
- BigQueryはペタバイト規模のデータをサーバーレスで分析できるGCPの主力サービス
- SQLだけで即座に大規模データ分析が可能——SESエンジニアの市場価値向上に直結
- コスト管理・パーティショニング・マテリアライズドビューなど本番運用のベストプラクティスを網羅
- Google Cloud 完全攻略 Ep.1: GCPの基礎知識とプロジェクト作成
- Google Cloud 完全攻略 Ep.2: Cloud RunとCloud SQLで実現するスケーラブルなコンテナ運用
- Google Cloud 完全攻略 Ep.3: BigQueryではじめるデータ分析入門(本記事)
- Google Cloud 完全攻略 Ep.4: Cloud Functionsで学ぶサーバーレスアーキテクチャ入門
- Google Cloud 完全攻略 Ep.5: Cloud Storageで学ぶオブジェクトストレージ運用入門
- Google Cloud 完全攻略 Ep.6: IAMとセキュリティ設計で学ぶクラウド権限管理
SES案件の現場でも、データ分析・データエンジニアリング関連の需要が急速に高まっています。その中核を担うのが、Google CloudのBigQueryです。
BigQueryは、Googleが提供するフルマネージドのサーバーレスデータウェアハウスで、ペタバイト規模のデータに対してSQLクエリを数秒で実行できます。インフラの管理やチューニングが不要で、データ分析に集中できるのが最大の魅力です。
本記事では、BigQueryの基本概念から、実際のSQLクエリ例、そして本番運用のコスト最適化テクニックまでを体系的に解説します。
BigQueryとは?——なぜ今、SESエンジニアに必要なのか
BigQueryは、2010年にGoogleが公開したカラム型ストレージを基盤としたデータウェアハウスサービスです。従来のRDBMSとは異なるアーキテクチャにより、テラバイト〜ペタバイトのデータでも高速な分析クエリを実行できます。
SES案件における需要の高まり
データ分析基盤の構築案件は、2025年以降さらに増加しています。特にBigQueryは以下の理由から、多くのプロジェクトで採用されています。
- サーバーレス: インフラの構築・管理が不要。クラスタのサイジングやスケーリングを考える必要がない
- 標準SQL対応: 特殊な言語を覚える必要がなく、SQLの知識がそのまま活かせる
- 従量課金: クエリでスキャンしたデータ量に応じた課金。無駄なコストが発生しにくい
- エコシステムの充実: Looker、Dataflow、Vertex AIなどGCPの他サービスとシームレスに連携
SES案件で求められるクラウドスキルとしても、BigQueryの実務経験は大きなアピールポイントになります。
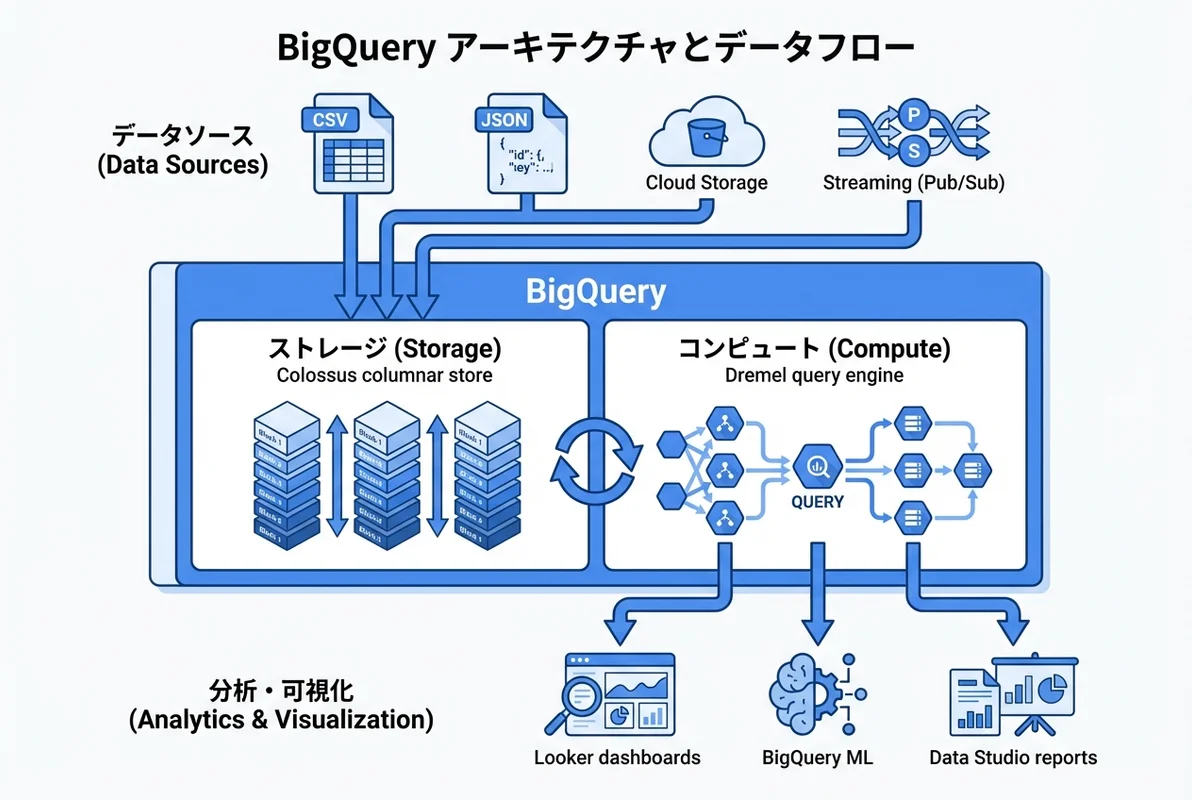
BigQueryの基本的な使い方
データセットとテーブルの作成
BigQueryでは、プロジェクト > データセット > テーブルという階層構造でデータを管理します。まずはデータセットを作成しましょう。
# データセットの作成(東京リージョン)
bq mk --dataset \
--location=asia-northeast1 \
--description="売上分析用データセット" \
my_project:sales_analytics続いて、スキーマを定義してテーブルを作成します。
# テーブル作成
bq mk --table \
sales_analytics.daily_sales \
order_id:STRING,product_name:STRING,amount:INTEGER,order_date:DATE,region:STRING基本的なクエリの実行
BigQueryのコンソールまたはbqコマンドラインツールからSQLクエリを実行できます。
-- 月別の売上集計
SELECT
FORMAT_DATE('%Y-%m', order_date) AS month,
region,
COUNT(*) AS order_count,
SUM(amount) AS total_sales,
AVG(amount) AS avg_order_value
FROM `my_project.sales_analytics.daily_sales`
WHERE order_date BETWEEN '2026-01-01' AND '2026-03-01'
GROUP BY month, region
ORDER BY month DESC, total_sales DESC;このように、標準的なSQLで即座にデータ分析を開始できます。MySQLやPostgreSQLの経験があるエンジニアなら、すぐに活用できるでしょう。
外部データの取り込み
BigQueryはCSV、JSON、Parquet、Avroなど多様なフォーマットのデータをインポートできます。
# CSVファイルのロード
bq load \
--source_format=CSV \
--skip_leading_rows=1 \
--autodetect \
sales_analytics.daily_sales \
gs://my-bucket/sales_data_2026.csvCloud Storageに配置したファイルを直接参照する外部テーブルも作成可能で、ETLパイプラインを柔軟に設計できます。
実践的なデータ分析テクニック
ウィンドウ関数で高度な分析を実現
BigQueryではウィンドウ関数が充実しており、累積合計やランキングなどの分析が簡単に行えます。
-- 地域別の売上ランキングと累積売上
SELECT
region,
product_name,
SUM(amount) AS product_sales,
RANK() OVER (PARTITION BY region ORDER BY SUM(amount) DESC) AS sales_rank,
SUM(SUM(amount)) OVER (PARTITION BY region ORDER BY SUM(amount) DESC) AS cumulative_sales
FROM `my_project.sales_analytics.daily_sales`
GROUP BY region, product_name
ORDER BY region, sales_rank;UNNEST で配列データを展開
BigQueryはネスト・リピーテッドフィールド(STRUCT型やARRAY型)をネイティブサポートしています。JSON的なデータ構造を非正規化して格納し、高速にクエリできるのがBigQueryならではの強みです。
-- タグ(配列)をフラット化して集計
SELECT
tag,
COUNT(*) AS article_count
FROM `my_project.blog_analytics.articles`,
UNNEST(tags) AS tag
GROUP BY tag
ORDER BY article_count DESC
LIMIT 20;スケジュールドクエリで定期レポートを自動化
BigQueryにはスケジュールドクエリ機能が組み込まれており、定期的な集計処理をSQLだけで自動化できます。GUIから設定可能で、結果を別テーブルに書き出せます。
コスト最適化のベストプラクティス
BigQueryは強力なサービスですが、使い方によってはコストが膨らむ可能性があります。以下のテクニックを押さえましょう。
パーティショニングとクラスタリング
テーブルにパーティションを設定することで、クエリ時にスキャンするデータ量を大幅に削減できます。
-- 日付パーティションテーブルの作成
CREATE TABLE `my_project.sales_analytics.daily_sales_partitioned`
PARTITION BY order_date
CLUSTER BY region, product_name
AS
SELECT * FROM `my_project.sales_analytics.daily_sales`;- パーティション: 日付カラムで分割し、特定期間のみスキャン
- クラスタリング: 指定カラムでデータをソートし、関連データのスキャン効率を向上
この2つを組み合わせるだけで、クエリコストを50〜90%削減できるケースも珍しくありません。
オンデマンド vs 定額料金(Editions)
BigQueryには2つの課金モデルがあります。
| 課金モデル | 特徴 | 適したケース |
|---|---|---|
| オンデマンド | スキャンしたデータ量(TB)に応じて課金 | 分析頻度が不定期・少量 |
| Editions(定額) | 確保したスロット(計算リソース)に応じて課金 | 大量・定常的なクエリ実行 |
SES案件では、プロジェクト初期はオンデマンドで始め、利用量が安定してきたらEditionsへの移行を検討するのが一般的です。
ドライランで事前にコスト確認
クエリの実行前に、どれだけのデータがスキャンされるかを確認できるドライラン機能を活用しましょう。
# ドライランでスキャン量を事前チェック
bq query --dry_run \
'SELECT * FROM `my_project.sales_analytics.daily_sales` WHERE order_date > "2026-01-01"'これにより「思わぬ高額請求」を未然に防げます。GCPの基礎知識で解説した課金アラートと併用するのが効果的です。
BigQuery ML——SQLだけで機械学習
BigQueryの特筆すべき機能として**BigQuery ML(BQML)**があります。SQLステートメントだけで機械学習モデルの作成・トレーニング・予測が可能です。
-- 線形回帰モデルの作成
CREATE OR REPLACE MODEL `my_project.sales_analytics.sales_forecast`
OPTIONS(model_type='LINEAR_REG', input_label_cols=['total_sales']) AS
SELECT
EXTRACT(MONTH FROM order_date) AS month,
EXTRACT(DAYOFWEEK FROM order_date) AS day_of_week,
region,
SUM(amount) AS total_sales
FROM `my_project.sales_analytics.daily_sales`
GROUP BY order_date, region;PythonやRの環境構築が不要で、SQLに慣れたSESエンジニアでもすぐに機械学習を活用できるのは大きなメリットです。AIエンジニアの案件動向でも触れているように、ML経験は案件単価の向上に直結します。
まとめ——BigQueryスキルでSES案件の幅を広げよう
BigQueryは、SESエンジニアにとって習得価値の高いサービスです。
- 学習コストの低さ: SQLが書ければすぐに使える
- 案件の幅が広がる: データ分析基盤・BI・ML案件に参画可能
- 実務で即戦力: サーバーレスのため、インフラ構築の知識がなくても分析に集中できる
まずはGCPの基礎(Ep.1)でプロジェクトを作成し、BigQueryのサンドボックス(無料枠)で実際にクエリを試してみてください。Ep.2のCloud Run + Cloud SQLで構築したアプリケーションのログをBigQueryに流し込んで分析する、というのも実践的な学習方法です。
次回のGoogle Cloud 完全攻略では、CI/CDパイプラインの構築について解説予定です。お楽しみに!
出典・参考資料
関連記事





