
- Gemini Code AssistはGoogle Cloudに最適化されたAIコーディング支援ツール
- コード生成・変換・デバッグに加え、Cloud Run・GKE・BigQuery連携コードを自動生成
- 無料枠で月6,000回のコード補完が利用可能、SES現場での即戦力ツール
「Google Cloud上のアプリ開発でもAIコーディング支援を使いたい」「Geminiの力でCloud RunやBigQueryの開発を加速したい」——Google Cloud開発者のそんなニーズに応えるのがGemini Code Assistです。
Gemini Code Assistは、Google CloudのGeminiモデルを基盤とした AIコーディングアシスタントです。Google Cloudの全サービスについての深い知識を持ち、IDE内でコード生成・変換・デバッグ・最適化を提供します。
この記事では、Gemini Code Assistのセットアップから実践的な活用法、SES現場での差別化戦略まで解説します。
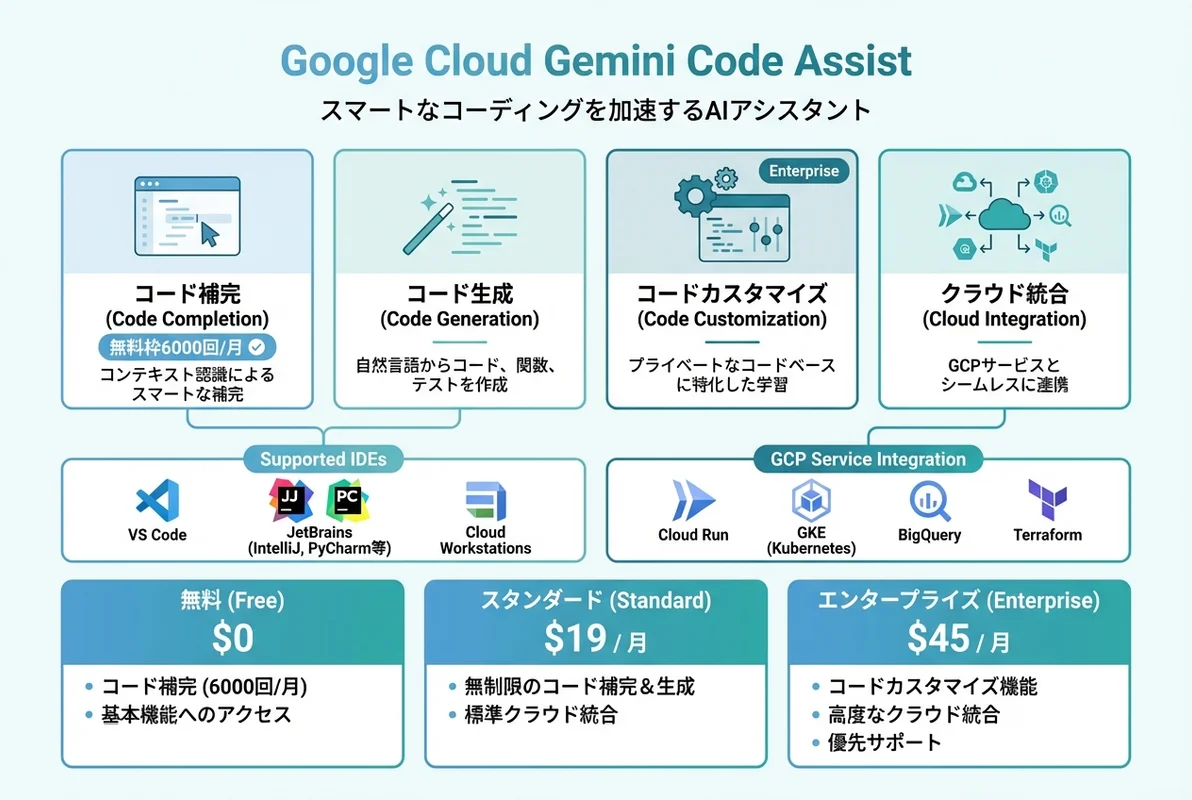
Gemini Code Assistとは?
概要と特徴
Gemini Code Assistは、Google Cloudが提供するAI搭載の開発支援ツールです。Gemini 2.5モデルをベースに、Google Cloudのサービス群との深い統合を実現しています。
| 機能 | 説明 |
|---|---|
| コード補完 | リアルタイムのインライン補完(6,000回/月無料) |
| コード生成 | 自然言語プロンプトからの機能実装 |
| コードカスタマイズ | プライベートコードベースを参照した補完 |
| コード変換 | 言語・フレームワーク間の自動変換 |
| チャット支援 | IDE内でのQ&A・デバッグ支援 |
| Cloud統合 | GCP固有のコード・設定生成 |
料金プラン
| プラン | 月額 | コード補完 | チャット |
|---|---|---|---|
| Free | $0 | 6,000回/月 | 240回/月 |
| Standard | $19/ユーザー | 無制限 | 無制限 |
| Enterprise | $45/ユーザー | 無制限 + コードカスタマイズ | 無制限 |
対応環境
対応IDE: VS Code, IntelliJ IDEA, JetBrains系全般, Cloud Shell Editor, Cloud Workstations
対応言語: Python, Java, JavaScript/TypeScript, Go, C/C++, Kotlin, PHP, Ruby, Rust, SQL, Terraform, Dockerfileなど20+言語
セットアップ
VS Codeでの導入
# 1. Cloud Code拡張機能をインストール
# VS Code → Extensions → "Cloud Code" を検索・インストール
# 2. Google Cloudアカウントでログイン
# Command Palette → "Cloud Code: Sign in"
# 3. Gemini Code Assistの有効化
# Cloud Code設定 → Gemini → Enable Code AssistGoogle Cloud CLIでの設定
# gcloudの認証
gcloud auth login
gcloud config set project YOUR_PROJECT_ID
# Gemini Code Assist APIの有効化
gcloud services enable cloudaicompanion.googleapis.com
# 動作確認
gcloud gemini code-assist statusCloud Workstationsでの利用
Cloud Workstationsを使用する場合、Gemini Code Assistがプリインストールされています:
# Cloud Workstationsの作成
gcloud workstations create my-workspace \
--cluster=my-cluster \
--config=my-config \
--region=asia-northeast1
# ブラウザIDEが自動起動し、Gemini Code Assist利用可能実践パターン1:Cloud Runアプリケーション開発
Cloud Run用のAPIサーバー自動生成
Gemini Code Assistに要件を伝えてCloud Run向けアプリを自動生成:
プロンプト: 「Cloud Run上で動作するREST APIサーバーを作成して。
ユーザーCRUD、Cloud SQLとの接続、認証はFirebase Authを使用」生成されるコード:
# main.py - Cloud Run用APIサーバー
from fastapi import FastAPI, HTTPException, Depends
from google.cloud import sql
import firebase_admin
from firebase_admin import auth as firebase_auth
import os
app = FastAPI(title="User API", version="1.0.0")
# Firebase初期化
firebase_admin.initialize_app()
# Cloud SQL接続
def get_db():
import sqlalchemy
db_user = os.environ["DB_USER"]
db_pass = os.environ["DB_PASS"]
db_name = os.environ["DB_NAME"]
instance_connection = os.environ["INSTANCE_CONNECTION_NAME"]
pool = sqlalchemy.create_engine(
sqlalchemy.engine.url.URL.create(
drivername="postgresql+pg8000",
username=db_user,
password=db_pass,
database=db_name,
query={"unix_sock": f"/cloudsql/{instance_connection}/.s.PGSQL.5432"}
)
)
return pool
# Firebase認証ミドルウェア
async def verify_token(authorization: str = None):
if not authorization or not authorization.startswith("Bearer "):
raise HTTPException(status_code=401, detail="Invalid token")
token = authorization.split("Bearer ")[1]
try:
decoded = firebase_auth.verify_id_token(token)
return decoded
except Exception:
raise HTTPException(status_code=401, detail="Token verification failed")
@app.get("/users/{user_id}")
async def get_user(user_id: str, current_user=Depends(verify_token)):
db = get_db()
with db.connect() as conn:
result = conn.execute(
sqlalchemy.text("SELECT * FROM users WHERE id = :id"),
{"id": user_id}
)
user = result.fetchone()
if not user:
raise HTTPException(status_code=404, detail="User not found")
return dict(user._mapping)
@app.post("/users")
async def create_user(user_data: dict, current_user=Depends(verify_token)):
db = get_db()
with db.connect() as conn:
conn.execute(
sqlalchemy.text(
"INSERT INTO users (id, name, email) VALUES (:id, :name, :email)"
),
user_data
)
conn.commit()
return {"status": "created", "id": user_data["id"]}Dockerfile自動生成
# Gemini Code Assistが生成するDockerfile
FROM python:3.12-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
# Cloud Runのデフォルトポート
ENV PORT=8080
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8080"]Cloud Runデプロイ設定
# cloudbuild.yaml(Gemini Code Assist生成)
steps:
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'asia-northeast1-docker.pkg.dev/$PROJECT_ID/app/user-api:$COMMIT_SHA', '.']
- name: 'gcr.io/cloud-builders/docker'
args: ['push', 'asia-northeast1-docker.pkg.dev/$PROJECT_ID/app/user-api:$COMMIT_SHA']
- name: 'gcr.io/google.com/cloudsdktool/cloud-sdk'
entrypoint: gcloud
args:
- 'run'
- 'deploy'
- 'user-api'
- '--image=asia-northeast1-docker.pkg.dev/$PROJECT_ID/app/user-api:$COMMIT_SHA'
- '--region=asia-northeast1'
- '--platform=managed'
- '--allow-unauthenticated'
- '--set-env-vars=DB_USER=$$DB_USER,DB_PASS=$$DB_PASS,DB_NAME=$$DB_NAME'
- '--add-cloudsql-instances=$$INSTANCE_CONNECTION_NAME'実践パターン2:BigQueryデータ分析
SQLクエリの自動生成
Gemini Code Assistに自然言語で分析要件を伝えると、BigQuery向けSQLを生成:
プロンプト: 「過去30日間の日別アクティブユーザー数と新規登録数を
前月比で分析するSQLを作成して。結果はGoogle Sheetsに連携したい」-- Gemini Code Assistが生成するBigQuery SQL
WITH daily_metrics AS (
SELECT
DATE(event_timestamp) AS date,
COUNT(DISTINCT user_id) AS daily_active_users,
COUNTIF(event_name = 'first_open') AS new_users
FROM `project.analytics.events_*`
WHERE _TABLE_SUFFIX BETWEEN
FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 60 DAY))
AND FORMAT_DATE('%Y%m%d', CURRENT_DATE())
GROUP BY date
),
with_prev_month AS (
SELECT
dm.*,
LAG(dm.daily_active_users, 30) OVER (ORDER BY dm.date) AS prev_month_dau,
LAG(dm.new_users, 30) OVER (ORDER BY dm.date) AS prev_month_new_users
FROM daily_metrics dm
)
SELECT
date,
daily_active_users,
new_users,
prev_month_dau,
prev_month_new_users,
SAFE_DIVIDE(daily_active_users - prev_month_dau, prev_month_dau) * 100 AS dau_growth_pct,
SAFE_DIVIDE(new_users - prev_month_new_users, prev_month_new_users) * 100 AS new_user_growth_pct
FROM with_prev_month
WHERE date >= DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)
ORDER BY date DESC;Pythonでのデータ分析パイプライン
# Gemini Code Assistが生成するデータ分析コード
from google.cloud import bigquery
import pandas as pd
import matplotlib.pyplot as plt
client = bigquery.Client()
def analyze_user_trends():
"""過去30日間のユーザートレンドを分析"""
query = """
SELECT
DATE(event_timestamp) AS date,
COUNT(DISTINCT user_id) AS dau,
COUNTIF(event_name = 'purchase') AS purchases,
SUM(IF(event_name = 'purchase', event_value, 0)) AS revenue
FROM `project.analytics.events_*`
WHERE _TABLE_SUFFIX >= FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY))
GROUP BY date
ORDER BY date
"""
df = client.query(query).to_dataframe()
# トレンド可視化
fig, axes = plt.subplots(3, 1, figsize=(12, 10))
axes[0].plot(df['date'], df['dau'], marker='o')
axes[0].set_title('Daily Active Users')
axes[0].set_ylabel('Users')
axes[1].bar(df['date'], df['purchases'], color='orange')
axes[1].set_title('Daily Purchases')
axes[1].set_ylabel('Count')
axes[2].fill_between(df['date'], df['revenue'], alpha=0.3, color='green')
axes[2].plot(df['date'], df['revenue'], color='green')
axes[2].set_title('Daily Revenue')
axes[2].set_ylabel('JPY')
plt.tight_layout()
plt.savefig('user_trends.png', dpi=150)
return df
if __name__ == '__main__':
result = analyze_user_trends()
print(result.describe())実践パターン3:GKE(Kubernetes)デプロイメント
マニフェスト自動生成
プロンプト: 「GKEにデプロイするマイクロサービスのKubernetesマニフェストを生成して。
HPA、PDB、NetworkPolicy付きで」# Gemini Code Assistが生成するKubernetesマニフェスト
apiVersion: apps/v1
kind: Deployment
metadata:
name: user-service
namespace: production
spec:
replicas: 3
selector:
matchLabels:
app: user-service
template:
metadata:
labels:
app: user-service
spec:
serviceAccountName: user-service-sa
containers:
- name: user-service
image: asia-northeast1-docker.pkg.dev/project/app/user-service:latest
ports:
- containerPort: 8080
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 10
periodSeconds: 30
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
env:
- name: DB_HOST
valueFrom:
secretKeyRef:
name: db-credentials
key: host
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: user-service-hpa
namespace: production
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: user-service
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
---
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: user-service-pdb
namespace: production
spec:
minAvailable: 2
selector:
matchLabels:
app: user-service
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: user-service-netpol
namespace: production
spec:
podSelector:
matchLabels:
app: user-service
policyTypes:
- Ingress
- Egress
ingress:
- from:
- podSelector:
matchLabels:
app: api-gateway
ports:
- port: 8080
egress:
- to:
- podSelector:
matchLabels:
app: postgres
ports:
- port: 5432実践パターン4:Terraformインフラコード
Google Cloud環境の自動構築
# Gemini Code Assistが生成するTerraformコード
# GKE + Cloud SQL + Memorystore の本番環境
terraform {
required_version = ">= 1.5"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 5.0"
}
}
backend "gcs" {
bucket = "terraform-state-bucket"
prefix = "production"
}
}
# VPCネットワーク
resource "google_compute_network" "main" {
name = "production-vpc"
auto_create_subnetworks = false
}
resource "google_compute_subnetwork" "nodes" {
name = "gke-nodes"
ip_cidr_range = "10.0.0.0/20"
region = "asia-northeast1"
network = google_compute_network.main.id
secondary_ip_range {
range_name = "pods"
ip_cidr_range = "10.4.0.0/14"
}
secondary_ip_range {
range_name = "services"
ip_cidr_range = "10.8.0.0/20"
}
}
# GKEクラスタ
resource "google_container_cluster" "primary" {
name = "production-cluster"
location = "asia-northeast1"
network = google_compute_network.main.name
subnetwork = google_compute_subnetwork.nodes.name
ip_allocation_policy {
cluster_secondary_range_name = "pods"
services_secondary_range_name = "services"
}
release_channel {
channel = "REGULAR"
}
workload_identity_config {
workload_pool = "${var.project_id}.svc.id.goog"
}
# Autopilotモード
enable_autopilot = true
}
# Cloud SQL
resource "google_sql_database_instance" "main" {
name = "production-db"
database_version = "POSTGRES_16"
region = "asia-northeast1"
settings {
tier = "db-custom-4-16384"
availability_type = "REGIONAL"
backup_configuration {
enabled = true
point_in_time_recovery_enabled = true
}
ip_configuration {
ipv4_enabled = false
private_network = google_compute_network.main.id
}
}
}コードカスタマイズ機能(Enterprise)
プライベートコードベースの学習
Enterprise版では、組織のプライベートリポジトリを基にした補完が可能:
# コードカスタマイズの設定
gcloud gemini code-assist customizations create \
--repository=https://github.com/org/private-repo \
--branch=main \
--display-name="Our Coding Standards"これにより:
- 社内のコーディング規約に沿った補完
- 共通ライブラリの使い方を学習した提案
- プロジェクト固有のパターンに合わせたコード生成
SES現場での活用戦略
Google Cloud案件での差別化
| スキルセット | 月単価の目安 | 需要トレンド |
|---|---|---|
| GCP基礎 + Gemini Code Assist | 55-65万円 | 急上昇 ↑↑ |
| GCP Professional + AI活用 | 70-85万円 | 上昇 ↑ |
| GCP Architect + IaC + AI | 85-100万円 | 安定 → |
面談・提案でのアピールポイント
- Gemini Code Assistを使った開発速度向上の実績
- Google Cloud固有のベストプラクティスへの理解
- IaC(Terraform/CDK)の自動生成スキル
- BigQuery + Geminiによるデータ分析効率化
他ツールとの比較
| 機能 | Gemini Code Assist | GitHub Copilot | AWS Q Developer |
|---|---|---|---|
| GCP特化 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐ |
| AWS特化 | ⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 汎用性 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 無料枠 | 6,000回/月 | なし | 500回/月 |
| コードカスタマイズ | ✅(Enterprise) | ✅(Enterprise) | ❌ |
トラブルシューティング
Q: 補完が遅い・表示されない
A: ネットワーク接続とGcloud認証を確認。Cloud Workstationsでの利用が最も安定します。
Q: Google Cloud固有の提案が出ない
A: プロジェクト内にGoogle Cloudの設定ファイル(app.yaml, cloudbuild.yaml, Terraform files)があると、コンテキストが改善されます。
Q: Enterprise版のコードカスタマイズが反映されない
A: インデックス作成に最大24時間かかります。gcloud gemini code-assist customizations describeで状態を確認してください。
まとめ
Gemini Code Assistは、Google Cloud開発者にとって生産性を劇的に向上させるパートナーです。
導入チェックリスト
- ✅ Cloud Code拡張機能のインストール
- ✅ Google Cloud認証の設定
- ✅ Gemini Code Assist APIの有効化
- ✅ 無料枠での動作確認
- ✅ チームへの展開計画
Google Cloud案件でのAI活用スキルは、SES市場での強力な差別化要因です。SES BASEでは、Google Cloud関連の案件を多数掲載しています。 GCP案件を探す で、最新の案件をチェックしてください。





