
- OpenClawのcronジョブ+カスタムスキルでAPI監視パイプラインを完全自動化
- LLMの推論力で「ステータス200だが実質エラー」のような従来ツールでは検出困難な異常を発見
- Datadog等の高額SaaSを使わずに、SES現場で即導入できる監視基盤を構築
「APIのレスポンスが遅くなっているのに気づけなかった」「ステータスコードは200だが、レスポンスボディが空になっていた」「外部APIの仕様変更でフロントが壊れていたが、3時間気づかなかった」——SES現場のインシデント報告で頻繁に見かける事象です。
2026年現在、マイクロサービスアーキテクチャの普及により、1つのアプリケーションが依存するAPIエンドポイントは平均15〜30にのぼります。すべてを手動で監視するのは現実的ではありません。
OpenClawを使えば、AIエージェントによるインテリジェントなAPI監視を、DatadogやNew Relicのような高額SaaSなしで構築できます。本記事では、エンドポイント監視からレスポンス検証、パフォーマンス計測、アラート通知まで、SES現場で即導入できるAPI監視基盤の構築方法を解説します。
API監視におけるOpenClawの優位性
従来の監視ツールとの違い
| 項目 | 従来ツール(UptimeRobot等) | OpenClaw API監視 |
|---|---|---|
| 監視対象 | ステータスコードのみ | ステータスコード+レスポンスボディの内容検証 |
| 異常検知 | 固定閾値 | LLMによるコンテキスト理解 |
| レポート | 定型フォーマット | 自然言語での異常説明 |
| コスト | $7〜29/月 | OpenClaw+LLM APIの従量課金のみ |
| カスタマイズ | 限定的 | スキルとして自由に拡張可能 |
| 障害対応 | アラート通知のみ | 初動対応の自動実行が可能 |
OpenClawが解決する「見えない障害」
従来の監視ツールでは検出が難しい問題パターン:
- ステータス200、レスポンス空: APIが正常応答を返すが、データが空
- レスポンス時間の緩やかな劣化: 100ms → 200ms → 500ms と徐々に悪化
- 部分的なデータ欠損: 10件返るはずのリストが3件だけ
- フォーマット変更: APIの仕様変更でフィールド名が変わった
- 証明書の有効期限切れ予兆: 残り30日以下で警告
実践①:基本的なAPIヘルスチェック
監視スキルの作成
まず、OpenClawのカスタムスキルとしてAPI監視機能を実装します:
<!-- ~/.openclaw/skills/api-monitor/SKILL.md -->
# API Monitor Skill
## 概要
APIエンドポイントの死活監視・レスポンス検証を行うスキル。
## 監視設定ファイル
`~/.openclaw/skills/api-monitor/endpoints.json` に監視対象を定義。
## 監視項目
1. HTTPステータスコード
2. レスポンス時間(ms)
3. レスポンスボディの構造検証
4. SSL証明書の有効期限エンドポイント設定ファイル
{
"endpoints": [
{
"name": "Main API",
"url": "https://api.example.com/v1/health",
"method": "GET",
"interval": "5m",
"timeout": 10000,
"expectedStatus": 200,
"expectedBody": {
"status": "ok"
},
"maxResponseTime": 2000,
"headers": {
"Authorization": "Bearer ${API_TOKEN}"
}
},
{
"name": "User Service",
"url": "https://api.example.com/v1/users?limit=1",
"method": "GET",
"interval": "10m",
"timeout": 5000,
"expectedStatus": 200,
"responseValidation": {
"type": "json",
"rules": [
{ "path": "$.data", "type": "array", "minLength": 1 },
{ "path": "$.data[0].id", "type": "string" },
{ "path": "$.meta.total", "type": "number", "min": 0 }
]
}
},
{
"name": "Payment Gateway",
"url": "https://payment.example.com/api/status",
"method": "POST",
"interval": "3m",
"timeout": 15000,
"expectedStatus": 200,
"body": { "test": true },
"critical": true,
"alertChannels": ["slack", "pagerduty"]
}
],
"defaults": {
"interval": "5m",
"timeout": 10000,
"retries": 2,
"retryDelay": 3000
}
}監視スクリプトの実装
#!/bin/bash
# ~/.openclaw/skills/api-monitor/check.sh
# APIヘルスチェック実行スクリプト
set -euo pipefail
ENDPOINTS_FILE="$(dirname "$0")/endpoints.json"
LOG_DIR="$HOME/.openclaw/logs/api-monitor"
mkdir -p "$LOG_DIR"
check_endpoint() {
local name="$1"
local url="$2"
local method="${3:-GET}"
local timeout="${4:-10}"
local expected_status="${5:-200}"
local start_time=$(date +%s%N)
local response
local http_code
response=$(curl -s -w "\n%{http_code}\n%{time_total}" \
-X "$method" \
--max-time "$timeout" \
"$url" 2>/dev/null) || true
local end_time=$(date +%s%N)
local elapsed=$(( (end_time - start_time) / 1000000 ))
http_code=$(echo "$response" | tail -1)
local time_total=$(echo "$response" | tail -2 | head -1)
local body=$(echo "$response" | sed '$d' | sed '$d')
local status="OK"
local details=""
if [ "$http_code" != "$expected_status" ]; then
status="FAIL"
details="Expected status $expected_status, got $http_code"
elif [ "$elapsed" -gt 2000 ]; then
status="SLOW"
details="Response time: ${elapsed}ms (threshold: 2000ms)"
fi
echo "{\"name\":\"$name\",\"url\":\"$url\",\"status\":\"$status\",\"http_code\":$http_code,\"response_time_ms\":$elapsed,\"details\":\"$details\",\"timestamp\":\"$(date -u +%Y-%m-%dT%H:%M:%SZ)\"}"
}
# 実行結果をログに追記
RESULTS="[]"
while IFS= read -r endpoint; do
name=$(echo "$endpoint" | jq -r '.name')
url=$(echo "$endpoint" | jq -r '.url')
method=$(echo "$endpoint" | jq -r '.method // "GET"')
result=$(check_endpoint "$name" "$url" "$method")
echo "$result" >> "$LOG_DIR/$(date +%Y-%m-%d).jsonl"
echo "$result"
done < <(jq -c '.endpoints[]' "$ENDPOINTS_FILE")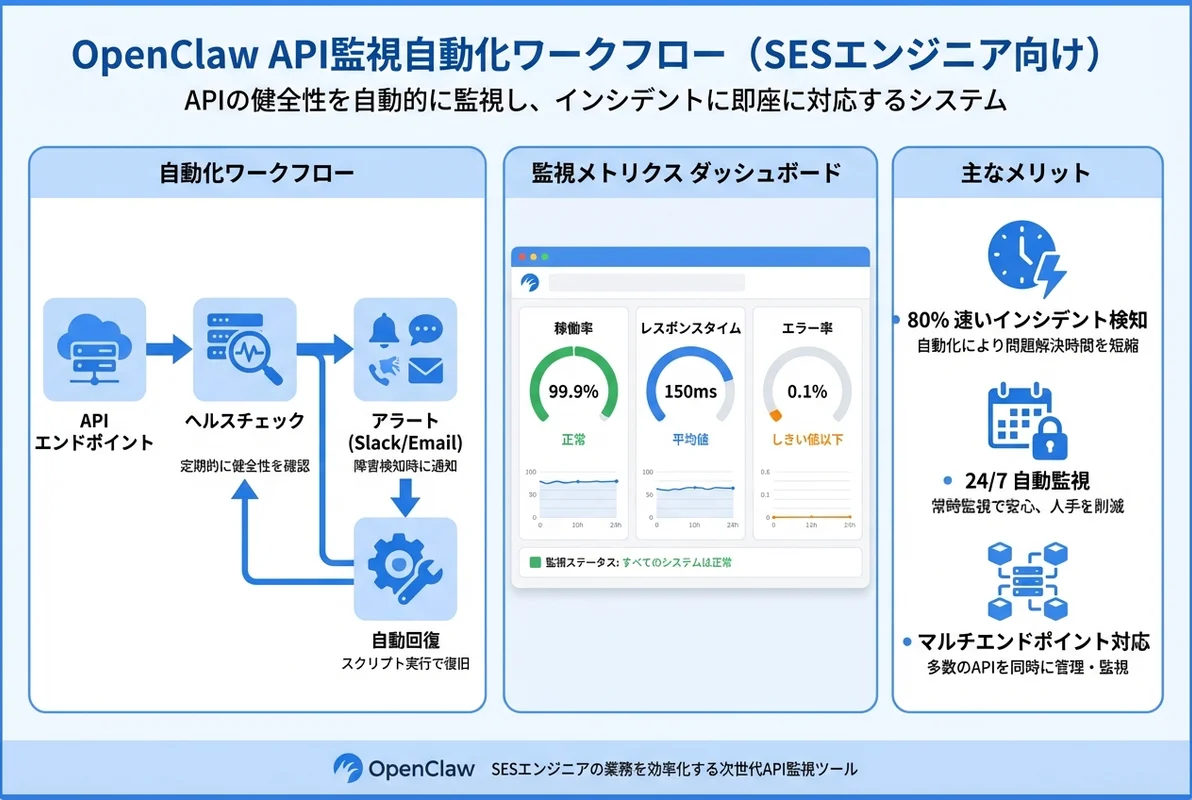
実践②:LLMによるインテリジェントなレスポンス検証
コンテキスト理解に基づく異常検知
OpenClawの最大の強みは、LLMにレスポンスの意味的な分析をさせられる点です。これにより、従来の固定ルールでは検出できない異常を発見できます。
## API監視 - レスポンス分析プロンプト
以下のAPIレスポンスを分析し、異常がないか判定してください:
### エンドポイント情報
- URL: {url}
- 期待されるレスポンス: ユーザー一覧(通常10〜50件)
- 前回のレスポンス要約: {previous_summary}
### 今回のレスポンス
```json
{response_body}判定基準
- データの整合性(IDの形式、必須フィールドの存在)
- データ量の妥当性(前回比で大幅な増減がないか)
- レスポンス構造の変更(フィールドの追加・削除・型変更)
- ビジネスロジック上の異常(マイナスの金額、未来の日付等)
出力形式
- status: “normal” | “warning” | “critical”
- findings: 発見した問題のリスト
- recommendation: 推奨アクション
### 実際の活用例:ECサイトのAPI監視
```bash
# cronジョブで5分ごとに実行
# openclaw.json の cron 設定例
{
"cron": [
{
"schedule": "*/5 * * * *",
"command": "API監視チェックを実行してください。endpoints.jsonに基づいてすべてのエンドポイントをチェックし、異常があればSlack #alerts に通知してください。",
"skill": "api-monitor"
}
]
}実践③:パフォーマンストレンド分析
レスポンスタイムの推移追跡
単純な閾値チェックだけでなく、レスポンスタイムの推移をトレンド分析することで、障害の予兆を検知します:
// パフォーマンストレンド分析スクリプト
const fs = require('fs');
const path = require('path');
function analyzeTrend(logDir, endpointName, days = 7) {
const results = [];
for (let i = 0; i < days; i++) {
const date = new Date();
date.setDate(date.getDate() - i);
const logFile = path.join(logDir, `${date.toISOString().split('T')[0]}.jsonl`);
if (fs.existsSync(logFile)) {
const lines = fs.readFileSync(logFile, 'utf8').split('\n').filter(Boolean);
for (const line of lines) {
const entry = JSON.parse(line);
if (entry.name === endpointName) {
results.push({
timestamp: entry.timestamp,
responseTime: entry.response_time_ms,
status: entry.status,
});
}
}
}
}
if (results.length < 10) return null;
// 移動平均の計算
const windowSize = 10;
const movingAvg = [];
for (let i = windowSize; i < results.length; i++) {
const window = results.slice(i - windowSize, i);
const avg = window.reduce((sum, r) => sum + r.responseTime, 0) / windowSize;
movingAvg.push({ timestamp: results[i].timestamp, avg });
}
// トレンド検出(線形回帰)
const n = movingAvg.length;
const xMean = (n - 1) / 2;
const yMean = movingAvg.reduce((sum, p) => sum + p.avg, 0) / n;
let numerator = 0;
let denominator = 0;
for (let i = 0; i < n; i++) {
numerator += (i - xMean) * (movingAvg[i].avg - yMean);
denominator += (i - xMean) ** 2;
}
const slope = numerator / denominator;
const percentChange = (slope * n) / yMean * 100;
return {
endpoint: endpointName,
dataPoints: results.length,
avgResponseTime: Math.round(yMean),
trend: slope > 0 ? 'increasing' : 'decreasing',
percentChange: Math.round(percentChange * 10) / 10,
alert: percentChange > 30 ? 'DEGRADATION_WARNING' : 'OK',
};
}実践④:Slackアラート通知
アラートのフォーマットと通知ロジック
OpenClawのmessageツールを使って、構造化されたアラートを送信します:
## アラート通知テンプレート
### Critical アラート
🚨 **API障害検知**
- エンドポイント: {name} ({url})
- ステータス: {http_code} (期待値: {expected_status})
- レスポンスタイム: {response_time_ms}ms
- 検知時刻: {timestamp}
- 詳細: {details}
### Warning アラート
⚠️ **APIパフォーマンス劣化**
- エンドポイント: {name}
- 平均レスポンスタイム: {avg_response_time}ms → {current_response_time}ms
- 変化率: +{percent_change}%(過去7日比)
- 推奨: {recommendation}エスカレーションポリシー
{
"escalation": {
"levels": [
{
"delay": 0,
"channel": "slack",
"target": "#alerts",
"severity": ["critical", "warning"]
},
{
"delay": 300,
"channel": "slack",
"target": "#oncall",
"severity": ["critical"],
"message": "5分経過しても復旧していません。エスカレーションします。"
},
{
"delay": 900,
"channel": "slack",
"target": "@oncall-engineer",
"severity": ["critical"],
"message": "15分経過。即時対応が必要です。"
}
],
"recovery": {
"channel": "slack",
"target": "#alerts",
"message": "✅ {name} が復旧しました(ダウンタイム: {downtime})"
}
}
}実践⑤:SSL証明書の有効期限監視
証明書の自動チェック
Let’s Encryptの自動更新が失敗するケースは意外と多く、SSL証明書切れは深刻なインシデントにつながります:
#!/bin/bash
# SSL証明書の有効期限チェック
check_ssl() {
local domain="$1"
local warning_days="${2:-30}"
local expiry_date
expiry_date=$(echo | openssl s_client -servername "$domain" -connect "$domain":443 2>/dev/null | \
openssl x509 -noout -enddate 2>/dev/null | cut -d= -f2)
if [ -z "$expiry_date" ]; then
echo "{\"domain\":\"$domain\",\"status\":\"ERROR\",\"message\":\"Could not retrieve certificate\"}"
return
fi
local expiry_epoch=$(date -j -f "%b %d %T %Y %Z" "$expiry_date" +%s 2>/dev/null || \
date -d "$expiry_date" +%s 2>/dev/null)
local now_epoch=$(date +%s)
local days_left=$(( (expiry_epoch - now_epoch) / 86400 ))
local status="OK"
if [ "$days_left" -le 7 ]; then
status="CRITICAL"
elif [ "$days_left" -le "$warning_days" ]; then
status="WARNING"
fi
echo "{\"domain\":\"$domain\",\"status\":\"$status\",\"days_left\":$days_left,\"expiry\":\"$expiry_date\"}"
}
# 監視対象ドメイン
DOMAINS=("api.example.com" "app.example.com" "admin.example.com")
for domain in "${DOMAINS[@]}"; do
check_ssl "$domain"
done実践⑥:ダッシュボードとレポート生成
日次レポートの自動生成
OpenClawのcronジョブで毎朝レポートを生成し、Slackに投稿します:
## 日次API監視レポート - {date}
### サマリー
- 監視エンドポイント数: {total_endpoints}
- 正常: {ok_count} / 警告: {warning_count} / 障害: {critical_count}
- 平均レスポンスタイム: {avg_response_time}ms
- SLA達成率: {sla_percent}%
### パフォーマンス推移
| エンドポイント | 昨日平均 | 今日平均 | 変化 |
|:---|:---:|:---:|:---:|
| Main API | 120ms | 135ms | +12.5% |
| User Service | 85ms | 82ms | -3.5% |
| Payment Gateway | 200ms | 450ms | +125% ⚠️ |
### インシデント
1. 08:15 - Payment Gateway レスポンス遅延(450ms → 復旧 08:22)
2. 14:30 - User Service 一時的な500エラー(1回のみ、自動復旧)
### 推奨アクション
- Payment Gateway のレスポンスタイムが悪化傾向。DB接続プールの確認を推奨。
- SSL証明書 (api.example.com) の有効期限まで残り25日。更新の確認を。SES面談でのAPI監視スキルアピール
SRE/運用系の案件で評価されるポイント
インフラ・運用スキル
- 監視設計の経験(SLI/SLO/SLAの定義)
- アラート設計のベストプラクティス(アラート疲れの防止)
- インシデント対応フロー(検知 → 判断 → 対応 → 復旧 → 振り返り)
- オンコール体制の構築経験
ツール経験
- Datadog / New Relic / Grafana の利用経験
- PagerDuty / OpsGenie でのアラート管理
- Terraform / CloudFormation による監視インフラのIaC
コスト意識
- 監視SaaSのコスト最適化(不要なメトリクスの削減)
- OpenClawのような軽量ツールでの代替手法の提案能力
まとめ
OpenClawを活用したAPI監視は、従来の監視ツールの「ステータスコードチェック」を超えたインテリジェントな監視を実現します。
特に以下の点が、SES現場での導入メリットです:
- 低コスト: Datadog等の高額SaaSが不要(LLM APIの従量課金のみ)
- 柔軟性: カスタムスキルとして自由に監視ロジックを拡張可能
- インテリジェント: LLMによるレスポンスの意味的分析で、「見えない障害」を検知
- 運用自動化: アラート→初動対応まで一気通貫で自動化
SRE・DevOps領域のスキルは、2026年のSES市場で高い需要があります。OpenClawで効率的に監視基盤を構築しながら、実践的な運用スキルを磨いていきましょう。





