
- Cloud MonitoringとCloud LoggingはGoogle Cloudの統合オブザーバビリティ基盤で、すべてのGCPサービスと連携
- メトリクス・ログ・アラートを一元管理し、障害の早期検知から根本原因分析まで実現
- カスタムダッシュボード・SLO監視・ログルーターなど、SES案件で即活用できる実践テクニックを網羅
- Google Cloud 完全攻略 Ep.1: GCPの基礎知識とプロジェクト作成
- Google Cloud 完全攻略 Ep.2: Cloud RunとCloud SQLで実現するスケーラブルなコンテナ運用
- Google Cloud 完全攻略 Ep.3: BigQueryではじめるデータ分析入門
- Google Cloud 完全攻略 Ep.4: Cloud Functionsで学ぶサーバーレスアーキテクチャ入門
- Google Cloud 完全攻略 Ep.5: Cloud Storageで学ぶオブジェクトストレージ運用入門
- Google Cloud 完全攻略 Ep.6: IAMとセキュリティ設計で学ぶクラウド権限管理
- Google Cloud 完全攻略 Ep.7: VPCネットワーク設計入門
- Google Cloud 完全攻略 Ep.8: GKEで学ぶKubernetesクラスタ運用入門
- Google Cloud 完全攻略 Ep.9: Cloud MonitoringとLoggingで学ぶオブザーバビリティ入門(本記事)
「システムが落ちました」——SES案件で最も避けたいこの一言。しかし、適切な監視基盤があれば、障害は発生前に予兆を検知し、影響を最小限に抑えることができます。
Google CloudのCloud MonitoringとCloud Loggingは、GCPネイティブの統合オブザーバビリティプラットフォームです。メトリクス収集、ログ管理、アラート通知、ダッシュボード可視化を一つのプラットフォームで完結でき、追加のインフラ構築は不要です。
本記事では、オブザーバビリティの基本概念から、Cloud Monitoring/Loggingの実践的な設定方法、SLO監視、ログルーター、カスタムメトリクスまで、SES現場で即使える知識を体系的に解説します。
オブザーバビリティの三本柱——メトリクス・ログ・トレース
なぜオブザーバビリティが重要なのか
オブザーバビリティ(Observability)とは、システムの外部出力からシステム内部の状態を理解する能力のことです。従来の「監視」がアラートを鳴らすだけだったのに対し、オブザーバビリティはなぜ問題が起きたかを特定するところまでカバーします。
SES案件では、特に以下の場面でオブザーバビリティの知識が求められます。
- インフラ構築案件: 監視設計・アラート設定が必ず含まれる
- 運用保守案件: 障害対応の根本原因分析に不可欠
- SRE案件: SLI/SLO設計はコアスキル
三本柱の関係
| 柱 | Google Cloudサービス | 役割 |
|---|---|---|
| メトリクス | Cloud Monitoring | 数値データの時系列(CPU使用率、リクエスト数など) |
| ログ | Cloud Logging | イベントの記録(エラーメッセージ、アクセスログなど) |
| トレース | Cloud Trace | リクエストの分散追跡(マイクロサービス間の遅延分析) |
これら三つを組み合わせることで、**「何が起きたか(メトリクス)」→「いつどこで起きたか(ログ)」→「なぜ起きたか(トレース)」**の順に深掘りできます。
Cloud Monitoring——メトリクス収集とアラート設計
基本アーキテクチャ
Cloud Monitoringは、GCPリソースのメトリクスを自動収集するフルマネージドサービスです。Compute Engine、Cloud Run、GKE、Cloud SQLなど、主要サービスはエージェントなしで即座にメトリクスが取得されます。
# プロジェクトのメトリクスを一覧表示
gcloud monitoring metrics-descriptors list \
--filter="metric.type = starts_with('compute.googleapis.com')" \
--limit=10
# 特定メトリクスの詳細確認
gcloud monitoring metrics-descriptors describe \
compute.googleapis.com/instance/cpu/utilizationカスタムメトリクスの送信
アプリケーション固有のメトリクスを送信するには、OpenTelemetryまたはCloud MonitoringのAPIを使用します。
# Python: OpenTelemetryでカスタムメトリクス送信
from opentelemetry import metrics
from opentelemetry.exporter.cloud_monitoring import CloudMonitoringMetricsExporter
from opentelemetry.sdk.metrics import MeterProvider
from opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader
# エクスポーターの設定
exporter = CloudMonitoringMetricsExporter(project_id="my-project")
reader = PeriodicExportingMetricReader(exporter, export_interval_millis=60000)
provider = MeterProvider(metric_readers=[reader])
metrics.set_meter_provider(provider)
# メーターの作成
meter = metrics.get_meter("ses-app")
# カウンター: APIリクエスト数
request_counter = meter.create_counter(
name="api_requests_total",
description="Total API requests",
unit="1",
)
# ヒストグラム: レスポンスタイム
response_time = meter.create_histogram(
name="api_response_time",
description="API response time in milliseconds",
unit="ms",
)
# メトリクスの記録
def handle_request(endpoint: str, method: str):
import time
start = time.time()
# ... ビジネスロジック ...
duration_ms = (time.time() - start) * 1000
request_counter.add(1, {"endpoint": endpoint, "method": method})
response_time.record(duration_ms, {"endpoint": endpoint})アラートポリシーの設計
アラートは本当に対応が必要なものだけに絞ることが重要です。アラート疲れ(Alert Fatigue)はSES現場で最も多い監視の失敗パターンです。
# CPU使用率のアラートポリシー作成
gcloud monitoring policies create \
--display-name="High CPU Usage - Production" \
--condition-display-name="CPU > 80% for 5 min" \
--condition-filter='resource.type = "gce_instance" AND metric.type = "compute.googleapis.com/instance/cpu/utilization"' \
--condition-threshold-value=0.8 \
--condition-threshold-comparison=COMPARISON_GT \
--condition-threshold-duration=300s \
--notification-channels="projects/my-project/notificationChannels/12345"
# 通知チャネルの作成(Slack連携)
gcloud monitoring channels create \
--type=slack \
--display-name="Production Alerts" \
--channel-labels=channel_name="#alerts-production"SES案件でのアラート設計テンプレート:
| 重要度 | 条件例 | 通知先 | 対応 |
|---|---|---|---|
| Critical | サービスダウン、エラー率>5% | PagerDuty + Slack | 即時対応 |
| Warning | CPU>80%、メモリ>85%、ディスク>90% | Slack | 営業時間内対応 |
| Info | デプロイ完了、スケーリング発生 | Slackログチャネル | 確認のみ |
MQL(Monitoring Query Language)
複雑なメトリクスクエリには、MQLが強力です。
-- 過去1時間のCloud Runリクエストレイテンシ P99
fetch cloud_run_revision
| metric 'run.googleapis.com/request_latencies'
| align delta(1m)
| every 1m
| group_by [resource.service_name],
[val: percentile(value.request_latencies, 99)]
-- GKE Podの再起動回数(異常検知)
fetch k8s_container
| metric 'kubernetes.io/container/restart_count'
| align rate(5m)
| every 5m
| filter val() > 0
| group_by [resource.pod_name], [restarts: sum(val())]Cloud Logging——ログの収集・分析・ルーティング
ログの自動収集
GCPサービスのログは自動的にCloud Loggingに送信されます。主要なログタイプは以下の通りです。
| ログタイプ | 内容 | 例 |
|---|---|---|
| 監査ログ | API呼び出しの記録 | VM作成、IAM変更 |
| アクセスログ | データアクセスの記録 | BigQueryクエリ、GCS読み取り |
| プラットフォームログ | サービス固有のログ | Cloud Run stdout/stderr |
| ユーザーログ | アプリケーション出力 | アプリのログ出力 |
ログエクスプローラでの検索
# エラーログの検索
severity >= ERROR
resource.type = "cloud_run_revision"
resource.labels.service_name = "my-api"
# 特定ユーザーのアクセスログ
jsonPayload.userId = "user-12345"
timestamp >= "2026-03-08T00:00:00Z"
# Cloud SQLのスロークエリ検出
resource.type = "cloudsql_database"
textPayload =~ "duration: [0-9]{4,} ms"
# IAM権限変更の監査
logName = "projects/my-project/logs/cloudaudit.googleapis.com%2Factivity"
protoPayload.methodName =~ "SetIamPolicy"構造化ログの実装
アプリケーションからCloud Loggingに構造化ログを送信することで、検索性と分析精度が大幅に向上します。
# Python: 構造化ログの送信
import json
import logging
import sys
class CloudLoggingFormatter(logging.Formatter):
"""Cloud Logging用の構造化ログフォーマッター"""
def format(self, record):
log_entry = {
"severity": record.levelname,
"message": record.getMessage(),
"timestamp": self.formatTime(record),
"logging.googleapis.com/sourceLocation": {
"file": record.pathname,
"line": record.lineno,
"function": record.funcName,
},
}
if hasattr(record, "user_id"):
log_entry["jsonPayload"] = {"userId": record.user_id}
if hasattr(record, "trace_id"):
log_entry["logging.googleapis.com/trace"] = record.trace_id
return json.dumps(log_entry)
# ロガーの設定
handler = logging.StreamHandler(sys.stdout)
handler.setFormatter(CloudLoggingFormatter())
logger = logging.getLogger("app")
logger.addHandler(handler)
logger.setLevel(logging.INFO)
# 使用例
logger.info("ユーザーログイン成功", extra={"user_id": "user-12345"})
logger.error("決済処理失敗", extra={"user_id": "user-12345", "trace_id": "abc-123"})ログルーター——ログのルーティングと保存最適化
Cloud Loggingのログルーター(シンク)は、ログのコスト最適化の要です。デフォルトでは全ログが_Defaultバケットに30日間保存されますが、ログルーターを使えば必要なログだけを適切な場所に振り分けられます。
# BigQueryへのログエクスポート(長期分析用)
gcloud logging sinks create bigquery-audit-sink \
bigquery.googleapis.com/projects/my-project/datasets/audit_logs \
--log-filter='logName = "projects/my-project/logs/cloudaudit.googleapis.com%2Factivity"' \
--description="監査ログをBigQueryにエクスポート"
# Cloud Storageへのログアーカイブ(コンプライアンス用)
gcloud logging sinks create gcs-archive-sink \
storage.googleapis.com/my-project-log-archive \
--log-filter='severity >= WARNING' \
--description="WARNING以上のログをGCSにアーカイブ"
# 不要なログの除外(コスト削減)
gcloud logging sinks update _Default \
--add-exclusion='name=exclude-debug,filter=severity = DEBUG'ログルーターのコスト最適化パターン:
┌─── BigQuery(監査ログ → 長期分析)
│
ログルーター ────────┼─── Cloud Storage(全ログ → アーカイブ)
│
├─── _Default バケット(30日保持、DEBUGを除外)
│
└─── 除外フィルター(ヘルスチェックログ → 廃棄)Ep.5のCloud Storageで学んだライフサイクル管理を組み合わせれば、アーカイブログのストレージクラスを自動的にNearline → Coldline → Archiveと移行させ、長期保存コストを最小化できます。
ダッシュボード構築——可視化のベストプラクティス
カスタムダッシュボードの設計原則
効果的なダッシュボードは、階層構造で設計します。
- エグゼクティブダッシュボード: SLO達成率、全体エラー率(経営層・PM向け)
- サービスダッシュボード: サービス別のゴールデンシグナル(開発チーム向け)
- インフラダッシュボード: CPU/メモリ/ディスク/ネットワーク(インフラチーム向け)
ゴールデンシグナルの実装
Googleが提唱するFour Golden Signals(レイテンシ、トラフィック、エラー、サチュレーション)をダッシュボードに実装します。
# ダッシュボードの作成(JSON定義)
cat > dashboard.json << 'EOF'
{
"displayName": "Production Service Dashboard",
"mosaicLayout": {
"tiles": [
{
"width": 6,
"height": 4,
"widget": {
"title": "リクエストレイテンシ (P50/P95/P99)",
"xyChart": {
"dataSets": [{
"timeSeriesQuery": {
"timeSeriesQueryLanguage": "fetch cloud_run_revision | metric 'run.googleapis.com/request_latencies' | align delta(1m) | every 1m | group_by [resource.service_name], [p50: percentile(value.request_latencies, 50), p95: percentile(value.request_latencies, 95), p99: percentile(value.request_latencies, 99)]"
}
}]
}
}
},
{
"xPos": 6,
"width": 6,
"height": 4,
"widget": {
"title": "エラー率 (%)",
"xyChart": {
"dataSets": [{
"timeSeriesQuery": {
"timeSeriesQueryLanguage": "fetch cloud_run_revision | metric 'run.googleapis.com/request_count' | align rate(1m) | every 1m | group_by [resource.service_name, metric.response_code_class], [val: sum(val())]"
}
}]
}
}
}
]
}
}
EOF
gcloud monitoring dashboards create --config-from-file=dashboard.jsonログベースメトリクス
ログからカスタムメトリクスを自動生成する機能です。コード変更なしに、既存のログからメトリクスを抽出できます。
# ログベースメトリクスの作成(エラーカウント)
gcloud logging metrics create payment_errors \
--description="決済処理エラーの発生回数" \
--log-filter='resource.type="cloud_run_revision" AND jsonPayload.error_type="payment_failed"'
# ログベースメトリクスの作成(レスポンスタイム分布)
gcloud logging metrics create api_latency \
--description="APIレスポンスタイム分布" \
--log-filter='resource.type="cloud_run_revision" AND jsonPayload.duration_ms > 0'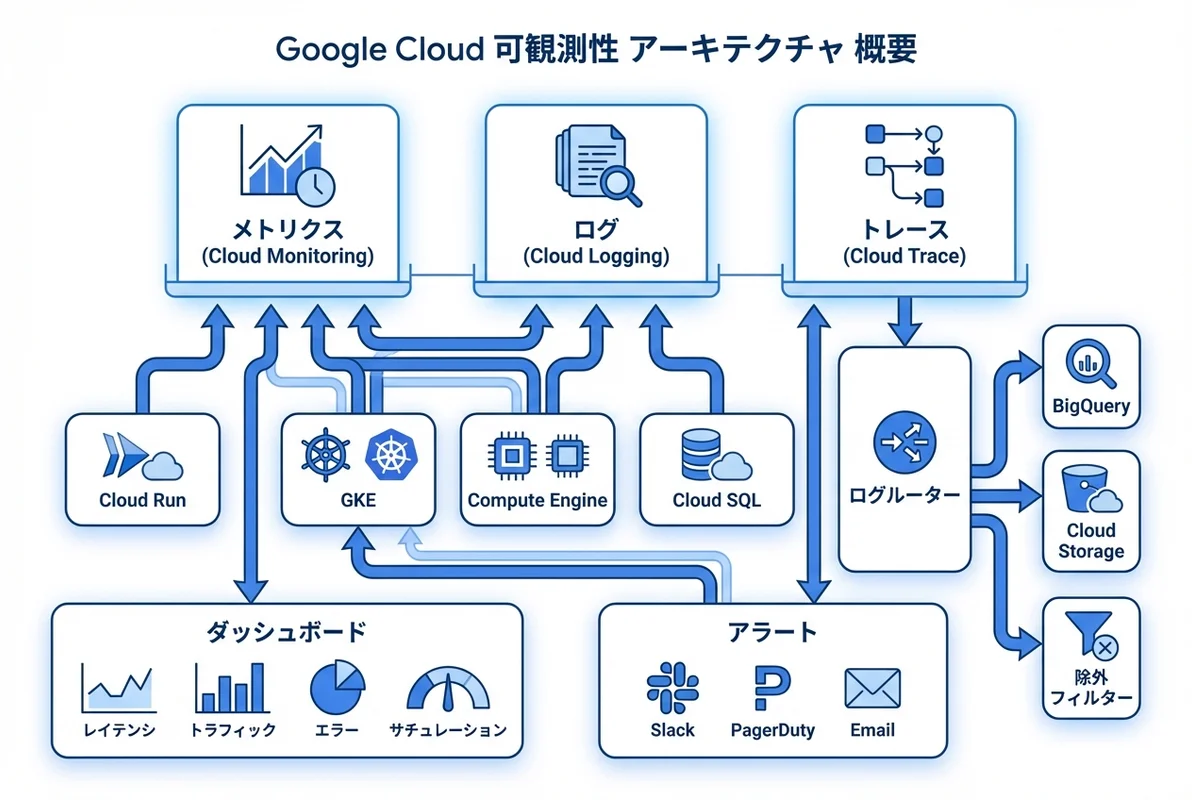
SLO監視——サービス品質の定量管理
SLI/SLO/SLAの関係
| 概念 | 定義 | 例 |
|---|---|---|
| SLI (Service Level Indicator) | サービス品質の測定指標 | リクエスト成功率、P99レイテンシ |
| SLO (Service Level Objective) | SLIの目標値 | 成功率99.9%、P99 < 500ms |
| SLA (Service Level Agreement) | 顧客との契約 | SLO未達時の補償規定 |
Cloud MonitoringでのSLO設定
# サービスの作成
gcloud monitoring services create my-api-service \
--display-name="My API Service"
# 可用性SLOの作成(99.9%)
gcloud monitoring slos create \
--service=my-api-service \
--display-name="Availability SLO" \
--goal=0.999 \
--rolling-period-days=28エラーバジェットの考え方が特に重要です。99.9%のSLOは、28日間で約40分の許容ダウンタイムを意味します。エラーバジェットが残っている間は新機能のリリースを許可し、消費しきったらリリースを凍結して安定性改善に集中する——これがSREの基本戦略です。
バーンレートアラート
エラーバジェットの消費速度(バーンレート)を監視し、異常な速度で消費されている場合にアラートを発報します。多段階バーンレートで設計するのがベストプラクティスです。
| ウィンドウ | バーンレート | 意味 | 対応 |
|---|---|---|---|
| 1時間 | 14.4x | 1時間で2%消費 | 即時対応(ページ) |
| 6時間 | 6x | 6時間で5%消費 | 早急対応(チケット) |
| 3日 | 1x | 通常速度 | 経過観察 |
実践テクニック——SES案件で差がつくノウハウ
Ops Agent(Compute Engine向け)
Compute EngineにOps Agentをインストールすると、OSレベルのメトリクス(プロセス別CPU、ディスクI/O)とアプリケーションログを自動収集できます。
# Ops Agentのインストール
curl -sSO https://dl.google.com/cloudagents/add-google-cloud-ops-agent-repo.sh
sudo bash add-google-cloud-ops-agent-repo.sh --also-install
# カスタムログ収集の設定
sudo tee /etc/google-cloud-ops-agent/config.yaml << 'EOF'
logging:
receivers:
app_log:
type: files
include_paths:
- /var/log/myapp/*.log
record_log_file_path: true
service:
pipelines:
app_pipeline:
receivers: [app_log]
metrics:
receivers:
nginx:
type: nginx
stub_status_url: http://localhost:8080/nginx_status
service:
pipelines:
nginx_pipeline:
receivers: [nginx]
EOF
sudo systemctl restart google-cloud-ops-agentGKEとの統合
Ep.8のGKEで構築したクラスタでは、GKE用のCloud Monitoringが自動で有効化されます。
# GKEクラスタでの監視設定確認
gcloud container clusters describe prod-cluster \
--region=asia-northeast1 \
--format="yaml(monitoringConfig,loggingConfig)"
# マネージドPrometheus(GMP)の有効化
gcloud container clusters update prod-cluster \
--region=asia-northeast1 \
--enable-managed-prometheusGoogle Managed Prometheus(GMP)を使えば、既存のPromQLクエリやGrafanaダッシュボードをそのまま流用しつつ、バックエンドはフルマネージドで運用できます。
# PodMonitorの定義(GMP用)
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: web-app-monitoring
spec:
selector:
matchLabels:
app: web-app
endpoints:
- port: metrics
interval: 30s
path: /metricsアラート通知のルーティング
# PagerDuty連携
gcloud monitoring channels create \
--type=pagerduty \
--display-name="PagerDuty Production" \
--channel-labels=service_key="YOUR_PAGERDUTY_KEY"
# Webhook連携(カスタム自動化)
gcloud monitoring channels create \
--type=webhook_tokenauth \
--display-name="Auto-remediation Webhook" \
--channel-labels=url="https://my-api.example.com/alerts/webhook"コスト最適化——Cloud Operations Suiteの費用管理
Cloud Monitoring/Loggingは無料枠が用意されていますが、大規模環境では費用が増大します。
| 項目 | 無料枠 | 超過料金(目安) |
|---|---|---|
| Monitoring メトリクス | GCPメトリクスは無料 | カスタム: $0.258/1000サンプル |
| Logging 取り込み | 50 GiB/月 | $0.50/GiB |
| Logging 保存 | デフォルト30日は無料 | カスタム: $0.01/GiB/月 |
| Trace スパン | 250万スパン/月 | $0.20/100万スパン |
コスト削減テクニック
# 1. 不要ログの除外(最もインパクト大)
gcloud logging sinks update _Default \
--add-exclusion='name=exclude-healthcheck,filter=httpRequest.requestUrl="/healthz"' \
--add-exclusion='name=exclude-debug,filter=severity="DEBUG"'
# 2. ログバケットの保持期間最適化
gcloud logging buckets update _Default \
--location=global \
--retention-days=7 # 30日→7日に短縮
# 3. サンプリングの活用(ログの10%だけ取り込み)
gcloud logging sinks update _Default \
--add-exclusion='name=sample-access-logs,filter=resource.type="cloud_run_revision" AND sample(insertId, 0.9)'SES案件で使える監視設計テンプレート
中規模Webサービスの監視構成
Cloud Monitoring
├── ダッシュボード
│ ├── エグゼクティブ: SLO達成率、月次トレンド
│ ├── サービス: ゴールデンシグナル(レイテンシ/トラフィック/エラー/サチュレーション)
│ └── インフラ: CPU/メモリ/ディスク/ネットワーク
├── アラートポリシー
│ ├── Critical: サービスダウン、エラー率>5%、SLOバーンレート高
│ ├── Warning: CPU>80%、メモリ>85%、ディスク>90%
│ └── Info: デプロイ完了、スケーリングイベント
├── SLO
│ ├── 可用性: 99.9%(28日ローリング)
│ └── レイテンシ: P99 < 500ms
└── 通知チャネル
├── Critical → PagerDuty + Slack #alerts-critical
├── Warning → Slack #alerts-warning
└── Info → Slack #alerts-info
Cloud Logging
├── ログルーター
│ ├── 監査ログ → BigQuery(長期分析)
│ ├── WARNING以上 → Cloud Storage(アーカイブ)
│ └── ヘルスチェック/DEBUG → 除外
├── ログベースメトリクス
│ ├── payment_errors(決済エラー数)
│ └── api_latency(レスポンスタイム)
└── ログバケット
├── _Default: 7日保持(コスト最適化)
└── _Required: 400日保持(変更不可、監査ログ)まとめ——オブザーバビリティはSRE案件への入口
Cloud MonitoringとCloud Loggingは、Google Cloudのオブザーバビリティの中核です。本記事で解説した内容を振り返ります。
- Cloud MonitoringはGCPリソースのメトリクスを自動収集し、カスタムメトリクスやMQLで高度な分析が可能
- Cloud Loggingはログの一元管理と検索を提供し、ログルーターでコストを最適化
- SLO監視とエラーバジェットで、サービス品質を定量的に管理
- ゴールデンシグナル(レイテンシ・トラフィック・エラー・サチュレーション)を基本にダッシュボードを設計
- ログベースメトリクスで、既存ログからコード変更なしにメトリクスを抽出
- GKE連携ではGoogle Managed Prometheusでフルマネージド運用が可能
- コスト管理はログ除外・保持期間短縮・サンプリングの3つが柱
Ep.1でプロジェクトを作成し、Ep.6のIAM設計で権限を整え、Ep.8のGKEでワークロードを構築したら、この記事のオブザーバビリティ設計で運用の仕上げを行いましょう。
監視・ログ管理の知識は、SES市場で急増しているSRE案件への参入チケットでもあります。Cloud Monitoring/Loggingを使いこなし、「設計・構築・運用」をワンストップで提案できるエンジニアを目指しましょう。
次回のGoogle Cloud 完全攻略もお楽しみに!
出典・参考資料
- Cloud Monitoring の概要 — Google Cloud
- Cloud Logging の概要 — Google Cloud
- MQL リファレンス — Google Cloud
- SLO の設定 — Google Cloud
- ログルーターの概要 — Google Cloud
- Google Managed Prometheus — Google Cloud
- Ops Agent の概要 — Google Cloud
- Cloud Operations Suite の料金 — Google Cloud
関連記事





