
- Codex CLIのコンテキスト認識能力で、数十万行のコードベースでもアーキテクチャを数分で把握できる
- 依存関係の追跡・デッドコード検出・パフォーマンスボトルネック特定を自然言語で指示可能
- SES新規参画時のオンボーディングを従来の1週間→1日に短縮する実践パターンを紹介
SESエンジニアとして新しいプロジェクトに参画したとき、最初に直面するのが**「このコードベース、全体像がわからない」**という問題です。READMEは古く、ドキュメントは断片的、コードコメントは少ない——こんな状況は珍しくありません。
OpenAI Codex CLIを活用すれば、大規模なコードベースを自然言語で質問しながら高速に理解できます。アーキテクチャの把握、依存関係の追跡、バグの原因調査まで、従来なら数日かかっていた作業を数時間に短縮可能です。
本記事では、Codex CLIを使ったコードベース理解の実践テクニックを、具体的なコマンド例とともに解説します。
- Codex CLIでコードベースの全体像を把握する方法
- 依存関係・データフローの追跡テクニック
- レガシーコードの解読とドキュメント自動生成
- SES新規参画時のオンボーディング高速化パターン
なぜコードベース理解にAIが有効なのか
従来の方法の限界
大規模コードベースの理解には、従来以下のアプローチが使われてきました。
| 方法 | 所要時間 | 問題点 |
|---|---|---|
| ドキュメント読み込み | 1〜3日 | 古い・不完全なことが多い |
| コードリーディング | 3〜7日 | ファイル数が多すぎて全体像が見えない |
| 先輩に質問 | 随時 | 相手の時間を奪う、属人的 |
| grep / 検索 | 随時 | 文脈を理解しないため関連箇所の見落としが多い |
Codex CLIはコードの文脈を理解した上で質問に答えるため、これらの限界を克服できます。ファイル間の依存関係、暗黙的な規約、設計パターンなど、grepでは見つけられない情報を引き出せるのが最大の強みです。
Codex CLIのコードベース認識の仕組み
Codex CLIは以下のような手順でコードベースを理解します。
- ディレクトリ構造のスキャン: プロジェクトの全体構造を把握
- 主要ファイルの読み込み: package.json、設定ファイル、エントリポイントなどを自動的に確認
- コンテキスト構築: 読み込んだ情報から全体像のメンタルモデルを構築
- 質問への応答: 構築したモデルをもとに、具体的な質問に回答
# Codex CLIを起動してコードベースを解析
codex
# アーキテクチャの概要を質問
> このプロジェクトのアーキテクチャを説明して。主要なモジュールとその依存関係を図示して。全体像の把握テクニック
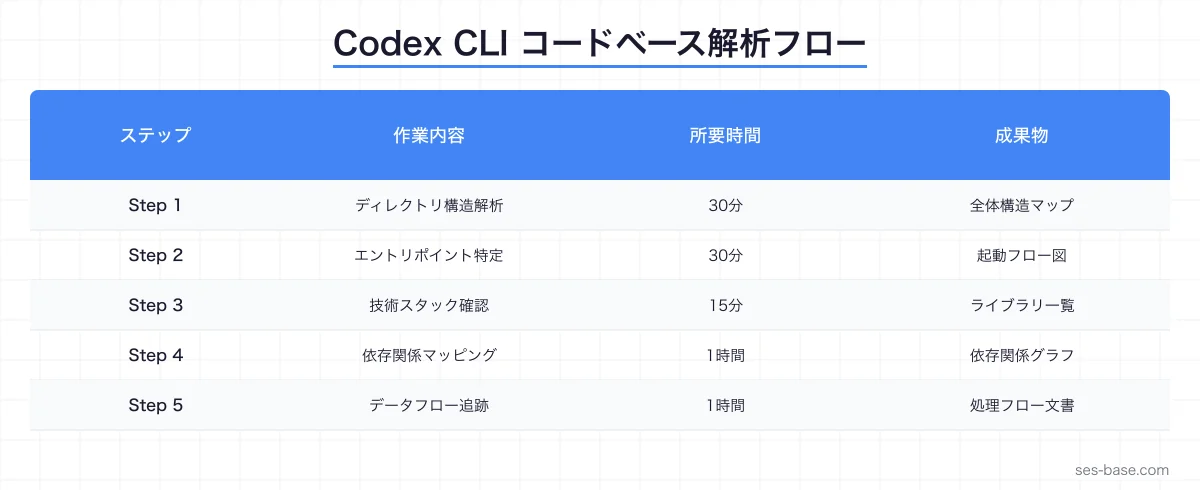
ステップ1: ディレクトリ構造の解析
最初のステップはプロジェクトの骨格を理解することです。
codex
> このプロジェクトのディレクトリ構造を分析して、各ディレクトリの役割を説明して。
> 特にビジネスロジックがどこに集約されているか教えて。Codex CLIは単にディレクトリ名を列挙するだけでなく、ファイルの中身を確認した上で各ディレクトリの実際の役割を説明してくれます。
ステップ2: エントリポイントの特定
> アプリケーションのエントリポイントはどこ?
> 起動時の初期化フローを順番に説明して。Webアプリケーションの場合、以下のような情報を引き出せます。
- HTTPサーバーの起動ファイル:
src/index.ts、src/main.tsなど - ルーティング設定: ルートの定義場所と構造
- ミドルウェアの適用順序: 認証、ログ、エラーハンドリングの順序
- データベース接続の初期化: コネクションプールの設定
ステップ3: 技術スタックの確認
> このプロジェクトで使われている主要なライブラリとそのバージョンを一覧にして。
> それぞれの用途も説明して。package.jsonやgo.mod、requirements.txtなどの依存ファイルを自動的に読み込み、各ライブラリが何のために使われているかを文脈付きで解説してくれます。
依存関係の追跡
モジュール間の依存関係マップ
> src/services/ 配下のモジュール間の依存関係をMermaid形式のグラフで出力して。
> 循環依存があれば指摘して。大規模プロジェクトでは、モジュール間の依存関係が複雑に絡み合っていることが多いです。Codex CLIはimport文を追跡し、依存関係のグラフを生成できます。
graph TD
A[UserService] --> B[AuthService]
A --> C[EmailService]
B --> D[TokenRepository]
C --> E[TemplateEngine]
A --> F[UserRepository]
F --> G[Database]
D --> Gデータフローの追跡
特定の処理がどのようにデータを変換しているかを追跡します。
> ユーザー登録のリクエストが受信されてからDBに保存されるまでの
> データフローを詳細に追跡して。各ステップでデータがどう変換されるか示して。この質問に対して、Codex CLIは以下のような詳細な回答を生成します。
- HTTPリクエスト受信 →
POST /api/users→routes/users.ts - バリデーション →
zodスキーマでリクエストボディを検証 - パスワードハッシュ化 →
bcrypt.hash()でソルト付きハッシュ - DB保存 →
UserRepository.create()→INSERT INTO users - メール送信 →
EmailService.sendWelcome()→ 非同期キュー
影響範囲の分析
コードを変更する前に、その変更がどこに影響するかを調べます。
> UserServiceのcreateUser関数を変更した場合、影響を受けるファイルを全てリストアップして。
> テストファイルも含めて。これは特にSES現場で重要なスキルです。既存コードへの変更は、思わぬ箇所に影響を及ぼすことがあります。事前に影響範囲を把握することで、テスト漏れやデグレードを防止できます。
レガシーコードの解読
暗号的なコードの解読
レガシーコードにありがちな「何をしているか分からない」コードを解読します。
> src/legacy/data_processor.py のprocess_batch関数を解析して。
> 何をしているか、なぜこのような実装になっているか推測を含めて説明して。Codex CLIは変数名や処理パターンから意図を推測し、分かりやすい説明を提供します。
ドキュメント自動生成
理解したコードのドキュメントを自動生成させます。
> src/services/payment.ts の全ての公開メソッドに対して、
> 以下の情報を含むドキュメントを生成して:
> - 関数の目的
> - 引数の説明
> - 戻り値の説明
> - 使用例
> - 注意事項(あれば)生成されたドキュメントをレビューして、正確性を確認した上で採用します。これにより、ドキュメントがないレガシーコードに段階的にドキュメントを追加できます。
設計パターンの特定
> このプロジェクトで使われている設計パターンを特定して。
> 各パターンの使用箇所と、そのパターンが選ばれた理由を推測して。Repository パターン、Strategy パターン、Observer パターンなど、プロジェクトで使われている設計パターンを体系的に特定できます。これにより、コードベースの設計思想を素早く理解できます。
バグ調査テクニック
エラーメッセージからの原因追跡
> 以下のエラーが発生している。原因を調査して:
> "TypeError: Cannot read properties of undefined (reading 'userId')"
> スタックトレース:
> at processOrder (src/services/order.ts:45)
> at handleCheckout (src/routes/checkout.ts:23)Codex CLIはスタックトレースを読み解き、関連するコードを参照した上で原因を特定します。単なるスタックトレースの読み上げではなく、データの流れを追跡して根本原因を推定してくれます。
パフォーマンスボトルネックの特定
> このAPIサーバーでレスポンスが遅いエンドポイントがあるとしたら、
> どこがボトルネックになりうるか分析して。
> N+1クエリ、不要な同期処理、メモリ効率の悪い箇所を重点的にチェックして。セキュリティ脆弱性のスキャン
> このプロジェクトのセキュリティ上の懸念点を指摘して。
> 特にSQLインジェクション、XSS、認証バイパスの可能性をチェックして。SES新規参画のオンボーディング実践
Day 1: 全体像の把握(2〜3時間)
新規プロジェクトに参画した初日に、Codex CLIで以下を実行します。
# 1. プロジェクト概要の把握(30分)
codex
> このプロジェクトの全体像を教えて。何をするアプリケーションで、
> どんな技術スタックで、主要な機能は何?
# 2. ディレクトリ構造の理解(30分)
> ディレクトリ構造とそれぞれの役割を説明して。
> 開発で主に触るファイルはどれ?
# 3. 開発環境のセットアップ(1時間)
> 開発環境をローカルにセットアップする手順を教えて。
> 必要な環境変数やDB設定も含めて。
# 4. 主要な機能フローの理解(1時間)
> ユーザーがログインしてから主要機能を使うまでの
> フローを順番に追跡して説明して。Day 2: 詳細理解とキャッチアップ(3〜4時間)
# 5. 担当モジュールの詳細理解(2時間)
> src/services/billing/ の全体構造を説明して。
> 主要なクラスとメソッド、それらの関係性を示して。
# 6. テストの構造理解(1時間)
> テストの構造と実行方法を教えて。
> テストカバレッジが低い箇所はどこ?
# 7. CI/CDの理解(30分)
> CI/CDパイプラインの設定を確認して説明して。
> デプロイフローはどうなっている?Day 3以降: 実装開始
Day 1〜2で全体像を把握できていれば、Day 3から実装作業に入れます。従来は1〜2週間かかっていたオンボーディングが、大幅に短縮されます。
大規模コードベースでの注意点
コンテキストウィンドウの制限
大規模プロジェクトでは、全てのファイルを一度に読み込むことはできません。以下の戦略で対応します。
段階的な深掘り戦略
# ❌ 非効率: 全体を一度に読もうとする
> プロジェクトの全ファイルを読んで解説して
# ✅ 効率的: トップダウンで段階的に深掘り
> まずディレクトリ構造から全体像を把握して
> [回答を受けて]
> src/services/ の中をもう少し詳しく見て
> [回答を受けて]
> src/services/payment.ts の詳細を教えて複数セッションにまたがる調査
大規模な調査は1セッションで完結しないことがあります。ワークスペース管理で紹介されているテクニックを活用し、調査結果を中間ファイルに保存しながら進めます。
> ここまでの調査結果を docs/architecture-analysis.md に整理して書き出して。
> 次のセッションで続きから調査できるようにまとめて。他ツールとの比較
Codex CLI vs 従来のコード解析ツール
| 機能 | Codex CLI | ctags/LSP | grep/ripgrep |
|---|---|---|---|
| 自然言語での質問 | ✅ | ❌ | ❌ |
| 文脈を踏まえた回答 | ✅ | 部分的 | ❌ |
| 設計意図の推測 | ✅ | ❌ | ❌ |
| コード変更の提案 | ✅ | ❌ | ❌ |
| 正確なシンボル解決 | 部分的 | ✅ | ❌ |
| 高速な全文検索 | △ | △ | ✅ |
最適なアプローチはツールを組み合わせることです。まずCodex CLIで全体像を把握し、具体的なシンボル検索にはLSPやgrepを使う——この組み合わせが最も効率的です。
まとめ: AIで変わるコードベース理解
OpenAI Codex CLIを活用することで、大規模コードベースの理解は劇的に効率化されます。
- 全体像の把握: 数十万行でもディレクトリ構造とエントリポイントから素早く理解
- 依存関係の追跡: 自然言語で質問するだけでモジュール間の関係を可視化
- レガシーコードの解読: 暗号的なコードも文脈を踏まえて解説
- バグ調査の高速化: スタックトレースから根本原因を推定
- オンボーディングの短縮: 1〜2週間 → 2〜3日で実装開始可能
SESエンジニアにとって、新しいプロジェクトへの素早い適応は市場価値を大きく左右します。Codex CLIをコードベース理解のツールとして使いこなすことで、参画初日から価値を発揮できるエンジニアを目指しましょう。
関連記事
- マルチファイルワークスペース — 複数ファイルを横断した操作方法
- デバッグガイド — デバッグの実践テクニック
- monorepo管理 — monorepoプロジェクトでの活用
- ワークスペース管理 — プロジェクト管理の効率化
- レガシーリファクタリング — レガシーコードの改善方法





