
「Codex CLIのデフォルトモデルで全タスクをこなしているけど、コストが気になる」「新しいGPT-5.4 miniが出たけど、どの場面で使えばいいの?」——Codex CLIユーザーから多く寄せられる疑問です。
結論から言えば、タスクの性質に応じてモデルを使い分けることで、品質を維持しつつコストを最大70%削減できます。 Codex CLIの最大の強みの一つは、複数のモデルを動的に切り替えられる柔軟性にあります。
この記事では、2026年3月時点で利用可能なモデルの比較から、タスク別の最適な選択基準、そして実践的なコスト最適化テクニックまでを解説します。
この記事を3秒でまとめると
- Codex CLIは複数モデル(GPT-5.4 mini / Codex mini / GPT-5.1等)を動的に切り替え可能
- タスクの複雑度に応じて適切なモデルを選ぶことで品質とコストのバランスが取れる
- miniモデル活用でコスト70%削減の実績あり
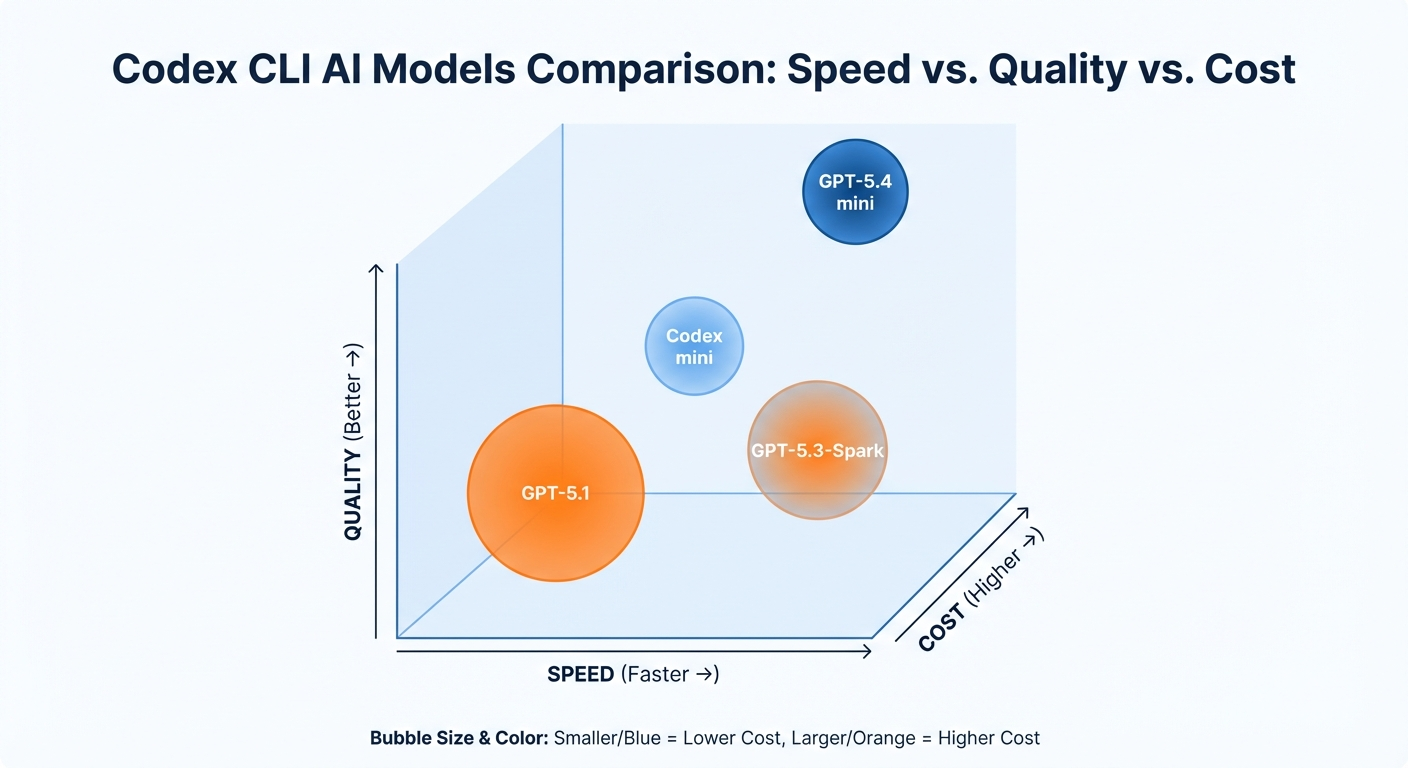
Codex CLIで利用可能なモデル一覧【2026年3月版】
GPT-5.4 mini / Codex mini / GPT-5.1 Codex mini の特徴比較
2026年3月時点でCodex CLIで利用可能な主要モデルを比較します。
| モデル | コンテキスト | 速度 | コスト | コード品質 | 推奨用途 |
|---|---|---|---|---|---|
| GPT-5.4 mini | 400Kトークン | ⚡ 最速 | $ | ★★★☆ | 日常的なコード生成・編集 |
| Codex mini | 400Kトークン | ⚡⚡ 速い | $ | ★★★★ | コード特化タスク全般 |
| GPT-5.1 | 400Kトークン | 🐢 やや遅い | $$$ | ★★★★★ | 複雑な設計・アーキテクチャ |
| GPT-5.1 Codex mini | 400Kトークン | ⚡ 速い | $$ | ★★★★☆ | バランス重視の開発タスク |
| GPT-5.3-Codex-Spark | 200Kトークン | ⚡⚡⚡ 超高速 | ¢ | ★★★☆ | プロトタイピング・実験 |
各モデルの特徴を詳しく見ていきましょう。
GPT-5.4 mini — 最新のminiモデル。コスト効率が最も高く、一般的なコード生成・編集タスクでは十分な品質を発揮します。日常的な開発のデフォルトモデルとして最適です。
Codex mini — コーディングに特化してファインチューニングされたモデル。コード補完・リファクタリング・テスト生成で高い精度を発揮します。
GPT-5.1 — 最高品質のフラッグシップモデル。複雑なアーキテクチャ設計や、微妙なバグの発見・修正に強みがあります。ただしコストは高め。
GPT-5.3-Codex-Spark(リサーチプレビュー)
GPT-5.3-Codex-Sparkは、OpenAIが2026年2月にリサーチプレビューとしてリリースした実験的モデルです。
- 超高速レスポンス: 他のモデルの2〜3倍の速度
- 低コスト: GPT-5.4 miniのさらに半額程度
- 制限事項: コンテキストウィンドウが200Kと小さめ、複雑な推論はやや弱い
プロトタイピングや簡単なスクリプト生成など、「まず動くものを素早く作りたい」場面で威力を発揮します。
モデルの動的切り替え方法
CLIでのモデル指定コマンド
Codex CLIでモデルを切り替える方法はシンプルです。
# 起動時にモデル指定
codex --model gpt-5.4-mini "この関数にユニットテストを追加して"
# インタラクティブモード中に切り替え
codex
> /model gpt-5.1
> この認証モジュールのアーキテクチャをレビューしてよく使うモデルにはエイリアスも設定できます。
# ~/.codex/config.toml でエイリアス定義
[models.aliases]
fast = "gpt-5.4-mini"
smart = "gpt-5.1"
balanced = "gpt-5.1-codex-mini"AGENTS.mdでのデフォルト設定
プロジェクトのAGENTS.mdファイルでデフォルトモデルとタスク別の推奨モデルを設定できます。
# モデル設定
## デフォルトモデル
gpt-5.4-mini を使用してください。
## タスク別モデル
- アーキテクチャ設計・レビュー: gpt-5.1
- 一般的なコード生成・編集: gpt-5.4-mini
- テスト生成: codex-mini
- ドキュメント生成: gpt-5.4-miniサブエージェントへのモデル割り当て
Codex CLIのサブエージェント機能を使う場合、親エージェントと子エージェントで異なるモデルを割り当てることができます。
# 親: GPT-5.1(全体設計)、子: GPT-5.4 mini(実装)
codex --model gpt-5.1 "認証システムを設計して、各モジュールの実装はサブエージェントに任せて"この構成により、設計は高品質モデル、実装はコスト効率の良いモデルという適材適所の使い分けが可能になります。
タスク別おすすめモデル選択マトリクス
コード生成 / レビュー / テスト / ドキュメント / デバッグ
タスクの種類別に推奨モデルを整理します。
| タスク | 推奨モデル | 理由 |
|---|---|---|
| 新規コード生成(CRUD等) | GPT-5.4 mini | パターン化されたタスクは低コストモデルで十分 |
| アルゴリズム実装 | GPT-5.1 | 複雑なロジックには高品質モデルが必要 |
| コードレビュー | GPT-5.1 | 設計上の問題を見つけるには深い推論力が必要 |
| ユニットテスト生成 | Codex mini | テストパターンに特化した高い精度 |
| E2Eテスト生成 | GPT-5.1 Codex mini | UI/UXの理解+コード生成のバランス |
| ドキュメント生成 | GPT-5.4 mini | 自然言語メインのタスクはminiで十分 |
| バグ修正(単純) | GPT-5.4 mini | エラーメッセージから原因特定は容易 |
| バグ修正(複雑) | GPT-5.1 | 複数ファイルにまたがる原因追跡に必要 |
| リファクタリング | GPT-5.1 Codex mini | 設計理解+コード変換の両方が必要 |
| プロトタイプ | Codex-Spark | 速度重視、品質は後で改善 |
速度 vs 品質 vs コストのトレードオフ
モデル選択は常にトレードオフです。以下の判断フレームワークを参考にしてください。
コストを最小化したい → GPT-5.4 mini
- 個人プロジェクト、学習用、プロトタイプ
品質を最大化したい → GPT-5.1
- 本番コード、セキュリティ関連、公開API設計
バランスを取りたい → GPT-5.1 Codex mini
- 日常的なチーム開発、中規模機能の実装
速度を最大化したい → Codex-Spark
- ペアプログラミング、インタラクティブな開発セッション
コスト最適化の実践テクニック
miniモデル活用でコスト70%削減の事例
実際のプロジェクトで、モデル使い分けによるコスト削減を実現した事例を紹介します。
Before: 全タスクGPT-5.1
- 月間トークン消費: 約50M トークン
- 月額コスト: 約$150
After: タスク別モデル使い分け
- 設計・レビュー(GPT-5.1): 10M トークン → $30
- コード生成・編集(GPT-5.4 mini): 30M トークン → $9
- テスト生成(Codex mini): 10M トークン → $5
- 月額コスト合計: 約$44(70%削減)
コスト削減のための具体的な設定例:
# ~/.codex/config.toml
[cost]
default_model = "gpt-5.4-mini"
budget_alert_daily = 10.0 # 日次$10超過でアラート
[cost.routing]
# タスクキーワードに応じて自動ルーティング
architecture = "gpt-5.1"
review = "gpt-5.1"
test = "codex-mini"
docs = "gpt-5.4-mini"
prototype = "gpt-5.3-codex-spark"コンテキストウィンドウ400Kトークンの活用法
OpenAI公式ブログでも解説されている通り、400Kトークンのコンテキストウィンドウはモノレポ全体の理解にも対応できるサイズです。
ただし、コンテキストが大きいほどコストも増加します。効率的に使うためのポイント:
- 必要なファイルだけをコンテキストに含める:
@fileディレクティブで明示的に指定 .codexignoreを設定: node_modules、ビルド成果物、ログファイルを除外- 段階的にコンテキストを拡大: まず関連ファイルだけ、必要なら全体を読ませる
カスタムモデル(BYOM)との組み合わせ
Codex CLIはBYOM(Bring Your Own Model)にも対応しています。OpenAI以外のモデルプロバイダーを利用することで、さらに柔軟なモデル戦略が組めます。
# ~/.codex/config.toml
[models.custom.local-codellama]
provider = "ollama"
model = "codellama:34b"
endpoint = "http://localhost:11434"
[models.custom.claude-sonnet]
provider = "anthropic"
model = "claude-sonnet-4-20250514"
api_key_env = "ANTHROPIC_API_KEY"BYOMの活用シーン:
- ローカルモデル: セキュリティ要件が厳しい案件で、コードを外部に送信できない場合
- 他社モデル: 特定のタスクで他社モデルの方が優れている場合のフォールバック
詳しい設定方法はCodex CLIカスタムモデルガイドで解説しています。
まとめ — 適材適所のモデル選択が生産性を決める
Codex CLIのモデル使い分けにおける重要なポイントを振り返ります。
- デフォルトはGPT-5.4 mini: 日常タスクの8割はminiモデルで十分
- 複雑なタスクにはGPT-5.1: 設計・レビュー・複雑なバグ修正は品質重視
- タスクルーティングの自動化: config.tomlやAGENTS.mdで設定しておく
- コスト監視を忘れずに: 日次・月次の予算アラートを設定する
- BYOMで選択肢を広げる: 必要に応じてローカルモデルや他社モデルも活用
「全タスク同じモデル」は、レストランで全メニューを同じ調理法で作るようなものです。タスクの性質に応じた適切なモデル選択が、開発効率とコスト効率の両方を最大化する鍵になります。
SES BASEでは、AIツールを活用した開発案件も多数掲載しています。
関連記事:





