
⚡ 3秒でわかる!この記事のポイント
- Codex CLIはデータ分析のコード生成・EDA・機械学習パイプライン構築を大幅に効率化できる
- Jupyter Notebookとの使い分けで、探索フェーズも本番コード化フェーズも加速
- 実践的なプロンプトテンプレート付きですぐに使い始められる
データ分析のコードを書くたびに「pandasの書き方なんだっけ」「matplotlibの設定が面倒」と感じていませんか。結論から言うと、Codex CLIを活用すれば、データ分析のルーティン作業を80%以上削減できます。
この記事はOpenAI Codex CLI完全攻略シリーズの第22回として、Pythonデータサイエンスの実践的な活用法をプロンプト例付きで解説します。
この記事でわかること
- Codex CLI × Pythonデータサイエンスの効率化ポイント
- EDA(探索的データ分析)の自動化手法
- 機械学習パイプラインの自動構築方法
- 実務で使えるプロンプトテンプレート集
Codex CLI × Pythonデータサイエンスの相性
データ分析ワークフローにおけるCLIの優位性
Codex CLIがデータサイエンスに適している理由は以下の通りです。
- ファイルベースの開発:
.pyファイルとして保存するため、バージョン管理が容易 - 自動実行と検証:コード生成後に即実行し、結果を確認して修正指示を出せる
- 再現可能なパイプライン:Notebookと違い、上から順に実行するだけで結果が再現
- 本番環境への移行が容易:スクリプトをそのままAirflowやLuigiに組み込める
Jupyter Notebookとの使い分け
| フェーズ | Jupyter Notebook | Codex CLI |
|---|---|---|
| 初期探索(EDA) | ◎ インタラクティブに試行 | ○ スクリプト一括生成 |
| 可視化の試行錯誤 | ◎ セル単位で確認 | ○ 指示で微調整 |
| 本番コード化 | △ セル順序の管理が大変 | ◎ 構造化されたスクリプト |
| パイプライン構築 | △ 不向き | ◎ 自動化に最適 |
| チームでの共有 | △ 差分管理が困難 | ◎ Git管理が容易 |
環境セットアップ:Codex CLIでデータサイエンス環境を構築
venv/conda環境の自動構築
Python 3.12のvenv環境を作成し、データサイエンス用の基本パッケージを
インストールしてください。
必要パッケージ:pandas, numpy, scikit-learn, matplotlib, seaborn,
plotly, jupyter, openpyxlCodex CLIは環境構築コマンドを生成・実行し、エラーがあれば自動で修正します。
requirements.txtの自動生成
現在のプロジェクトで使用しているPythonパッケージを分析し、
requirements.txtを生成してください。
バージョンはピン留めし、互換性の注意点もコメントで記載してください。EDA(探索的データ分析)の自動化
データ読み込み・前処理の自動コード生成
data/sales_2025.csv を読み込み、以下の前処理を行うスクリプトを作成してください:
1. データ型の自動推定と適切な変換
2. 日本語カラム名を英語のスネークケースに変換
3. 日付カラムのdatetime変換
4. 数値カラムのカンマ区切り文字列を数値に変換
結果をdata/sales_2025_cleaned.csvに保存統計サマリーと可視化の一括生成
data/sales_2025_cleaned.csv の包括的なEDAレポートを生成してください:
1. 基本統計量(describe + 追加指標)
2. カラムごとのヒストグラム / カテゴリ分布
3. 相関行列のヒートマップ
4. 時系列データの推移グラフ
5. 上記をHTML形式のレポートにまとめる
出力先:reports/eda_report.html欠損値・外れ値の検出と処理
data/sales_2025_cleaned.csv の欠損値と外れ値を分析してください:
1. 欠損値のパターン(MCAR/MAR/MNAR)を推定
2. 各カラムに最適な補完方法を提案・実装
3. IQR法とZスコア法で外れ値を検出
4. 外れ値の処理方針を提案(除外 or クリッピング or 変換)
処理前後の分布比較グラフも生成してください。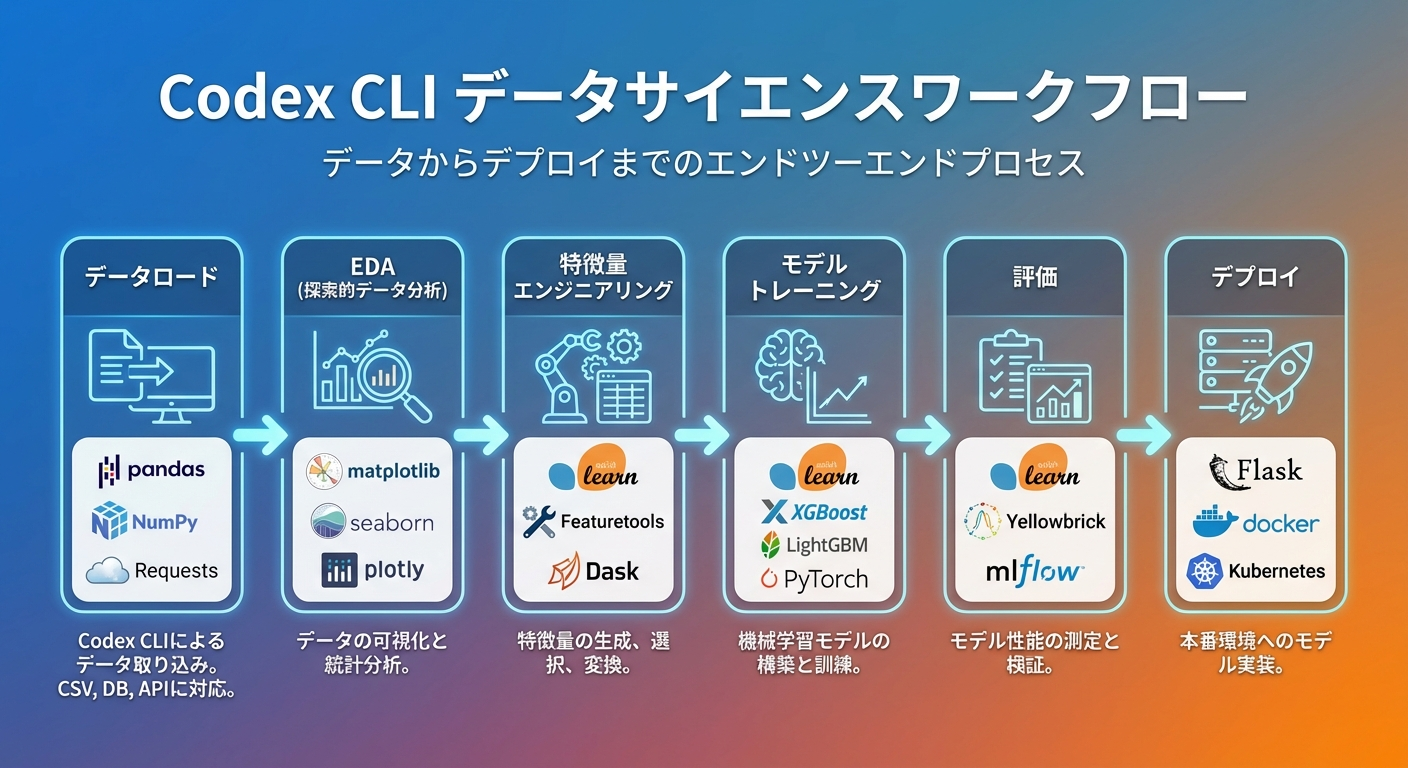
機械学習パイプラインの構築
特徴量エンジニアリングの自動化
data/sales_2025_cleaned.csv から売上予測モデルの特徴量を作成してください:
1. 時系列特徴量(曜日、月、四半期、祝日フラグ)
2. ラグ特徴量(7日、30日、90日のラグ)
3. ローリング特徴量(7日、30日の移動平均・標準偏差)
4. カテゴリ変数のエンコーディング(Target Encoding推奨)
各特徴量の重要度も事前分析してください。モデル選定・ハイパーパラメータチューニング
以下の条件で複数モデルを比較検証するスクリプトを作成してください:
- 対象モデル:LightGBM, XGBoost, RandomForest, Ridge
- 評価指標:RMSE, MAE, R²
- クロスバリデーション:時系列用のTimeSeriesSplit(5分割)
- Optuna を使ったベイズ最適化でハイパーパラメータチューニング
- 最良モデルをjoblib形式で保存評価指標の可視化と比較
モデル比較の結果を可視化してください:
1. モデルごとの評価指標をバーチャートで比較
2. 残差プロット(予測値 vs 実測値)
3. 特徴量重要度のトップ20
4. 学習曲線(過学習チェック)
5. 予測結果のインタラクティブなPlotlyグラフ基本的な使い方は「Codex CLI基本ガイド」を参照してください。
実践プロンプト集:データサイエンス編
CSV分析プロンプト
[ファイルパス]のCSVファイルを分析してください。
1. データの概要(行数、列数、データ型、欠損率)
2. 主要な発見(相関関係、トレンド、異常値)
3. ビジネスインサイトの提案
4. 追加分析の推奨事項
HTMLレポートで出力してください。レポート自動生成プロンプト
月次売上レポートを自動生成するスクリプトを作成してください。
入力:data/monthly/ ディレクトリのCSVファイル
出力:reports/monthly_report_YYYY_MM.pdf
内容:
- エグゼクティブサマリー
- KPI一覧(前月比、前年同月比)
- 商品カテゴリ別売上ランキング
- 地域別売上マップ
- 来月の予測(時系列モデル使用)ABテスト分析プロンプト
ABテストの結果を統計的に分析するスクリプトを作成してください。
入力:data/ab_test_results.csv(group, converted, revenue カラム)
分析内容:
1. コンバージョン率の比較(カイ二乗検定)
2. 収益の比較(Mann-Whitney U検定)
3. 効果サイズ(Cohen's d)の算出
4. 必要サンプルサイズの事後分析
5. 信頼区間の可視化応用テクニックについては「Codex CLI応用テクニック」や「Codex CLIプロンプトエンジニアリング」もあわせてご覧ください。
データサイエンティストとしてSES案件を探す方は「データサイエンティストSES案件ガイド」も参考にしてください。
まとめ:CLIファーストのデータサイエンスワークフロー
Codex CLIをデータサイエンスに活用することで、以下の効果が期待できます。
- EDAの時間を50%以上短縮:前処理・可視化・レポート生成を自動化
- 再現可能なパイプライン構築:スクリプトベースで管理し、本番環境への移行が容易
- 機械学習の実験効率化:モデル比較・チューニングを体系的に実行
- レポーティングの自動化:月次レポートやABテスト分析を定型化
データサイエンスのスキルは、SES案件でも需要が高く、単価アップに直結する専門性です。Codex CLIを使いこなして、効率的にスキルを磨きましょう。
SES BASEでデータサイエンス案件を探す
Python・機械学習・データ分析の経験を活かせるSES案件をSES BASEで検索してみてください。





