
「競合の動向を毎日チェックしたいけど、手動でやると1時間以上かかる」「技術トレンドを追いたいけど、RSSリーダーを開く習慣が続かない」——情報収集の重要性は理解しているものの、時間と労力がネックで継続できないという声はよく聞きます。
OpenClawの自律リサーチエージェントを構築すれば、Web検索・情報収集・分析・レポート生成までを完全に自動化できます。 一度設定すれば、毎日決まった時間に最新情報を収集し、要約レポートをSlackやDiscordに自動配信してくれます。
この記事では、リサーチエージェントのアーキテクチャ設計からスキル実装、Cronジョブでの定期実行設定まで実践的に解説します。
この記事を3秒でまとめると
- OpenClawでWeb検索→分析→レポート生成→配信を完全自動化できる
- スキルファイル(SKILL.md)とCronジョブの組み合わせで定期実行を実現
- RSS・API・SNSなどマルチソースからの情報統合も可能
リサーチエージェントとは? — 情報収集の完全自動化
手動リサーチの限界とAIエージェントの優位性
手動での情報収集には以下の限界があります。
- 時間コスト: 複数サイトの巡回、要約作成に毎日1〜2時間
- 見落とし: 人間は疲れると情報を見落とす
- 一貫性: 忙しい日はサボりがち、データの欠損が起きる
- スケーラビリティ: ソース数が増えると対応しきれない
AIエージェントなら、これらの問題をすべて解決できます。24時間365日、一貫した品質で情報を収集し続けられます。
OpenClawが適している理由
リサーチエージェントのプラットフォームとしてOpenClawが適している理由は以下の通りです。
- Web検索ツールが標準装備: web_search / web_fetchで即座にWeb情報を取得可能
- Cronジョブ機能: 定期実行を簡単に設定できる
- メッセージング連携: Slack / Discord / Telegramへの自動配信
- スキルシステム: 再利用可能なリサーチロジックをパッケージ化できる
- メモリシステム: 過去の調査結果を蓄積し、トレンド分析に活用できる
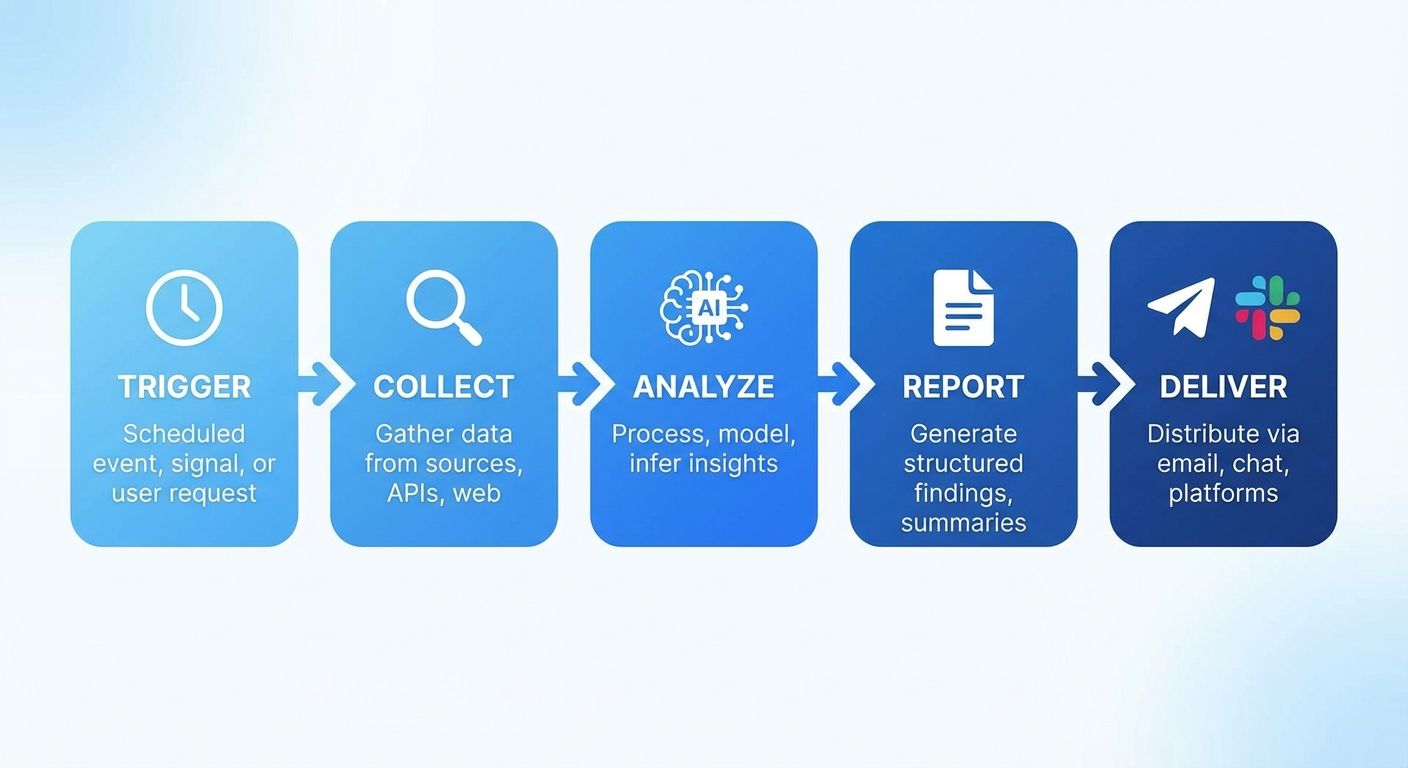
リサーチエージェントのアーキテクチャ設計
トリガー → 収集 → 分析 → レポート → 配信の5段階
リサーチエージェントは以下の5段階で動作します。
Stage 1: トリガー
- Cronジョブによる定期実行(毎日9時、毎週月曜等)
- 手動トリガー(Slackコマンド等)
- イベント駆動(特定のキーワードがSNSでトレンド入り等)
Stage 2: 収集
- Web検索(Google検索)
- RSS/Atomフィードの取得
- APIからのデータ取得(GitHub API、Twitter API等)
- Webスクレイピング(特定サイトの定点観測)
Stage 3: 分析
- 収集した情報の重複排除
- 重要度のスコアリング
- カテゴリ分類
- 過去データとの差分検出
Stage 4: レポート生成
- マークダウン形式のレポート作成
- チャート・グラフの生成(必要に応じて)
- エグゼクティブサマリーの作成
Stage 5: 配信
- Slack / Discord チャンネルへの自動投稿
- メール送信
- ファイル保存(daily report as markdown)
スキル構成とツール選定
リサーチエージェントで使用するOpenClawの主要ツールは以下の通りです。
| ツール | 用途 |
|---|---|
| web_search | キーワード検索による情報収集 |
| web_fetch | 特定URLからのコンテンツ取得 |
| exec(curl等) | API呼び出し、RSSフィード取得 |
| Write | レポートファイルの保存 |
| message | Slack/Discordへの配信 |
| memory_search | 過去の調査結果との照合 |
| cron | 定期実行の設定 |
実装ステップ
①スキルファイルの作成(SKILL.md + スクリプト)
リサーチスキルのディレクトリ構成:
~/.openclaw/skills/research-agent/
├── SKILL.md # スキル定義
├── scripts/
│ ├── fetch_rss.sh # RSSフィード取得
│ └── parse_news.py # ニュース解析
└── templates/
└── report.md # レポートテンプレートSKILL.mdの例:
# Research Agent Skill
## 概要
定期的にWebから情報を収集し、分析レポートを生成するスキル。
## トリガー
「リサーチ」「情報収集」「競合分析」「トレンド調査」等のキーワードで起動。
## 手順
1. 対象ソースから情報を収集(web_search + web_fetch)
2. 収集した情報を分析・要約
3. レポートをマークダウン形式で生成
4. 指定チャンネルに配信
## 設定
- 検索キーワード: workspace/research-config.json で定義
- レポート保存先: workspace/reports/YYYY-MM-DD.md②Web検索・スクレイピングの設定
OpenClawのweb_searchツールを活用した効率的な情報収集の設定例:
// workspace/research-config.json
{
"topics": [
{
"name": "SES業界動向",
"queries": [
"SES エンジニア 市場動向 2026",
"IT人材派遣 最新ニュース",
"フリーランスエンジニア 単価 トレンド"
],
"sources": ["https://www.ipa.go.jp/", "https://www.meti.go.jp/"],
"frequency": "daily"
},
{
"name": "AI技術トレンド",
"queries": [
"AIコーディングツール 新機能",
"LLM 開発 最新動向",
"GitHub Copilot Claude Code 比較"
],
"frequency": "daily"
}
],
"output": {
"format": "markdown",
"max_items_per_topic": 10,
"include_summary": true
}
}③レポートテンプレートの定義
レポートの品質を安定させるために、テンプレートを用意します。
<!-- templates/report.md -->
# 📊 デイリーリサーチレポート — {{date}}
## 📌 エグゼクティブサマリー
{{summary}}
## 🔍 トピック別詳細
{{#each topics}}
### {{name}}
{{#each items}}
- **[{{title}}]({{url}})** — {{source}} ({{published}})
> {{excerpt}}
{{/each}}
{{/each}}
## 📈 注目トレンド
{{trends}}
## 💡 アクションアイテム
{{action_items}}④Cronジョブでの定期実行設定
OpenClawのCron機能で毎朝9時に自動実行する設定:
// Cronジョブの設定
{
"name": "daily-research",
"schedule": {
"kind": "cron",
"expr": "0 9 * * *",
"tz": "Asia/Tokyo"
},
"payload": {
"kind": "agentTurn",
"message": "研究テーマに基づいて本日のリサーチを実行してください。research-config.jsonの設定に従い、情報収集→分析→レポート生成→配信を行ってください。"
},
"sessionTarget": "isolated",
"delivery": {
"mode": "announce",
"channel": "#research-reports"
}
}マルチソース対応 — RSS・API・SNSからの情報統合
リサーチの精度を上げるために、複数のソースから情報を統合することが重要です。
RSSフィード:
# scripts/fetch_rss.sh
#!/bin/bash
feeds=(
"https://www.publickey1.jp/atom.xml"
"https://zenn.dev/feed"
"https://dev.to/feed"
)
for feed in "${feeds[@]}"; do
curl -s "$feed" | python3 scripts/parse_rss.py >> /tmp/rss_items.json
doneGitHub API(トレンドリポジトリ):
# GitHub Trending APIからの情報取得
curl -s "https://api.github.com/search/repositories?q=stars:>1000+created:>$(date -v-7d +%Y-%m-%d)&sort=stars&order=desc" \
-H "Authorization: Bearer $GITHUB_TOKEN"SNS(X/Twitter): OpenClawのweb_searchツールでSNS上の議論を検索できます。特定のハッシュタグやアカウントの発言をモニタリングする設定も可能です。
Slack/Discord連携でレポート自動配信
生成したレポートは、OpenClawのメッセージング機能で自動配信します。
配信時のフォーマット最適化ポイント:
- Slackの場合: Block Kit形式でリッチなレイアウトを使う
- Discordの場合: Embedメッセージで見やすく表示
- 共通: 長いレポートは要約のみチャンネルに投稿し、詳細はリンク(Notion等)に誘導
配信スケジュールの工夫:
- 朝9時: デイリーレポート(前日の動向まとめ)
- 月曜10時: ウィークリーダイジェスト(週間トレンド分析)
- 月初: 月次レポート(月間サマリー + 来月の注目テーマ)
実用例:競合分析・技術トレンド・求人市場の自動監視
競合分析エージェント
競合企業のWebサイト更新、プレスリリース、採用情報の変化を自動監視します。
- 競合サイトの新着ページを定点観測
- プレスリリースの要約と分類
- 求人情報の変化から事業戦略を推測
技術トレンドウォッチャー
特定の技術領域の最新動向を自動追跡します。
- GitHub Trending / Hacker News / Reddit からの情報収集
- 新しいライブラリ・フレームワークのリリース検知
- カンファレンス発表資料の自動収集
GitHub公式ドキュメントのAPIを活用して、スター数の急増するリポジトリを早期にキャッチすることも可能です。
求人市場モニター
SES案件の市場動向を自動追跡します。
- 求人サイトの新着案件数の推移
- スキル別の求人数・単価の変動
- 需要が増加しているテクノロジーの検出
まとめ — リサーチを自動化して意思決定を高速化
OpenClawのリサーチエージェントで実現できることを振り返ります。
- 情報収集の完全自動化: 毎日のルーティンを0時間に削減
- マルチソース統合: Web・RSS・API・SNSから網羅的に収集
- 分析の一貫性: AIが毎回同じ基準で分析するため、バイアスが少ない
- 即座の配信: 収集→分析→配信までタイムラグなし
- トレンド検出: 過去データとの差分から変化を早期にキャッチ
情報は意思決定の原材料です。情報収集を自動化することで、人間はその情報を「どう使うか」という本質的な判断に集中できるようになります。
まずは一つのテーマ(例: 自分の技術領域のトレンド)から始めて、徐々にスコープを広げていくことをおすすめします。
SES BASEでは、AI・自動化スキルを活かせる案件も多数掲載しています。
関連記事:





