
⚡ 3秒でわかる!この記事のポイント
- Cloud SQLのパフォーマンスチューニングでクエリ応答速度を最大10倍改善する手法
- 高可用性(HA)構成とリードレプリカによるスケーラブルなDB設計
- コスト最適化で月額30-50%のDB費用削減を実現するテクニック
「Cloud SQLのレスポンスが遅い」「データベースのコストが予想以上に高い」「可用性を上げたいが構成がわからない」——Google Cloud上でRDBを運用するSESエンジニアが直面する典型的な課題です。
結論から言えば、Cloud SQLの最適化は「インスタンス設定」「クエリチューニング」「高可用性設計」「コスト管理」の4つの柱で体系的に取り組めば、パフォーマンスとコストの両方を大幅に改善できます。 この記事では、それぞれの柱について具体的な手順と設定例を解説します。
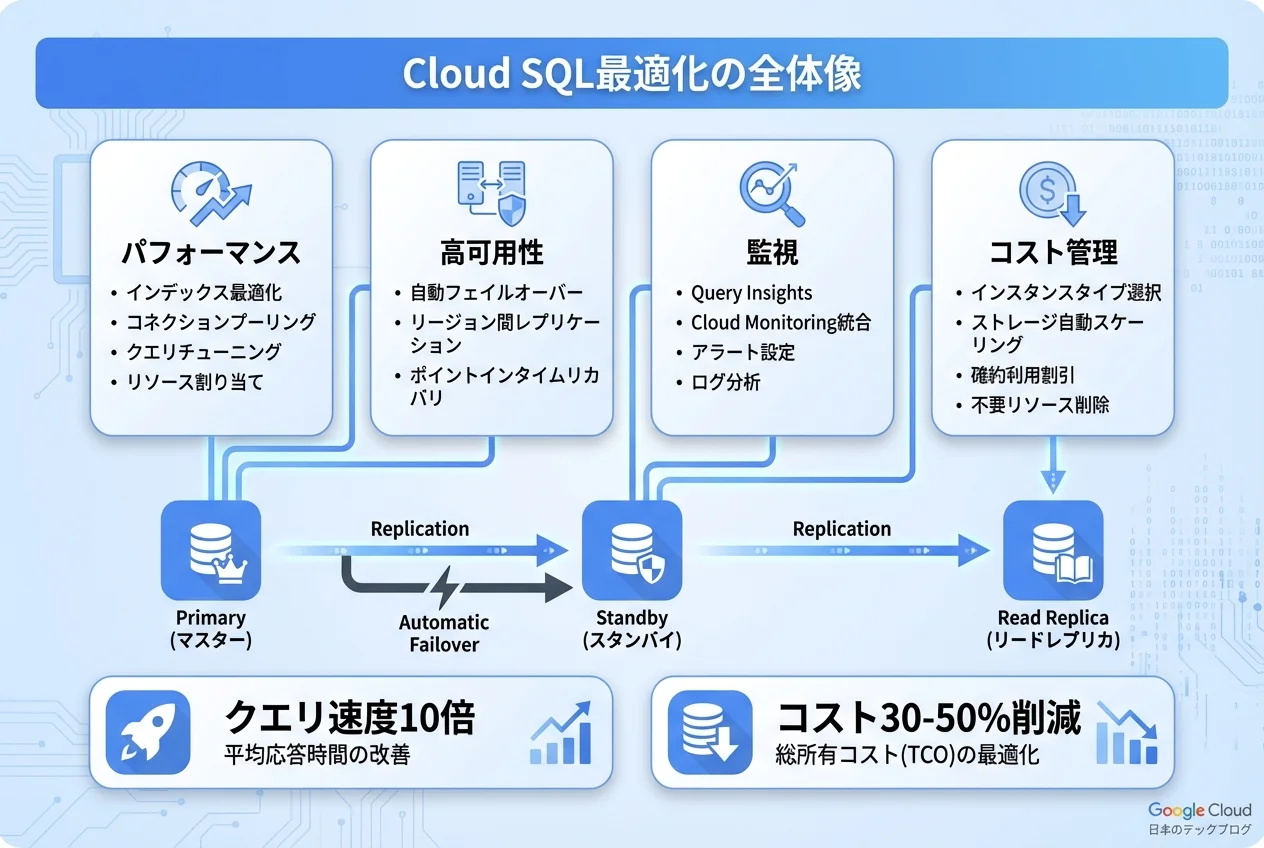
Cloud SQLの基本アーキテクチャ
Cloud SQLとは
Cloud SQLは、Google Cloudが提供するフルマネージドリレーショナルデータベースサービスです。MySQL、PostgreSQL、SQL Serverの3つのエンジンをサポートしています。
| 特性 | Cloud SQL | セルフマネージド |
|---|---|---|
| パッチ適用 | 自動 | 手動 |
| バックアップ | 自動(設定可能) | 手動設定 |
| フェイルオーバー | 自動(HA構成時) | 手動構築 |
| レプリケーション | マネージド | 手動構築 |
| 監視 | Cloud Monitoring統合 | 手動設定 |
| スケーリング | 垂直(手動/自動) | 手動 |
| 月額コスト | $50-2,000+ | EC2 + 管理工数 |
Cloud SQLのエディション
| エディション | 用途 | vCPU | メモリ | ストレージ |
|---|---|---|---|---|
| Enterprise | 本番ワークロード | 最大96 | 最大624GB | 最大64TB |
| Enterprise Plus | 高性能要件 | 最大128 | 最大864GB | 最大64TB |
パフォーマンスチューニング
1. インスタンスサイズの最適化
Cloud SQLのパフォーマンスは、インスタンスサイズに大きく依存します。
# 現在のインスタンス情報を確認
gcloud sql instances describe my-instance \
--format="table(
name,
settings.tier,
settings.dataDiskSizeGb,
settings.dataDiskType
)"サイジングガイドライン
| ワークロード | 推奨vCPU | 推奨メモリ | ストレージ |
|---|---|---|---|
| 開発/テスト | 1-2 | 3.75-7.5GB | SSD 10-50GB |
| 小規模Web | 2-4 | 7.5-15GB | SSD 50-100GB |
| 中規模Web | 4-8 | 15-30GB | SSD 100-500GB |
| 大規模Web | 8-16 | 30-60GB | SSD 500GB-1TB |
| データ分析 | 16-32 | 60-120GB | SSD 1-5TB |
# インスタンスサイズの変更
gcloud sql instances patch my-instance \
--tier=db-custom-4-15360 \
--storage-size=100GB \
--storage-type=SSD2. クエリパフォーマンスの最適化
Query Insightsの有効化
# Query Insights を有効化
gcloud sql instances patch my-instance \
--insights-config-query-insights-enabled \
--insights-config-query-string-length=4096 \
--insights-config-record-application-tags \
--insights-config-record-client-addressスロークエリの特定と改善
-- PostgreSQL: 実行時間の長いクエリを特定
SELECT
query,
calls,
total_exec_time / 1000 as total_time_sec,
mean_exec_time / 1000 as avg_time_sec,
rows
FROM pg_stat_statements
ORDER BY total_exec_time DESC
LIMIT 20;
-- MySQL: スロークエリログの確認
SELECT
digest_text,
count_star as exec_count,
avg_timer_wait / 1000000000 as avg_time_ms,
sum_rows_examined,
sum_rows_sent
FROM performance_schema.events_statements_summary_by_digest
ORDER BY avg_timer_wait DESC
LIMIT 20;インデックス最適化
-- PostgreSQL: 未使用インデックスの検出
SELECT
schemaname || '.' || relname AS table_name,
indexrelname AS index_name,
idx_scan AS times_used,
pg_size_pretty(pg_relation_size(indexrelid)) AS index_size
FROM pg_stat_user_indexes
WHERE idx_scan = 0
AND schemaname NOT IN ('pg_catalog', 'information_schema')
ORDER BY pg_relation_size(indexrelid) DESC;
-- 効果の高いインデックスの追加例
-- 複合インデックス(カバリングインデックス)
CREATE INDEX idx_orders_user_status
ON orders (user_id, status)
INCLUDE (total_amount, created_at);
-- 部分インデックス(特定条件のみ)
CREATE INDEX idx_orders_active
ON orders (created_at)
WHERE status IN ('pending', 'processing');
-- MySQL: インデックス使用状況の確認
EXPLAIN ANALYZE
SELECT * FROM orders
WHERE user_id = 123
AND status = 'pending'
ORDER BY created_at DESC
LIMIT 10;3. 接続管理の最適化
Cloud SQL Auth Proxy
# Cloud SQL Auth Proxyの起動
cloud-sql-proxy \
--address 0.0.0.0 \
--port 5432 \
--structured-logs \
--max-connections 100 \
--max-sigterm-delay 30s \
my-project:asia-northeast1:my-instanceコネクションプーリング
# PgBouncer設定(PostgreSQL)
# pgbouncer.ini
[databases]
mydb = host=localhost port=5432 dbname=mydb
[pgbouncer]
listen_port = 6432
listen_addr = 0.0.0.0
auth_type = md5
pool_mode = transaction
max_client_conn = 1000
default_pool_size = 25
min_pool_size = 5
reserve_pool_size = 5
reserve_pool_timeout = 3
server_idle_timeout = 600アプリケーション側の接続プール設定
// Node.js (pg) の接続プール設定
import { Pool } from 'pg';
const pool = new Pool({
host: '/cloudsql/project:region:instance',
database: 'mydb',
user: 'app_user',
password: process.env.DB_PASSWORD,
// 接続プール設定
max: 20, // 最大接続数
min: 5, // 最小接続数
idleTimeoutMillis: 30000, // アイドル接続のタイムアウト
connectionTimeoutMillis: 5000, // 接続タイムアウト
// ステートメントタイムアウト
statement_timeout: 30000,
});
// ヘルスチェック
pool.on('error', (err) => {
console.error('データベース接続エラー:', err);
});
// クエリ実行例
async function getOrders(userId: string) {
const client = await pool.connect();
try {
const result = await client.query(
'SELECT * FROM orders WHERE user_id = $1 ORDER BY created_at DESC LIMIT 50',
[userId]
);
return result.rows;
} finally {
client.release();
}
}4. データベースフラグのチューニング
# PostgreSQL のチューニングフラグ
gcloud sql instances patch my-instance \
--database-flags="\
shared_buffers=4096MB,\
effective_cache_size=12288MB,\
work_mem=64MB,\
maintenance_work_mem=512MB,\
max_connections=200,\
random_page_cost=1.1,\
effective_io_concurrency=200,\
wal_buffers=64MB,\
max_wal_size=2GB,\
checkpoint_completion_target=0.9,\
log_min_duration_statement=1000"# MySQL のチューニングフラグ
gcloud sql instances patch my-instance \
--database-flags="\
innodb_buffer_pool_size=4294967296,\
innodb_log_file_size=536870912,\
innodb_flush_log_at_trx_commit=2,\
innodb_flush_method=O_DIRECT,\
max_connections=200,\
slow_query_log=on,\
long_query_time=1,\
innodb_io_capacity=2000,\
innodb_io_capacity_max=4000"高可用性(HA)構成
リージョナルHA構成
# HA構成のインスタンス作成
gcloud sql instances create my-ha-instance \
--database-version=POSTGRES_16 \
--tier=db-custom-4-15360 \
--region=asia-northeast1 \
--availability-type=REGIONAL \
--storage-type=SSD \
--storage-size=100GB \
--storage-auto-increase \
--backup-start-time=02:00 \
--enable-point-in-time-recovery \
--retained-backups-count=14 \
--maintenance-window-day=SUN \
--maintenance-window-hour=3リードレプリカの設定
# リードレプリカの作成
gcloud sql instances create my-read-replica \
--master-instance-name=my-ha-instance \
--tier=db-custom-2-7680 \
--region=asia-northeast1
# 複数リージョンレプリカ(災害復旧用)
gcloud sql instances create my-dr-replica \
--master-instance-name=my-ha-instance \
--tier=db-custom-2-7680 \
--region=us-central1アプリケーション側の読み書き分離
// 読み書き分離の実装例
import { Pool } from 'pg';
// プライマリ(書き込み用)
const primaryPool = new Pool({
host: '/cloudsql/project:asia-northeast1:my-ha-instance',
database: 'mydb',
max: 20,
});
// レプリカ(読み取り用)
const replicaPool = new Pool({
host: '/cloudsql/project:asia-northeast1:my-read-replica',
database: 'mydb',
max: 30,
});
class DatabaseService {
// 書き込みはプライマリへ
async createOrder(order: Order): Promise<Order> {
const client = await primaryPool.connect();
try {
const result = await client.query(
'INSERT INTO orders (user_id, total) VALUES ($1, $2) RETURNING *',
[order.userId, order.total]
);
return result.rows[0];
} finally {
client.release();
}
}
// 読み取りはレプリカへ
async getOrders(userId: string): Promise<Order[]> {
const client = await replicaPool.connect();
try {
const result = await client.query(
'SELECT * FROM orders WHERE user_id = $1 ORDER BY created_at DESC',
[userId]
);
return result.rows;
} finally {
client.release();
}
}
// 強い一貫性が必要な読み取りはプライマリへ
async getOrderForUpdate(orderId: string): Promise<Order> {
const client = await primaryPool.connect();
try {
const result = await client.query(
'SELECT * FROM orders WHERE id = $1 FOR UPDATE',
[orderId]
);
return result.rows[0];
} finally {
client.release();
}
}
}バックアップとリカバリ
自動バックアップの設定
# バックアップ設定の確認
gcloud sql instances describe my-instance \
--format="table(
settings.backupConfiguration.enabled,
settings.backupConfiguration.startTime,
settings.backupConfiguration.pointInTimeRecoveryEnabled,
settings.backupConfiguration.retainedBackups
)"
# PITR(ポイントインタイムリカバリ)の有効化
gcloud sql instances patch my-instance \
--enable-point-in-time-recovery \
--retained-backups-count=14 \
--retained-transaction-log-days=7リストア手順
# 特定時点へのリストア
gcloud sql instances clone my-instance my-instance-restored \
--point-in-time="2026-03-14T15:30:00.000Z"
# バックアップからのリストア
gcloud sql backups list --instance=my-instance
gcloud sql backups restore BACKUP_ID \
--restore-instance=my-instance \
--backup-instance=my-instance監視とアラート
Cloud Monitoringダッシュボード
# 主要メトリクスの確認
gcloud monitoring metrics list \
--filter="metric.type = starts_with('cloudsql.googleapis.com')" \
--format="table(name, description)"重要な監視メトリクス
| メトリクス | 説明 | アラート閾値 |
|---|---|---|
| CPU使用率 | インスタンスCPU使用率 | > 80% で警告 |
| メモリ使用率 | バッファプール使用率 | > 90% で警告 |
| ディスク使用率 | ストレージ使用率 | > 85% で警告 |
| 接続数 | アクティブ接続数 | > max_connections × 80% |
| レプリケーション遅延 | レプリカの遅延時間 | > 5秒で警告 |
| クエリ実行時間 | 平均クエリ実行時間 | > 1秒で警告 |
Terraformでアラート設定
resource "google_monitoring_alert_policy" "cloud_sql_cpu" {
display_name = "Cloud SQL CPU使用率アラート"
combiner = "OR"
conditions {
display_name = "CPU使用率 > 80%"
condition_threshold {
filter = "resource.type = \"cloudsql_database\" AND metric.type = \"cloudsql.googleapis.com/database/cpu/utilization\""
comparison = "COMPARISON_GT"
threshold_value = 0.8
duration = "300s"
aggregations {
alignment_period = "60s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
notification_channels = [
google_monitoring_notification_channel.slack.name
]
alert_strategy {
auto_close = "1800s"
}
}
resource "google_monitoring_alert_policy" "cloud_sql_disk" {
display_name = "Cloud SQL ディスク使用率アラート"
combiner = "OR"
conditions {
display_name = "ディスク使用率 > 85%"
condition_threshold {
filter = "resource.type = \"cloudsql_database\" AND metric.type = \"cloudsql.googleapis.com/database/disk/utilization\""
comparison = "COMPARISON_GT"
threshold_value = 0.85
duration = "300s"
aggregations {
alignment_period = "60s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
notification_channels = [
google_monitoring_notification_channel.slack.name
]
}コスト最適化
コスト内訳の理解
| コスト項目 | 単価(東京リージョン) | 最適化ポイント |
|---|---|---|
| vCPU | $0.0526/時間 | 適切なサイジング |
| メモリ | $0.0089/GB/時間 | 不要なメモリ削減 |
| ストレージ(SSD) | $0.187/GB/月 | 不要データの削除 |
| バックアップ | $0.088/GB/月 | 保持期間の最適化 |
| ネットワーク | $0.12/GB(リージョン外) | レプリカの配置 |
コスト削減テクニック
1. 開発環境のスケジュール停止
# 開発インスタンスを夜間・休日に停止
# 停止
gcloud sql instances patch dev-instance \
--activation-policy=NEVER
# 起動
gcloud sql instances patch dev-instance \
--activation-policy=ALWAYS2. コミットメント利用割引(CUD)
1年または3年のコミットメントで最大52%の割引を受けられます。
| コミットメント期間 | 割引率 |
|---|---|
| なし | 0% |
| 1年 | 25% |
| 3年 | 52% |
3. ストレージの最適化
-- PostgreSQL: テーブルサイズの確認
SELECT
schemaname || '.' || tablename AS table_name,
pg_size_pretty(pg_total_relation_size(schemaname || '.' || tablename)) AS total_size,
pg_size_pretty(pg_relation_size(schemaname || '.' || tablename)) AS table_size,
pg_size_pretty(
pg_total_relation_size(schemaname || '.' || tablename) -
pg_relation_size(schemaname || '.' || tablename)
) AS index_size
FROM pg_tables
WHERE schemaname NOT IN ('pg_catalog', 'information_schema')
ORDER BY pg_total_relation_size(schemaname || '.' || tablename) DESC
LIMIT 20;
-- 不要データのアーカイブ
-- 1年以上前のデータをアーカイブテーブルに移動
INSERT INTO orders_archive
SELECT * FROM orders
WHERE created_at < NOW() - INTERVAL '1 year';
DELETE FROM orders
WHERE created_at < NOW() - INTERVAL '1 year';
-- テーブルの肥大化解消
VACUUM FULL orders;SES案件でのCloud SQLスキル活用
スキルシートに記載できる経験
| スキル | 具体例 | 単価インパクト |
|---|---|---|
| パフォーマンスチューニング | 「クエリ最適化でレスポンス10倍改善」 | +5-10万/月 |
| HA構成設計 | 「リージョナルHA + リードレプリカ構築」 | +10-15万/月 |
| コスト最適化 | 「DB費用を月額40%削減」 | +5-10万/月 |
| マイグレーション | 「オンプレMySQL → Cloud SQL移行」 | +10-15万/月 |
| 監視基盤構築 | 「Cloud Monitoring + アラート設定」 | +5万/月 |
Cloud SQLのキャリアパス
- 入門: Cloud SQLインスタンスの作成・基本運用
- 中級: パフォーマンスチューニング・HA構成
- 上級: 大規模データベースの設計・マイグレーション・コスト最適化
- エキスパート: マルチリージョン構成・災害復旧設計・セキュリティ強化
まとめ: Cloud SQL最適化で差をつける
Cloud SQLの最適化は、以下の4つの柱で体系的に取り組みましょう。
- パフォーマンスチューニング: インスタンスサイジング・クエリ最適化・接続管理で応答速度を改善
- 高可用性設計: リージョナルHA・リードレプリカ・バックアップ戦略で信頼性を確保
- 監視体制: Cloud Monitoring・Query Insightsで問題を早期検出
- コスト管理: 適切なサイジング・スケジュール停止・CUDで費用を最適化
データベースの最適化スキルはSES案件で非常に高く評価されます。特にCloud SQLのチューニング経験は、月額5-15万円の単価アップに直結するスキルです。





