
- Cloud Run GPUでサーバーレスのまま機械学習推論を実行しインフラ管理コストをゼロに
- NVIDIA L4/A100 GPUをコンテナに直接アタッチし推論レイテンシを最大10倍高速化
- オートスケーリングとゼロスケールでGPUコストを従来のGKE/GCE比で60-80%削減
機械学習モデルの推論(Inference)には、CPUでは処理が遅すぎるケースが多々あります。画像認識、自然言語処理、音声合成 — これらのワークロードにはGPUが不可欠です。しかし、従来のGPU利用はGKEやGCEでの専用インスタンス管理が必要で、運用コストが大きな課題でした。
Cloud Run GPUは、サーバーレスの手軽さとGPUの演算性能を両立する画期的なサービスです。インフラ管理不要で、リクエストがある時だけGPUが起動し、コストを最小化できます。
- Cloud Run GPUの基本概念と対応GPUタイプ
- GPU対応コンテナイメージの作成方法
- 推論サービスのデプロイと最適化
- コスト最適化のベストプラクティス
Cloud Run GPUとは
サーバーレス × GPU の実現
Cloud Run GPUは、2025年にGA(一般提供)となった機能で、Cloud RunのコンテナにNVIDIA GPUを直接アタッチできます。
従来のGPUワークロード運用との違いを整理します。
| 項目 | GCE/GKE | Cloud Run GPU |
|---|---|---|
| インフラ管理 | VM/ノード管理が必要 | 完全マネージド |
| スケーリング | 手動/HPA設定必要 | 自動(0→N) |
| ゼロスケール | 不可(最低1台稼働) | 可能(リクエスト時のみ起動) |
| コールドスタート | なし(常時起動) | あり(モデルロード時間) |
| 課金 | 常時課金 | リクエスト時のみ |
| セットアップ | CUDAドライバ設定等 | コンテナイメージのみ |
対応GPUタイプ
Cloud Run GPUで利用可能なGPUは以下の通りです。
| GPU | VRAM | 用途 | リージョン |
|---|---|---|---|
| NVIDIA L4 | 24GB | 推論全般、軽量トレーニング | us-central1, europe-west4, asia-northeast1 |
| NVIDIA A100 40GB | 40GB | 大規模モデル推論 | us-central1 |
| NVIDIA A100 80GB | 80GB | LLM推論、大規模バッチ | us-central1 |
東京リージョン(asia-northeast1)でもL4 GPUが利用可能なため、日本のSES案件でもレイテンシを抑えた推論サービスを構築できます。
GPU対応コンテナイメージの作成
Dockerfileの基本構成
GPU対応のコンテナイメージは、NVIDIAのCUDAベースイメージから作成します。
# NVIDIA CUDA ベースイメージ
FROM nvidia/cuda:12.4.1-runtime-ubuntu22.04
# Python環境のセットアップ
RUN apt-get update && apt-get install -y \
python3 python3-pip \
&& rm -rf /var/lib/apt/lists/*
# 依存関係のインストール
COPY requirements.txt .
RUN pip3 install --no-cache-dir -r requirements.txt
# アプリケーションコード
COPY app/ /app/
WORKDIR /app
# モデルファイル(ビルド時に含める場合)
COPY models/ /app/models/
# Cloud Run はPORT環境変数でポートを指定
ENV PORT=8080
EXPOSE 8080
CMD ["python3", "main.py"]requirements.txtの例
torch==2.3.0
transformers==4.45.0
accelerate==0.34.0
fastapi==0.115.0
uvicorn==0.32.0
pillow==10.4.0推論サービスの実装例(FastAPI)
import os
import torch
from fastapi import FastAPI, UploadFile
from transformers import pipeline
from PIL import Image
import io
app = FastAPI()
# GPU デバイスの検出
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
# モデルの読み込み(起動時に1回だけ実行)
classifier = None
@app.on_event("startup")
async def load_model():
global classifier
classifier = pipeline(
"image-classification",
model="google/vit-base-patch16-224",
device=device,
)
print("Model loaded successfully")
@app.post("/predict")
async def predict(file: UploadFile):
"""画像分類の推論エンドポイント"""
image = Image.open(io.BytesIO(await file.read()))
results = classifier(image)
return {
"predictions": [
{"label": r["label"], "score": round(r["score"], 4)}
for r in results[:5]
],
"device": device,
}
@app.get("/health")
async def health():
return {
"status": "healthy",
"gpu_available": torch.cuda.is_available(),
"gpu_name": torch.cuda.get_device_name(0) if torch.cuda.is_available() else None,
}
if __name__ == "__main__":
import uvicorn
port = int(os.environ.get("PORT", 8080))
uvicorn.run(app, host="0.0.0.0", port=port)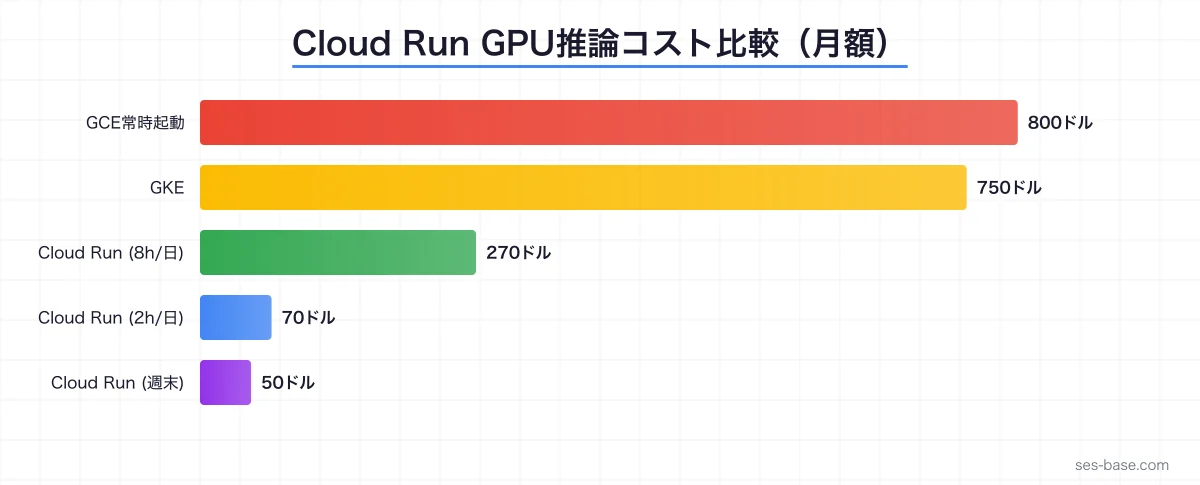
Cloud Run GPUへのデプロイ
gcloud CLIでのデプロイ
# コンテナイメージのビルドとプッシュ
gcloud builds submit --tag gcr.io/PROJECT_ID/ml-inference:latest
# Cloud Run GPUサービスのデプロイ
gcloud run deploy ml-inference \
--image gcr.io/PROJECT_ID/ml-inference:latest \
--region asia-northeast1 \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 8 \
--memory 32Gi \
--max-instances 5 \
--min-instances 0 \
--timeout 300 \
--concurrency 4 \
--no-cpu-throttling \
--execution-environment gen2 \
--allow-unauthenticated重要なデプロイオプション
| オプション | 推奨値 | 説明 |
|---|---|---|
| —gpu | 1 | GPU数(現在は1のみ) |
| —gpu-type | nvidia-l4 | GPUタイプ |
| —cpu | 4-8 | CPU数(GPUと合わせて設定) |
| —memory | 16-32Gi | メモリ(モデルサイズに応じて) |
| —concurrency | 1-4 | 同時リクエスト数 |
| —no-cpu-throttling | - | アイドル時もCPUを維持 |
| —min-instances | 0 | ゼロスケール有効 |
| —timeout | 300-900 | リクエストタイムアウト |
コールドスタート対策
GPU付きCloud Runの最大の課題はコールドスタートです。モデルのロードに30秒〜数分かかることがあります。
対策1: 最小インスタンス数の設定
gcloud run deploy ml-inference \
--min-instances 1 # 常に1インスタンスを維持対策2: モデルの軽量化
# 量子化によるモデルサイズ削減
from transformers import AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained(
"model-name",
torch_dtype=torch.float16, # FP16量子化
device_map="auto",
)対策3: Startup Probeの設定
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: ml-inference
spec:
template:
spec:
containers:
- image: gcr.io/PROJECT_ID/ml-inference:latest
startupProbe:
httpGet:
path: /health
initialDelaySeconds: 30
periodSeconds: 10
failureThreshold: 30ユースケース別の実装パターン
パターン1: LLM推論サービス
from vllm import LLM, SamplingParams
# vLLMで高速LLM推論
llm = LLM(
model="meta-llama/Llama-3.1-8B-Instruct",
dtype="float16",
gpu_memory_utilization=0.85,
)
@app.post("/generate")
async def generate(prompt: str, max_tokens: int = 256):
params = SamplingParams(
temperature=0.7,
max_tokens=max_tokens,
)
outputs = llm.generate([prompt], params)
return {"text": outputs[0].outputs[0].text}パターン2: 画像生成サービス
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
@app.post("/generate-image")
async def generate_image(prompt: str):
image = pipe(prompt, num_inference_steps=30).images[0]
buffer = io.BytesIO()
image.save(buffer, format="PNG")
return Response(
content=buffer.getvalue(),
media_type="image/png",
)パターン3: 音声認識サービス
import whisper
model = whisper.load_model("large-v3", device="cuda")
@app.post("/transcribe")
async def transcribe(file: UploadFile):
audio_data = await file.read()
with open("/tmp/audio.wav", "wb") as f:
f.write(audio_data)
result = model.transcribe("/tmp/audio.wav", language="ja")
return {
"text": result["text"],
"segments": result["segments"],
}コスト最適化
Cloud Run GPU vs GKE/GCEのコスト比較
利用パターン別のコスト比較です(東京リージョン、L4 GPU、月間推定)。
| 利用パターン | GCE(常時起動) | GKE | Cloud Run GPU |
|---|---|---|---|
| 1日8時間利用 | ~$800/月 | ~$750/月 | ~$270/月 |
| 1日2時間利用 | ~$800/月 | ~$750/月 | ~$70/月 |
| 週末のみ利用 | ~$800/月 | ~$750/月 | ~$50/月 |
| スパイク型 | ~$800/月 | ~$600/月 | ~$150/月 |
利用時間が短いほどCloud Run GPUのコスト優位性が顕著になります。
コスト最適化のテクニック
1. ゼロスケールの活用
# 最小インスタンス0でコスト最小化
gcloud run deploy --min-instances 02. 適切なGPUタイプの選択
- 推論のみ → L4(コスパ最良)
- 大規模モデル → A100 40GB
- LLM(70B+)→ A100 80GB
3. バッチ処理の活用
@app.post("/batch-predict")
async def batch_predict(images: list[UploadFile]):
"""複数画像をバッチ処理でまとめて推論"""
batch = [Image.open(io.BytesIO(await img.read())) for img in images]
results = classifier(batch, batch_size=len(batch))
return {"results": results}4. モデルキャッシュの利用
# Artifact Registryにモデルを含めたイメージをキャッシュ
FROM nvidia/cuda:12.4.1-runtime-ubuntu22.04
# モデルをイメージに含める(起動時ダウンロード不要)
COPY --from=model-builder /models /app/modelsTerraformでのインフラ管理
resource "google_cloud_run_v2_service" "ml_inference" {
name = "ml-inference"
location = "asia-northeast1"
template {
containers {
image = "gcr.io/${var.project_id}/ml-inference:latest"
resources {
limits = {
cpu = "8"
memory = "32Gi"
"nvidia.com/gpu" = "1"
}
}
startup_probe {
http_get {
path = "/health"
}
initial_delay_seconds = 30
period_seconds = 10
failure_threshold = 30
}
}
scaling {
min_instance_count = 0
max_instance_count = 5
}
node_selector {
accelerator = "nvidia-l4"
}
vpc_access {
connector = google_vpc_access_connector.connector.id
}
}
}Cloud Runの基礎知識はこちらで確認できます。
Cloud Run Jobsによるバッチ処理ガイドも参考にしてください。
Google Cloud IAMセキュリティでアクセス制御を確認できます。
SES案件でのCloud Run GPU活用
GPU関連SES案件の動向
SES市場でGPU関連の案件は急増しており、以下の分野で需要があります。
- 生成AI導入: LLM/画像生成AIのAPI化とサービス構築
- 医療画像解析: CT/MRIの画像分類・異常検知
- 製造業品質検査: 画像ベースの外観検査自動化
- 音声AI: リアルタイム文字起こし・音声合成サービス
- レコメンデーション: GPU推論による高速パーソナライゼーション
求められるスキルセット
Cloud Run GPU案件で求められる技術スキルは以下の通りです。
- コンテナ技術: Docker、Artifact Registry
- ML基礎: PyTorch/TensorFlowでの推論パイプライン
- GCP基礎: Cloud Run、Cloud Build、IAM
- 最適化: モデル量子化、バッチ処理、キャッシュ戦略
- IaC: Terraform/Pulumiでのインフラ管理
まとめ — Cloud Run GPUでML推論をサーバーレスに
Cloud Run GPUは、サーバーレスの手軽さとGPUの演算性能を両立する画期的なサービスです。インフラ管理の負担なしにGPUワークロードを運用でき、ゼロスケールでコストも最小化できます。
本記事のポイントをまとめます。
- ✅ Cloud Run GPUでサーバーレスのまま機械学習推論を実行可能
- ✅ NVIDIA L4 GPUが東京リージョンで利用可能、低レイテンシを実現
- ✅ ゼロスケール対応で利用時間に応じた従量課金、コスト60-80%削減
- ✅ LLM推論・画像生成・音声認識など多様なユースケースに対応
- ✅ Terraformでインフラ管理をコード化し再現性を確保
まずは既存のML推論パイプラインをCloud Run GPUに移行し、コスト削減と運用効率化の効果を体感してみてください。
Google Cloud完全攻略シリーズをもっと読む
Google Cloudの活用テクニックをさらに深く学びたい方は、完全攻略シリーズの他のエピソードもチェックしてください。
シリーズ一覧を見る →




