
正常時(日次サマリー)
🟢 K8sクラスタ日次レポート (2026-03-20)
📊 クラスタ概要
• ノード数: 3/3 Ready
• Pod数: 47 Running / 0 Pending / 0 Failed
• CPU使用率: 平均 42%(最大 68% node-2)
• メモリ使用率: 平均 55%(最大 72% node-1)
📈 過去24時間
• デプロイ成功: 3件
• スケーリングイベント: 5件
• 障害検出: 0件障害検出時
🔴 K8s障害検出アラート
⚠️ CrashLoopBackOff 検出
• Pod: ses-production/api-server-7d9f8c-x2k4l
• 再起動回数: 8回
• 直近のエラー: ECONNREFUSED - Redis connection failed
🔧 自動対応
• Redis接続先の確認: ✅ 到達可能
• Pod再起動実施: ✅ 完了
• 復旧確認: ✅ Running状態に回復
📋 推奨アクション
• Redis接続のリトライロジックを改善してください
• 関連Issue: #142メモリを活用した障害パターン学習
OpenClawのメモリ機能を使い、過去の障害パターンを蓄積・学習します。
# memory/k8s-incidents.md
## 2026-03-15: Redis接続障害
- 症状: api-server PodがCrashLoopBackOff
- 原因: Redisのメモリ上限到達(maxmemory-policy noeviction)
- 対応: maxmemory-policyをallkeys-lruに変更
- 再発防止: Redis メモリ使用率の監視閾値を追加(80%で警告)
## 2026-03-10: ノードリソース枯渇
- 症状: 新規Podがpending状態で起動せず
- 原因: node-3のCPUリクエスト合計がキャパシティの95%超過
- 対応: 低優先度Podを退避、ノードプールのオートスケーリング有効化
- 再発防止: ノードCPU使用率85%でアラート設定この障害履歴により、OpenClawエージェントは類似の障害が発生した際に過去の対応パターンを参照し、より迅速な判断が可能になります。
SES案件でのKubernetes運用スキル
| スキルレベル | 要求される技術 | 想定月額単価 |
|---|---|---|
| 初級 | kubectl操作、Pod/Service管理 | 55〜65万円 |
| 中級 | 監視設計、CI/CD構築、スケーリング | 65〜85万円 |
| 上級 | 障害対応自動化、マルチクラスタ管理 | 85〜110万円 |
まとめ:OpenClawでKubernetes運用を自動化しよう
OpenClawは、Kubernetesの運用自動化を実現する強力な基盤です。Cronジョブによる定期監視、スキルベースの障害検出・復旧、AIによるスケーリング最適化提案、そしてSlackへの適切な通知——これらを組み合わせることで、24時間365日の運用監視を少人数で実現できます。
SESエンジニアとして、K8sの運用自動化スキルは高単価案件への近道です。OpenClawを活用して実践的な運用ノウハウを身につけましょう。
OpenClawの基本はOpenClaw AIアシスタントガイドを、監視設計は監視アラートガイドをご覧ください。CronジョブはCronスケジューリングガイド、Slack連携はSlack/Discord連携ガイドが参考になります。





