
- Cloud SpannerはRDBの整合性とNoSQLのスケーラビリティを両立した唯一のグローバル分散DB
- ホットスポットを回避するスキーマ設計とインターリーブテーブルの活用が性能の鍵
- Processing Unitベースの柔軟なスケーリングとコスト最適化でTCOを50%削減できるケースもある
「RDBの強い整合性が必要だが、グローバルにスケールしたい」「NoSQLの水平スケーリングが欲しいが、トランザクションも必要」——従来のデータベースでは解決が困難だったこの課題を、Cloud Spannerはリレーショナル・分散・スケーラブルの3つを同時に実現することで解決します。
この記事はGoogle Cloud完全攻略シリーズの第17回として、Cloud Spannerの設計・運用・コスト最適化をSESエンジニア向けに実践的に解説します。
- Cloud Spannerのアーキテクチャと他DBとの違い
- ホットスポットを回避するスキーマ設計のベストプラクティス
- インターリーブテーブルによるパフォーマンス最適化
- グローバル分散構成の設計パターン
- Processing Unitベースのコスト最適化テクニック
- SES案件での活用シナリオと求められるスキル
Cloud Spannerとは — 他DBとの違い
Cloud Spannerの位置づけ
Cloud Spannerは、Googleが開発したグローバル分散リレーショナルデータベースです。従来のRDB(MySQL/PostgreSQL)とNoSQL(DynamoDB/Bigtable)の両方の利点を持つ、ユニークな存在です。
| 特性 | MySQL/PostgreSQL | DynamoDB/Bigtable | Cloud Spanner |
|---|---|---|---|
| スキーマ | 厳密なスキーマ | スキーマレス | 厳密なスキーマ |
| トランザクション | ACID | 制限付き | グローバルACID |
| スケーリング | 垂直(スケールアップ) | 水平(自動) | 水平(自動) |
| 整合性 | 強い整合性(単一ノード) | 結果整合性 | 強い外部整合性(グローバル) |
| SQL | フルSQL | 限定的 | フルSQL(ANSI準拠) |
| 可用性SLA | 99.95% | 99.99% | 99.999%(マルチリージョン) |
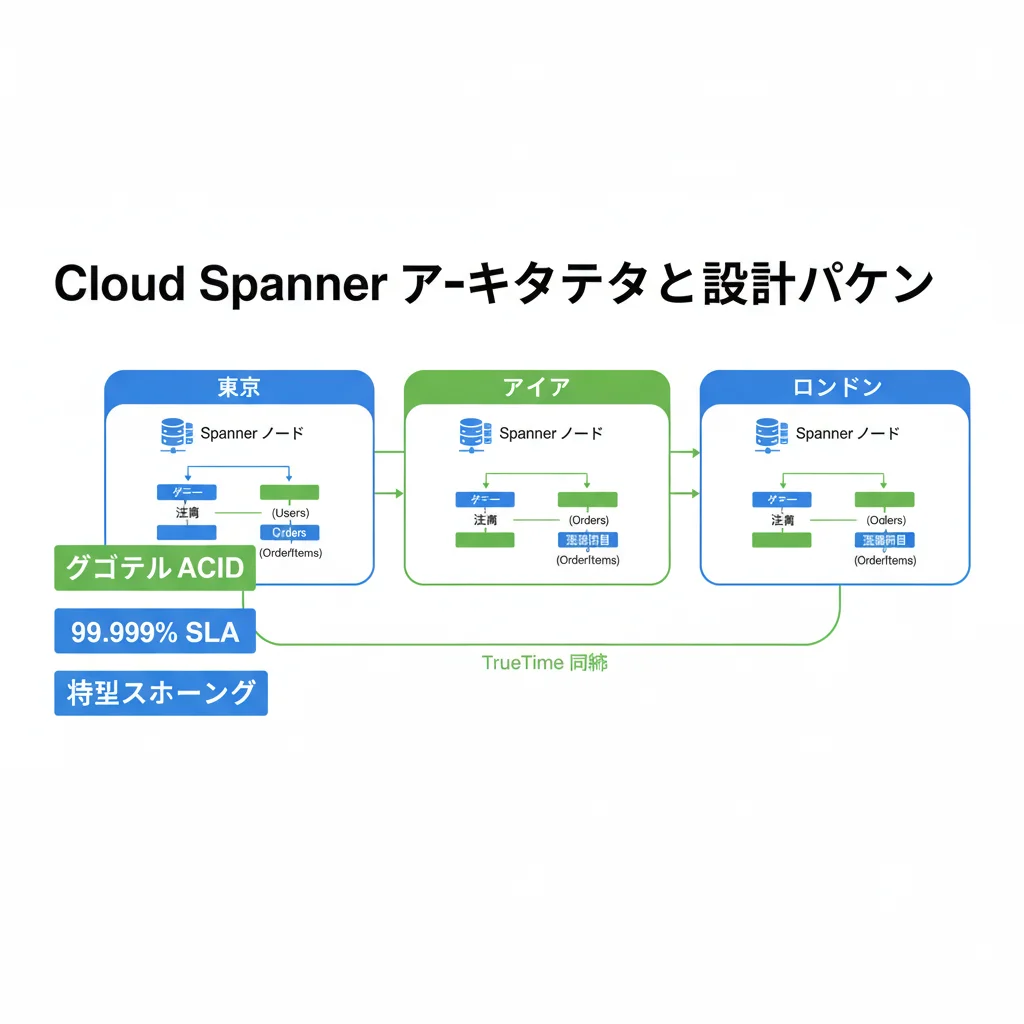
TrueTimeによるグローバル整合性
Cloud Spannerの核心技術はTrueTime APIです。Googleのデータセンターに設置された原子時計とGPSレシーバーにより、ナノ秒精度のグローバル時刻同期を実現しています。これにより、世界中のどのノードに書き込んでも、完全な整合性(外部整合性)が保証されます。
TrueTimeの仕組み:
┌──────────┐ ┌──────────┐ ┌──────────┐
│ 東京 │ │ アイオワ │ │ ロンドン │
│ ノードA │ │ ノードB │ │ ノードC │
└─────┬────┘ └─────┬────┘ └─────┬────┘
│ │ │
└───────┬───────┘───────┬───────┘
│ │
┌─────┴─────┐ ┌─────┴─────┐
│ 原子時計 │ │ GPS │
│ サーバー群 │ │ レシーバー │
└───────────┘ └───────────┘
↓
グローバル外部整合性を保証スキーマ設計のベストプラクティス
主キー設計 — ホットスポットの回避
Cloud Spannerで最も重要なのが主キー設計です。連番(AUTO_INCREMENT相当)を主キーにすると、新しいデータが常に同じノードに集中する「ホットスポット」が発生します。
❌ アンチパターン: 連番主キー
-- NG: 連番は常に末尾のスプリットに書き込みが集中
CREATE TABLE Users (
UserId INT64 NOT NULL,
Name STRING(100),
Email STRING(255),
) PRIMARY KEY (UserId);✅ 推奨: UUIDまたはビット反転ID
-- OK: UUIDで書き込みを分散
CREATE TABLE Users (
UserId STRING(36) NOT NULL DEFAULT (GENERATE_UUID()),
Name STRING(100),
Email STRING(255),
CreatedAt TIMESTAMP NOT NULL OPTIONS (allow_commit_timestamp=true),
) PRIMARY KEY (UserId);✅ 推奨: 複合キーによるシャーディング
-- OK: ShardIdで書き込みを16分割
CREATE TABLE Orders (
ShardId INT64 NOT NULL,
OrderId STRING(36) NOT NULL,
CustomerId STRING(36) NOT NULL,
TotalAmount NUMERIC,
Status STRING(20),
CreatedAt TIMESTAMP NOT NULL OPTIONS (allow_commit_timestamp=true),
) PRIMARY KEY (ShardId, OrderId);インターリーブテーブル — 親子データの局所性最適化
Cloud Spanner固有の機能である**インターリーブ(INTERLEAVE IN PARENT)**は、親子関係のデータを物理的に同じスプリットに配置し、JOIN性能を劇的に向上させます。
-- 親テーブル: Users
CREATE TABLE Users (
UserId STRING(36) NOT NULL,
Name STRING(100),
Email STRING(255),
) PRIMARY KEY (UserId);
-- 子テーブル: Orders(Usersにインターリーブ)
CREATE TABLE Orders (
UserId STRING(36) NOT NULL,
OrderId STRING(36) NOT NULL,
TotalAmount NUMERIC,
CreatedAt TIMESTAMP NOT NULL OPTIONS (allow_commit_timestamp=true),
) PRIMARY KEY (UserId, OrderId),
INTERLEAVE IN PARENT Users ON DELETE CASCADE;
-- 孫テーブル: OrderItems(Ordersにインターリーブ)
CREATE TABLE OrderItems (
UserId STRING(36) NOT NULL,
OrderId STRING(36) NOT NULL,
ItemId STRING(36) NOT NULL,
ProductName STRING(200),
Quantity INT64,
UnitPrice NUMERIC,
) PRIMARY KEY (UserId, OrderId, ItemId),
INTERLEAVE IN PARENT Orders ON DELETE CASCADE;この設計により、あるユーザーの注文一覧と注文詳細を取得するクエリが、単一ノード内のディスクアクセスで完結します。
セカンダリインデックスの設計
-- NULL_FILTERED: NULLを含む行をインデックスから除外(スペース節約)
CREATE NULL_FILTERED INDEX OrdersByStatus
ON Orders (Status, CreatedAt DESC);
-- STORING: カバリングインデックスでテーブルアクセスを回避
CREATE INDEX OrdersByCustomer
ON Orders (CustomerId)
STORING (TotalAmount, Status, CreatedAt);クエリの最適化
実行プランの分析
-- クエリの実行プランを確認
EXPLAIN ANALYZE
SELECT u.Name, o.OrderId, o.TotalAmount
FROM Users u
JOIN Orders o ON u.UserId = o.UserId
WHERE u.UserId = @user_id
ORDER BY o.CreatedAt DESC
LIMIT 10;パフォーマンスチューニングのポイント
1. ステイルリード(Stale Read)の活用
強い整合性が不要な読み取りには、ステイルリードを使用してパフォーマンスを向上させます。
# Python (google-cloud-spanner)でのステイルリード
import datetime
from google.cloud import spanner
instance = spanner_client.instance("my-instance")
database = instance.database("my-database")
# 15秒前のスナップショットで読み取り(レプリカから読む可能性あり)
with database.snapshot(
exact_staleness=datetime.timedelta(seconds=15)
) as snapshot:
results = snapshot.execute_sql(
"SELECT Name, Email FROM Users WHERE UserId = @id",
params={"id": user_id},
param_types={"id": spanner.param_types.STRING},
)
for row in results:
print(f"Name: {row[0]}, Email: {row[1]}")2. バッチ処理の最適化
# ミューテーションのバッチ書き込み
with database.batch() as batch:
batch.insert(
table="Users",
columns=["UserId", "Name", "Email", "CreatedAt"],
values=[
[str(uuid4()), "田中太郎", "[email protected]", spanner.COMMIT_TIMESTAMP],
[str(uuid4()), "佐藤花子", "[email protected]", spanner.COMMIT_TIMESTAMP],
# ... 最大20,000ミューテーションまでバッチ可能
],
)3. パーティション化DMLによる大量更新
-- パーティション化DMLで大量更新を効率的に実行
-- (サーバー側で自動的にパーティション分割される)
UPDATE Orders
SET Status = 'archived'
WHERE CreatedAt < TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 365 DAY)
AND Status = 'completed';グローバル分散構成の設計
リージョン構成の選択
Cloud Spannerは3つの構成タイプを提供します。
| 構成タイプ | 可用性SLA | レイテンシ | 用途 |
|---|---|---|---|
| リージョナル | 99.99% | 最小 | 単一リージョンのワークロード |
| マルチリージョン | 99.999% | やや高い | 高可用性が必要な本番環境 |
| カスタム | 99.999% | 設定による | 特定地域の要件に対応 |
マルチリージョン構成の例
# マルチリージョンインスタンスの作成
gcloud spanner instances create global-app-db \
--config=nam-eur-asia1 \
--description="グローバルアプリケーションDB" \
--processing-units=1000
# データベースの作成
gcloud spanner databases create app \
--instance=global-app-db \
--ddl='CREATE TABLE Users (
UserId STRING(36) NOT NULL DEFAULT (GENERATE_UUID()),
Name STRING(100),
Region STRING(20),
CreatedAt TIMESTAMP NOT NULL OPTIONS (allow_commit_timestamp=true)
) PRIMARY KEY (UserId)'リーダー配置の最適化
書き込み性能を最適化するために、リーダーリージョンを適切に設定します。
# リーダーリージョンの確認
gcloud spanner instances describe global-app-db --format="value(config)"
# カスタム構成でリーダーリージョンを東京に設定
gcloud spanner instance-configs create custom-asia-config \
--base-config=nam-eur-asia1 \
--replicas=location=asia-northeast1,type=READ_WRITE \
--replicas=location=us-central1,type=READ_WRITE \
--replicas=location=europe-west1,type=READ_ONLY \
--leader-region=asia-northeast1コスト最適化
Processing Unitによる柔軟なスケーリング
Cloud Spannerは2024年以降、ノード単位ではなくProcessing Unit(PU)単位で課金されます。最小100 PU(≒0.1ノード)から利用可能で、小規模なワークロードでもコスト効率よく利用できます。
# Processing Unitの設定(100 PU = 最小構成)
gcloud spanner instances create small-app-db \
--config=regional-asia-northeast1 \
--description="小規模アプリDB" \
--processing-units=100
# スケールアップ(負荷に応じて)
gcloud spanner instances update small-app-db \
--processing-units=300オートスケーリングの設定
# オートスケーラーの設定
gcloud spanner instances update my-instance \
--autoscaling-min-processing-units=100 \
--autoscaling-max-processing-units=2000 \
--autoscaling-high-priority-cpu-target=65 \
--autoscaling-storage-target=80コスト見積もりの目安
| 構成 | Processing Units | 月額概算(東京リージョン) |
|---|---|---|
| 最小構成 | 100 PU | 約$65/月 |
| 小規模本番 | 300 PU | 約$195/月 |
| 中規模 | 1000 PU (1ノード) | 約$650/月 |
| 大規模 | 3000 PU (3ノード) | 約$1,950/月 |
| マルチリージョン | 3000 PU | 約$5,850/月 |
※ストレージ料金($0.30/GB/月)は別途
コスト管理の詳細はGoogle Cloud Monitoring&Loggingガイドも参照してください。
アプリケーション統合パターン
Go言語でのCRUD実装
package main
import (
"context"
"fmt"
"log"
"cloud.google.com/go/spanner"
"google.golang.org/api/iterator"
)
func createUser(ctx context.Context, client *spanner.Client, name, email string) error {
_, err := client.Apply(ctx, []*spanner.Mutation{
spanner.InsertOrUpdate("Users",
[]string{"UserId", "Name", "Email", "CreatedAt"},
[]interface{}{spanner.GenericColumnValue{Type: spanner.NullString{}, Value: nil}, name, email, spanner.CommitTimestamp},
),
})
return err
}
func getUserOrders(ctx context.Context, client *spanner.Client, userID string) error {
stmt := spanner.Statement{
SQL: `SELECT u.Name, o.OrderId, o.TotalAmount, o.CreatedAt
FROM Users u
JOIN Orders o ON u.UserId = o.UserId
WHERE u.UserId = @userId
ORDER BY o.CreatedAt DESC
LIMIT 20`,
Params: map[string]interface{}{"userId": userID},
}
iter := client.Single().Query(ctx, stmt)
defer iter.Stop()
for {
row, err := iter.Next()
if err == iterator.Done {
break
}
if err != nil {
return err
}
var name, orderID string
var amount spanner.NullFloat64
var createdAt spanner.NullTime
if err := row.Columns(&name, &orderID, &amount, &createdAt); err != nil {
return err
}
fmt.Printf("Order: %s, Amount: %.2f\n", orderID, amount.Float64)
}
return nil
}Spring Boot (Java)での統合
// Spring Data Cloud Spannerでの使用例
@Entity(tableName = "Users")
public class User {
@PrimaryKey
@Column(name = "UserId")
private String userId;
@Column(name = "Name")
private String name;
@Column(name = "Email")
private String email;
@Column(name = "CreatedAt")
@CommitTimestamp
private Timestamp createdAt;
@Interleaved
private List<Order> orders;
}
@Repository
public interface UserRepository extends SpannerRepository<User, String> {
List<User> findByEmailContaining(String email);
@Query("SELECT * FROM Users WHERE CreatedAt > @since")
List<User> findRecentUsers(@Param("since") Timestamp since);
}Cloud SQL/AlloyDBからの移行
移行判断フローチャート
Cloud Spannerを選ぶべきケース:
- 99.999%の可用性が必要
- グローバルな書き込み分散が必要
- 水平スケーリングが必要(数TB以上のデータ)
- ACID トランザクションが必須
Cloud SQL/AlloyDBを選ぶべきケース:
- 単一リージョンで十分
- コストを最小限に抑えたい
- PostgreSQL/MySQL互換が重要
- 小規模(〜数百GB)
Cloud SQLの詳細はCloud SQL最適化ガイドを参照してください。
データ移行ツール
# Harbourbridge(OSS)を使った移行
harbourbridge -driver=postgres \
-source="host=localhost dbname=mydb user=admin password=secret" \
-target-profile="instance=my-spanner,dbname=mydb"
# Dataflow を使った大規模移行
gcloud dataflow jobs run postgres-to-spanner \
--gcs-location=gs://dataflow-templates/latest/Postgres_to_Cloud_Spanner \
--parameters \
instanceId=my-instance,\
databaseId=my-database,\
jdbcUrl=jdbc:postgresql://source-db:5432/mydb,\
table=UsersSES案件でのCloud Spanner活用
Cloud Spannerのスキルが求められるSES案件は、主に大規模なグローバルサービスや金融系システムです。2026年現在、Cloud Spanner経験のあるエンジニアの月額単価は80〜120万円が相場です。
求められるスキルセット:
- スキーマ設計(ホットスポット回避、インターリーブ)
- クエリ最適化(実行プラン分析、ステイルリード)
- グローバル分散構成の設計
- 移行計画の策定と実行
- コスト見積もりと最適化
まとめ
Cloud Spannerは、リレーショナルDBの整合性とNoSQLのスケーラビリティを兼ね備えた唯一無二のデータベースサービスです。
Cloud Spanner活用で押さえるべきポイント:
- 主キー設計でホットスポットを回避(UUID or 複合キー)
- インターリーブテーブルで親子データの局所性を最適化
- ステイルリードで読み取り性能を向上(整合性要件に応じて)
- Processing Unitベースの柔軟なスケーリングでコストを最適化
- グローバル分散構成はリーダーリージョンの配置が鍵
SESエンジニアとしてCloud Spannerのスキルを身につけることで、高単価な大規模案件への参画機会が大きく広がるでしょう。





