
「深夜3時にアラートが鳴り、眠い目をこすりながらSlackとダッシュボードを交互に確認する」——そんな経験、エンジニアなら誰もが持っているはずです。障害対応は属人化しやすく、対応速度もオンコール担当者のスキルや状況に大きく左右されます。
OpenClawを使えば、インシデント対応の検知から初動対応・エスカレーション・ポストモーテム作成までを一貫して自動化できます。 この記事では、実際の設定例を交えながら、OpenClawによるインシデント対応自動化の全体像を解説します。
この記事を3秒でまとめると
- OpenClawはWebhookで監視ツールと連携し、アラートを自動受信できる
- AIトリアージで重要度判定・ナレッジ照合を自動化し、初動を高速化
- Slack通知・自動復旧・ポストモーテム生成まで一貫してカバー
OpenClawによるインシデント対応自動化の全体像
インシデント対応の自動化というと、「単純な通知転送」を思い浮かべる方も多いでしょう。しかしOpenClawが提供するのは、AIエージェントが文脈を理解しながら動くワークフローです。単なるアラートルーティングを超えた、インテリジェントなインシデント対応基盤を構築できます。
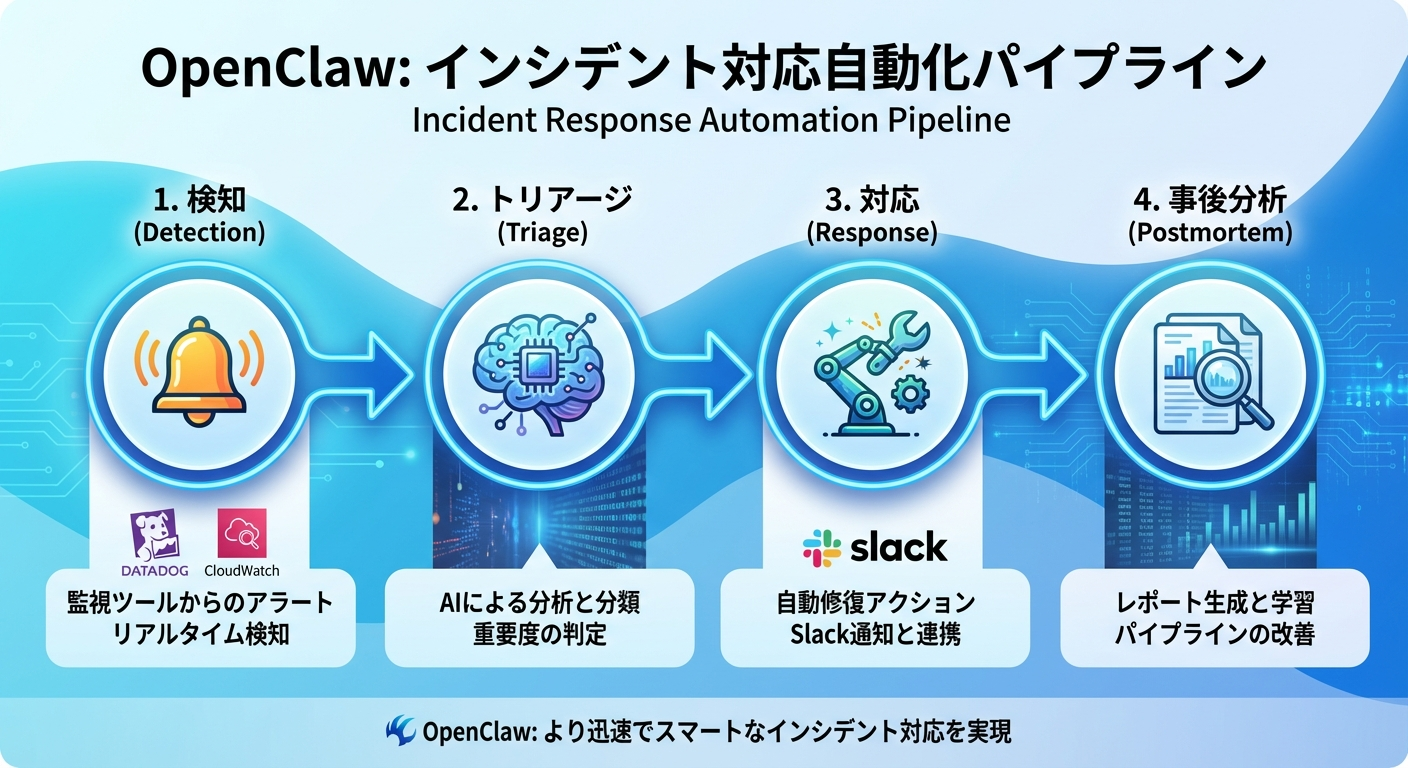
検知 → トリアージ → 対応 → 振り返りの4フェーズ
OpenClawによる自動化は、以下の4フェーズで構成されます。
- 検知(Detection): CloudWatch / Datadog / GrafanaなどのWebhookでアラートを受信
- トリアージ(Triage): AI が重要度・影響範囲を判定し、対応優先度を決定
- 対応(Response): 自動復旧スクリプト実行、担当者へのエスカレーション
- 振り返り(Retrospective): インシデントタイムラインから自動でポストモーテムを生成
この流れを自動化することで、平均応答時間(MTTR)を大幅に短縮できます。Atlassianの調査によれば、インシデント対応の自動化により平均解決時間が最大40%削減されるケースも報告されています(Atlassian State of Incident Management)。
従来のPagerDuty/OpsGenieとの使い分け
PagerDutyやOpsGenieは「誰に通知するか」のルーティングに優れたツールです。一方OpenClawは、「どう対応するか」をAIが判断・実行できる点が差別化ポイントです。
| 比較項目 | PagerDuty / OpsGenie | OpenClaw |
|---|---|---|
| アラートルーティング | ◎ 強力 | ○ 対応可 |
| AI判断・自動対応 | △ 限定的 | ◎ 柔軟に定義可 |
| ポストモーテム生成 | △ テンプレート | ◎ AI自動生成 |
| カスタマイズ性 | △ SaaS制約あり | ◎ コードで自由定義 |
| コスト | 高め(人数課金) | ツール単体は低コスト |
実際の運用では「PagerDutyで通知し、OpenClawで初動対応を自動化する」という組み合わせも有効です。
アラート検知とWebhook連携
OpenClawのインシデント対応自動化の起点は、外部監視ツールからのWebhook受信です。HTTP POSTでアラートを受け取り、AIエージェントがその内容を解析します。
CloudWatch / Datadog / Grafanaからのアラート受信
主要な監視ツールはすべてWebhook通知に対応しています。OpenClawのHooksエンドポイントに向けて設定するだけで、アラート内容をリアルタイムに受け取れます。
各ツールの設定ポイント:
- Amazon CloudWatch: SNSトピック経由でHTTPエンドポイントに転送。CloudWatch Alarmのアクションにサブスクリプション確認が必要
- Datadog: Webhooksインテグレーションから
@webhook-openclawのメンションで送信 - Grafana: アラートルールのContact PointにWebhook URLを設定
受信するペイロードには、アラート名・ステータス・メトリクス値・タイムスタンプなどが含まれます。OpenClawはこれらを自動でパースし、次のトリアージフェーズに渡します。
OpenClaw Hooksの設定と認証
Hooksの設定は openclaw.json で管理します。
設定例(openclaw.json):
{
"hooks": {
"incident-alert": {
"path": "/hooks/incident",
"secret": "your-webhook-secret",
"agent": "incident-responder",
"enabled": true
}
}
}認証は HMAC-SHA256署名検証 を推奨します。送信元ツールで共有シークレットを設定し、OpenClaw側でリクエストの正当性を確認することで、不正なWebhook実行を防げます。
セキュリティ上、Webhookエンドポイントは外部公開が必要です。VPN経由またはCloudflare Tunnelを使った安全な公開方法を検討しましょう。詳細は OpenClaw Webhook API連携 をご参照ください。
AIによる自動トリアージ
アラートを受信したら、次はAIによるトリアージです。人間なら「このアラート、また誤報かな?」と過去の経験で判断するところを、OpenClawはナレッジベースと照合しながら自動で重要度を判定します。
アラート内容のパースと重要度判定
OpenClawのAIエージェントはアラートペイロードから以下を抽出・判定します。
- 影響サービス: どのサービス・コンポーネントが対象か
- 重要度スコア: Critical / High / Medium / Low の4段階
- 想定原因カテゴリ: インフラ障害 / アプリエラー / 外部依存 / 誤報の分類
- 推奨アクション: 再起動、スケールアウト、調査継続など
重要度判定では、アラートの頻度・時間帯・影響ユーザー数なども加味します。例えば「深夜の非クリティカルサービスのエラー率2%上昇」は高優先度にしない、といった判断ができます。
過去のインシデントナレッジベースとの照合
OpenClawはインシデント対応履歴をナレッジベースとして蓄積します。新しいアラートが来ると、類似インシデントを検索し、過去の解決方法を自動的に提示します。
ナレッジベースに蓄積されるデータ:
- インシデントのタイトルと根本原因
- 適用した対応手順と結果
- 解決に要した時間
- 関連するRunbookへのリンク
これにより、初めてオンコールに入るエンジニアでも、AIのサポートを受けながら適切な初動対応が取れるようになります。詳しくは OpenClaw AIアシスタントガイド もご参照ください。
自動復旧アクションの実装
トリアージで「自動対応可能」と判断されたインシデントは、エージェントが自律的に復旧アクションを実行します。
サービス再起動・スケールアウトの自動実行
よくある自動復旧アクションの例:
- ECSサービスの強制デプロイ: タスクのメモリ/CPU超過時に自動再起動
- Auto Scalingのスケールアウト: CPU使用率80%超過が5分継続したらEC2を追加
- Redis/DBコネクションのリセット: 接続プールの枯渇時に自動クリーンアップ
- CDNキャッシュのパージ: コンテンツ配信異常時にCloudFrontキャッシュを削除
OpenClawのSkills(スキル)として各アクションを定義しておくと、AIが状況に応じて適切なスキルを選択・実行できます。
ロールバック判断のガードレール設定
自動対応で最も慎重にすべきなのがロールバックです。誤ったロールバックは障害を悪化させることがあります。OpenClawでは以下のガードレールを設定できます。
ガードレール設定例:
- エラー率が 5%以上 かつ 10分以上継続 している場合のみロールバックを許可
- 直近 1時間以内 にデプロイがあった場合に限定
- ロールバック実行前に Slackで承認リクエスト を送信(30分応答なしで自動実行)
- 本番環境では必ず人間の承認を必須とする
「AIが勝手に動く」ことへの不安は当然です。ガードレール設定により、「AIが判断し、人間が承認する」ハイブリッドモデルで運用できます。詳しくは OpenClaw監視アラートガイド をご覧ください。
エスカレーションとSlack通知
自動対応で解決できないインシデントは、適切な担当者にエスカレーションします。OpenClawはSlackと深く連携し、状況に応じた通知ルーティングを実現します。
チャンネル別通知ルーティング
インシデントの重要度や種類によって、通知先チャンネルを自動で振り分けます。
| 重要度 | 通知先チャンネル | 内容 |
|---|---|---|
| Critical | #incidents-critical | 詳細情報+即時対応依頼 |
| High | #incidents-high | 概要+担当者メンション |
| Medium | #incidents-medium | サマリー通知のみ |
| Low | #monitoring-log | ログ記録のみ |
各通知には、インシデントの概要・推定影響範囲・AIが推奨するアクション・関連Runbookリンクが自動で含まれます。
オンコール担当者への段階的エスカレーション
応答がない場合の段階的エスカレーションも自動化できます。
- T+0分: Slackの #incidents チャンネルに通知
- T+5分: オンコール担当者に直接DM
- T+15分: チームリーダーにエスカレーション
- T+30分: マネージャーへ通知、インシデントブリッジ開設
PagerDutyとのインテグレーションにより、既存のオンコールスケジュールを参照しながら適切な担当者を特定することも可能です。OpenClaw Slack/Discord連携 で詳しい設定方法を解説しています。
ポストモーテムの自動生成
インシデント収束後、OpenClawはタイムラインから自動でポストモーテムドラフトを生成します。
自動生成されるポストモーテムの構成:
- インシデント概要: 発生日時・影響範囲・解決時刻
- タイムライン: 検知から解決まで、各アクションの時系列記録
- 根本原因分析(5 Whys): AIが推定した根本原因の連鎖
- 対応の振り返り: 良かった点・改善点の自動抽出
- 再発防止策: 類似インシデントの防止に向けたアクションアイテム
これにより、インシデント収束直後の疲弊した状態での振り返り作業が大幅に軽減されます。ドラフトをチームでレビューし、必要に応じて加筆するだけで、品質の高いポストモーテムが完成します。
ポイント: ポストモーテムはNotionやConfluenceへの自動投稿も可能です。インシデント対応からドキュメント化まで、一連のフローをノーコードで構築できます。
まとめ
OpenClawによるインシデント対応自動化のポイントをまとめます。
- Webhook連携: CloudWatch / Datadog / GrafanaからのアラートをリアルタイムでAIが受信
- AIトリアージ: 重要度判定とナレッジベース照合で初動を高速化
- 自動復旧: ガードレール付きで安全な自動復旧アクションを実行
- エスカレーション: Slack通知と段階的エスカレーションで応答漏れを防止
- ポストモーテム: インシデント収束後の振り返りをAIが自動生成
インシデント対応の自動化は、エンジニアの夜間対応負荷を減らし、より創造的な仕事に集中できる環境を作ります。まずは小さなアラートから自動化を始め、徐々にカバー範囲を広げていくアプローチが現実的です。
SES BASE でOpenClaw活用エンジニアを探しているなら
DevOps・SRE案件でOpenClawやインフラ自動化の経験を持つエンジニアをお探しの方は、ぜひ SES BASE をご活用ください。OpenClaw・Terraform・Ansibleなどの自動化ツールに精通したエンジニアとのマッチングを支援します。





