
「月に100本の記事を公開したいが、リソースが足りない」「品質を保ちながら量産する仕組みが欲しい」——コンテンツマーケティングに取り組む企業やメディアにとって、こうした課題は日常的です。
OpenClawのcronジョブ、サブエージェント、スキル機能を組み合わせれば、リサーチから公開までの全工程を自動化するコンテンツパイプラインを構築できます。
この記事では、実際に稼働しているAIコンテンツパイプラインの設計思想から具体的な実装方法まで、実践的に解説します。
AIコンテンツパイプラインとは?全体像を理解する
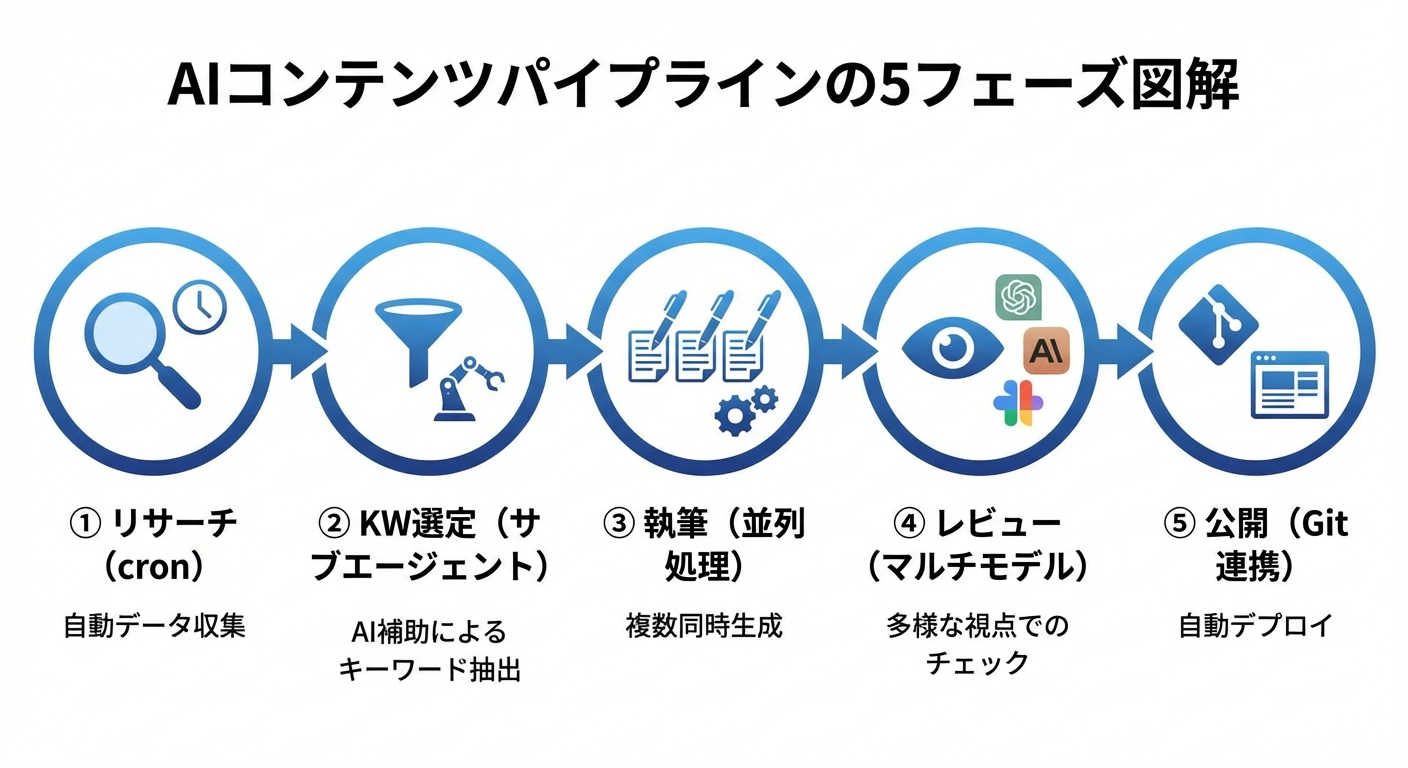
リサーチ→KW選定→執筆→レビュー→公開の5フェーズ
AIコンテンツパイプラインは、以下の5つのフェーズで構成されます。
| フェーズ | 内容 | OpenClawの機能 |
|---|---|---|
| ①リサーチ | 競合分析、トレンド調査、KW調査 | cronジョブ + web_search |
| ②KW選定 | 検索ボリューム・競合度の評価 | サブエージェント |
| ③執筆 | 構成案作成→本文執筆→画像生成 | sessions_spawn(並列) |
| ④レビュー | SEO・ファクト・文体チェック | マルチモデルレビュー |
| ⑤公開 | Git PR→マージ→デプロイ | GitHub連携 |
各フェーズは独立して動作し、前のフェーズの出力が次のフェーズの入力になるパイプライン構造です。
なぜOpenClawが適しているのか
OpenClawがコンテンツパイプラインに適している理由は以下の通りです。
- cronジョブ:定期的なリサーチを完全自動化
- sessions_spawn:複数記事の同時執筆が可能
- スキルファイル:品質基準をコードとして定義
- マルチモデル:タスクに応じて最適なモデルを使い分け
- GitHub連携:PR作成からマージまでを自動化
ワークフロー自動化ガイドでOpenClawの自動化の基本を学べます。
フェーズ①: Cronジョブで定期リサーチを自動化
記事テーマの自動リサーチとKW選定
Cronスケジューリングガイドで解説しているcron機能を使い、毎日定時に記事テーマのリサーチを実行します。
cronジョブの設定例:
{
"name": "daily-content-research",
"schedule": {
"kind": "cron",
"expr": "0 6 * * *",
"tz": "Asia/Tokyo"
},
"payload": {
"kind": "agentTurn",
"message": "今日の記事テーマをリサーチして構成案を作成してください"
},
"sessionTarget": "isolated"
}リサーチの自動化では、以下のソースからデータを収集します。
- Google検索トレンド:直近で急上昇しているキーワード
- 競合サイトの新着記事:web_fetchで定期チェック
- SNSのバズ投稿:X(旧Twitter)のエンゲージメント分析
- 業界ニュース:RSS/Atomフィードの監視
競合分析の組み込み
競合分析は、ターゲットキーワードの上位10記事を取得し、以下の観点で分析します。
- 記事の文字数・構成
- 使用されている見出しパターン
- 内部・外部リンクの構造
- E-E-A-T要素の有無
フェーズ②: サブエージェントによる記事執筆
sessions_spawnでの並列執筆
セッション・サブエージェントガイドで解説しているsessions_spawn機能を使えば、複数の記事を同時に執筆できます。
// 構成案を読み込み
const outlines = readFile("today-article-outlines.md");
// 各記事を並列で執筆
for (const outline of outlines) {
sessions_spawn({
task: `以下の構成案に基づいて記事を執筆:\n${outline}`,
runtime: "subagent",
mode: "run"
});
}並列実行のポイント:
- 各サブエージェントは独立したセッションで動作
- メモリやコンテキストの干渉がない
- 失敗した記事だけを個別にリトライ可能
スキルファイルによる品質統一
スキルファイルを定義することで、全てのサブエージェントが同じ品質基準で記事を執筆します。
# article-writing-skill.md
## 執筆ルール
- 3000-5000字/記事
- 導入文は結論ファースト
- H2ごとにKWを自然に配置
- 内部リンク3本以上
- 外部出典1つ以上フェーズ③: マルチモデルレビューパイプライン
SEOチェック・ファクトチェック・文体チェック
記事が完成したら、複数のモデルで異なる観点からレビューを行います。
| チェック項目 | 担当モデル | チェック内容 |
|---|---|---|
| SEO | 軽量モデル | KW密度、見出し構造、メタタグ |
| ファクト | 高精度モデル | 数値・法律・技術情報の正確性 |
| 文体 | 中間モデル | 読みやすさ、トーン統一、誤字脱字 |
人間レビューのフックポイント設計
完全自動化と言っても、人間によるレビューポイントを設計に組み込むことが品質担保の鍵です。
- ファクトチェック後:誤情報のリスクが高い記事にフラグ
- 公開前:最終確認としてSlack通知
- 公開後:アクセスデータに基づくフィードバック
フェーズ④: Git連携とデプロイ自動化
PR作成→承認→マージ→公開の自動フロー
GitHub PR自動化ガイドの知見を活用し、記事の公開フローを自動化します。
# ブランチ作成
git checkout -b articles/YYYY-MM-DD
# 記事ファイルを追加
git add apps/blog/src/content/articles/
# コミット&プッシュ
git commit -m "Add daily articles for YYYY-MM-DD"
git push origin articles/YYYY-MM-DD
# PR作成
gh pr create --title "Daily Articles: YYYY-MM-DD" --body "自動生成記事"承認フローの設計:
- 自動承認:バリデーションが全PASSなら自動マージ
- 手動承認:ファクトチェックでフラグが立った記事はレビュー待ち
運用のコツ|品質と量のバランス
コンテンツパイプラインの運用で最も重要なのは、品質と量のバランスです。
- 量より質:低品質な記事はSEOに悪影響。Google公式も「Helpful Content」を重視
- 定期的なA/Bテスト:タイトル、構成、CTAを比較検証
- フィードバックループ:アクセスデータを次の記事テーマに反映
- 人間の監修:AIが苦手な「現場感」「体験談」は人間が追加
マーケティング自動化パイプラインでマーケティング全体の自動化も確認しましょう。
実践事例:月間100記事パイプラインの設計
実際に月間100記事を公開しているパイプラインの設計例を紹介します。
日次スケジュール:
- 6:00 - cronでリサーチ・KW選定(自動)
- 7:00 - 構成案作成(自動)
- 7:30 - 8記事を並列執筆(自動)
- 9:00 - マルチモデルレビュー(自動)
- 10:00 - バリデーション&PR作成(自動)
- 11:00 - 人間レビュー&承認(手動)
- 12:00 - マージ&デプロイ(自動)
この設計で、平日5日×4記事/日 = 月80〜100記事を安定的に公開できます。
OpenClaw公式ドキュメント(出典:OpenClaw Documentation)も参照してください。
スキル開発ガイドでカスタムスキルの作り方を学べば、パイプラインをさらに高度にカスタマイズできます。
まとめ
OpenClawを使ったAIコンテンツパイプラインは、コンテンツマーケティングのスケーラビリティを劇的に向上させる仕組みです。
- cronジョブでリサーチを毎日自動実行
- sessions_spawnで複数記事を並列執筆
- マルチモデルレビューで品質を多角的にチェック
- Git連携でPR→マージ→デプロイを自動化
- 人間のレビューポイントを設計に組み込む
重要なのは、最初から完璧を目指さないことです。まずは1日1記事のパイプラインから始め、徐々にスケールアップしていきましょう。
OpenClawの活用法をさらに深く学びたい方は、OpenClaw完全攻略シリーズをご覧ください。





