
📚 この記事は「Google Cloud 完全攻略シリーズ」の Episode 18 です。
- AlloyDBはPostgreSQL互換でありながらトランザクション性能が最大4倍、分析クエリが最大100倍高速
- AIネイティブ機能(pgvector統合)でベクトル検索・RAG基盤を簡単に構築可能
- PostgreSQL経験があればAlloyDBへの移行は容易で、SES単価+5〜15万円が見込める
「PostgreSQLの性能限界に達しているが、NoSQLへの移行は避けたい」「RDBでベクトル検索やAI機能を使いたい」「Cloud SQLよりも高性能なマネージドDBが必要」——SES案件でデータベース設計・運用を担当するエンジニアなら、こうした要件に直面したことがあるのではないでしょうか。
Google Cloud AlloyDBは、PostgreSQLとの完全互換性を保ちながら、Googleのストレージ技術を活用して標準PostgreSQLの最大4倍のトランザクション性能を実現するマネージドデータベースです。
本記事では、Google Cloudの基礎知識を前提に、AlloyDBの設計・運用・活用法をSESエンジニア向けに実践的に解説します。
AlloyDBとは?Cloud SQLとの違い
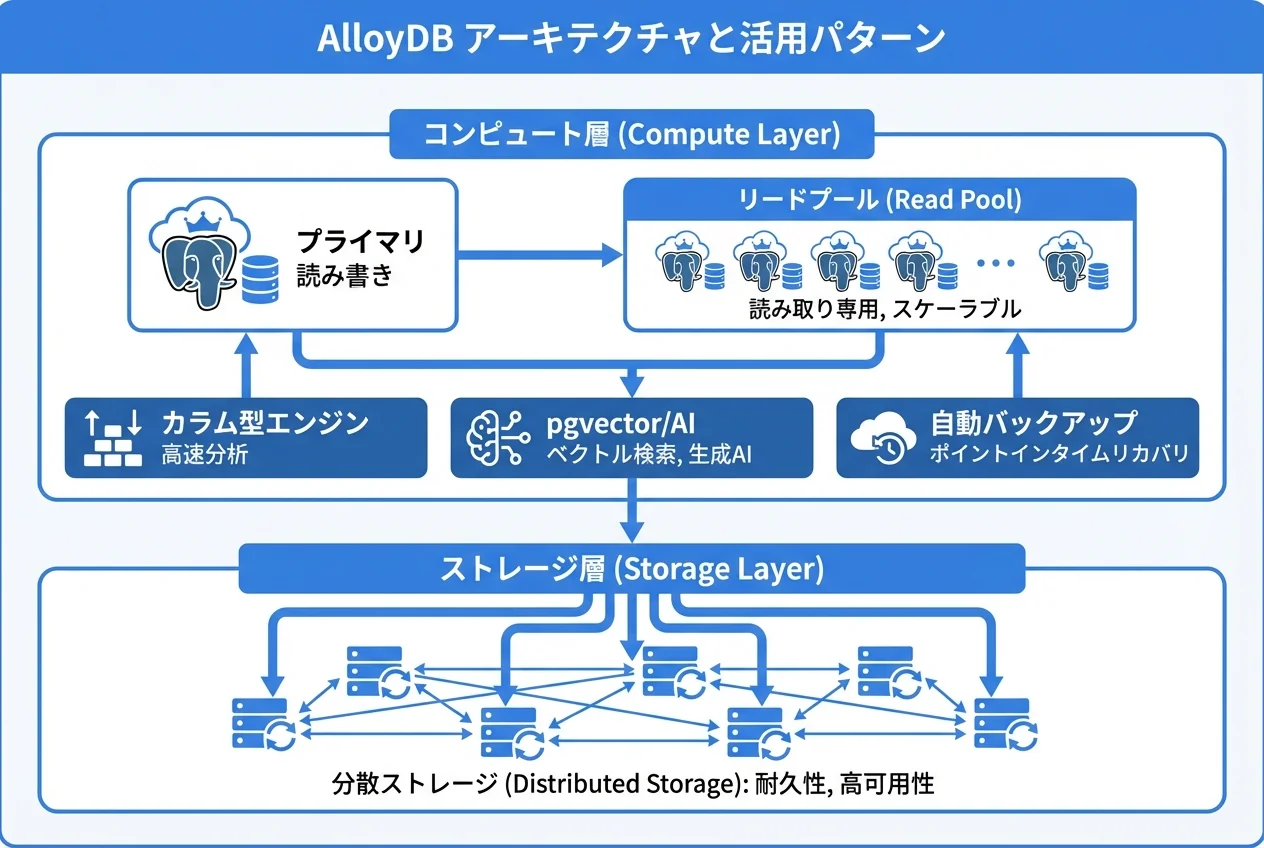
AlloyDBのアーキテクチャ
AlloyDBは、コンピューティング(クエリ処理)とストレージ(データ保存)を分離したディスアグリゲーテッド・アーキテクチャを採用しています。
[コンピュート層]
├── プライマリインスタンス(書き込み + 読み取り)
└── リードプールインスタンス × N(読み取り専用・自動スケール)
[ストレージ層(Google管理)]
├── 超低レイテンシ分散ストレージ
├── 自動レプリケーション(3重化)
└── 自動スナップショット・PITRCloud SQL vs AlloyDB 詳細比較
| 項目 | Cloud SQL for PostgreSQL | AlloyDB |
|---|---|---|
| PostgreSQL互換性 | 完全互換 | 完全互換 |
| トランザクション性能 | 標準PostgreSQL同等 | 最大4倍高速 |
| 分析クエリ性能 | 標準PostgreSQL同等 | 最大100倍高速(カラム型エンジン) |
| ストレージ | インスタンスにアタッチ | 分離型(自動拡張) |
| リードレプリカ | 最大10台 | リードプールで自動スケール |
| フェイルオーバー | 60秒以下 | 60秒以下 |
| ベクトル検索 | pgvector拡張で可能 | ネイティブ最適化済み |
| 月額コスト(最小) | 約$50〜 | 約$200〜 |
| 適性 | 小〜中規模 | 中〜大規模、高性能要件 |
AlloyDBが適するユースケース
- 高トランザクション負荷: ECサイト・金融系のOLTP処理
- 分析クエリの混在: OLTPとOLAP(分析)を同一DBで処理(HTAP)
- AI/MLワークロード: ベクトル検索、RAG(検索拡張生成)基盤
- PostgreSQLからの移行: 既存PostgreSQLの性能不足解消
AlloyDBクラスタの構築
gcloud CLIでのクラスタ作成
# AlloyDBクラスタの作成
gcloud alloydb clusters create my-cluster \
--region=asia-northeast1 \
--network=default \
--password=CHANGE_ME \
--automated-backup-enabled \
--backup-window=02:00
# プライマリインスタンスの作成
gcloud alloydb instances create primary \
--cluster=my-cluster \
--region=asia-northeast1 \
--instance-type=PRIMARY \
--cpu-count=4 \
--machine-type=c4a \
--database-flags=\
max_connections=200,\
shared_buffers=1GB,\
work_mem=64MB
# リードプールの作成
gcloud alloydb instances create read-pool \
--cluster=my-cluster \
--region=asia-northeast1 \
--instance-type=READ_POOL \
--read-pool-node-count=2 \
--cpu-count=4Terraformでの構築
resource "google_alloydb_cluster" "main" {
cluster_id = "my-cluster"
location = "asia-northeast1"
network = google_compute_network.default.id
initial_user {
user = "admin"
password = var.db_password
}
automated_backup_policy {
location = "asia-northeast1"
backup_window = "02:00"
enabled = true
weekly_schedule {
days_of_week = ["MONDAY", "WEDNESDAY", "FRIDAY"]
start_times {
hours = 2
minutes = 0
}
}
quantity_based_retention {
count = 7
}
}
continuous_backup_config {
enabled = true
recovery_window_days = 14
}
}
resource "google_alloydb_instance" "primary" {
cluster = google_alloydb_cluster.main.name
instance_id = "primary"
instance_type = "PRIMARY"
machine_config {
cpu_count = 4
}
database_flags = {
"max_connections" = "200"
"shared_buffers" = "1073741824"
}
}
resource "google_alloydb_instance" "read_pool" {
cluster = google_alloydb_cluster.main.name
instance_id = "read-pool"
instance_type = "READ_POOL"
read_pool_config {
node_count = 2
}
machine_config {
cpu_count = 4
}
}パフォーマンスチューニング
カラム型エンジンの活用
AlloyDB最大の差別化要因が**カラム型エンジン(Columnar Engine)**です。分析クエリを最大100倍高速化できます:
-- カラム型エンジンの有効化
ALTER SYSTEM SET google_columnar_engine.enabled = 'on';
SELECT pg_reload_conf();
-- 自動カラム化の対象テーブル確認
SELECT * FROM google_columnar_engine.recommended_columns;
-- 手動でカラム化する場合
SELECT google_columnar_engine.alter_column('orders', 'created_at', is_columnar => true);
SELECT google_columnar_engine.alter_column('orders', 'total_amount', is_columnar => true);
SELECT google_columnar_engine.alter_column('orders', 'status', is_columnar => true);カラム型エンジンが効果的なクエリ例:
-- 月次売上集計(カラム型エンジンで最大100倍高速化)
SELECT
DATE_TRUNC('month', created_at) AS month,
COUNT(*) AS order_count,
SUM(total_amount) AS total_revenue,
AVG(total_amount) AS avg_order_value
FROM orders
WHERE created_at >= '2026-01-01'
GROUP BY DATE_TRUNC('month', created_at)
ORDER BY month;クエリ最適化
-- AlloyDB Query Insights でスロークエリを特定
SELECT
query,
calls,
mean_exec_time,
total_exec_time,
rows
FROM pg_stat_statements
ORDER BY mean_exec_time DESC
LIMIT 20;
-- 実行計画の確認(AlloyDB固有の最適化を確認)
EXPLAIN (ANALYZE, BUFFERS, FORMAT JSON)
SELECT p.name, COUNT(o.id), SUM(o.quantity * p.price)
FROM products p
JOIN order_items oi ON oi.product_id = p.id
JOIN orders o ON o.id = oi.order_id
WHERE o.created_at >= '2026-01-01'
GROUP BY p.name
ORDER BY SUM(o.quantity * p.price) DESC;接続管理のベストプラクティス
AlloyDBへの接続管理は、パフォーマンスに大きく影響します:
アプリケーション → AlloyDB Auth Proxy → AlloyDBインスタンス
(IAM認証 + SSL)
推奨設定:
- コネクションプール: PgBouncer or アプリ内プール
- 最大接続数: vCPU × 50 を目安
- アイドルタイムアウト: 300秒
- リードレプリカの自動ルーティングAIネイティブ機能(ベクトル検索)
pgvectorとAlloyDBの統合
AlloyDBはpgvector拡張を最適化済みで、ベクトル検索のパフォーマンスが標準PostgreSQLの10倍以上高速です:
-- pgvector拡張の有効化
CREATE EXTENSION IF NOT EXISTS vector;
-- ベクトルカラムを持つテーブルの作成
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
content TEXT NOT NULL,
embedding vector(768), -- Vertex AI Embeddingsの次元数
created_at TIMESTAMPTZ DEFAULT NOW()
);
-- ScaNN インデックスの作成(AlloyDB最適化済み)
CREATE INDEX ON documents
USING scann (embedding cosine)
WITH (num_leaves = 100, quantizer = 'sq8');Vertex AI連携でRAG基盤を構築
AlloyDBからVertex AIのEmbedding APIを直接呼び出せます:
-- Vertex AIとの連携設定
SELECT google_ml.create_model(
model_id => 'text-embedding',
model_request_url => 'https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT/locations/us-central1/publishers/google/models/text-embedding-005:predict',
model_provider => 'google',
model_type => 'text_embedding'
);
-- テキストからベクトルを生成してupsert
UPDATE documents
SET embedding = google_ml.embedding(
model_id => 'text-embedding',
content => content
)::vector
WHERE embedding IS NULL;
-- セマンティック検索
SELECT title, content,
1 - (embedding <=> google_ml.embedding(
model_id => 'text-embedding',
content => '検索クエリテキスト'
)::vector) AS similarity
FROM documents
ORDER BY embedding <=> google_ml.embedding(
model_id => 'text-embedding',
content => '検索クエリテキスト'
)::vector
LIMIT 10;バックアップと災害復旧
バックアップ戦略
| バックアップ種別 | RPO | 復旧時間 | コスト |
|---|---|---|---|
| 自動バックアップ(日次) | 24時間 | 数分 | 低 |
| 連続バックアップ(PITR) | 秒単位 | 数分 | 中 |
| クロスリージョンレプリカ | ほぼゼロ | 数分 | 高 |
# ポイントインタイムリカバリ
gcloud alloydb clusters restore my-cluster-restored \
--source-cluster=my-cluster \
--region=asia-northeast1 \
--network=default \
--point-in-time=2026-03-16T15:30:00Zコスト最適化
インスタンスサイズの最適化
AlloyDBはvCPU単位の課金なので、ワークロードに合ったサイズ選定が重要です:
| ワークロード | 推奨vCPU | 推奨メモリ | 月額概算 |
|---|---|---|---|
| 開発/ステージング | 2 vCPU | 16 GB | $200〜 |
| 小規模本番 | 4 vCPU | 32 GB | $400〜 |
| 中規模本番 | 8 vCPU | 64 GB | $800〜 |
| 大規模本番 | 16+ vCPU | 128+ GB | $1,600〜 |
コスト削減テクニック
- リードプールの自動スケール: ピーク時はノードを増やし、オフピークは削減
- 確約利用割引: 1年/3年契約で最大60%削減
- 開発環境の停止: 非営業時間は開発クラスタを停止
- カラム型エンジン: 分析用の別インスタンスが不要に(コスト統合効果)
SES現場でのAlloyDB案件
求められるスキルと単価相場
AlloyDBはPostgreSQL互換なので、PostgreSQL経験があれば参入障壁は低いのが大きなメリットです:
| スキル | 単価への影響 | 備考 |
|---|---|---|
| PostgreSQL運用 | ベース | 必須前提スキル |
| AlloyDB固有機能 | +5〜10万円 | カラム型エンジン、Auth Proxy |
| ベクトル検索/AI | +10〜15万円 | pgvector、Vertex AI連携 |
| パフォーマンスチューニング | +5〜10万円 | Query Insights活用 |
PostgreSQLからAlloyDBへの移行案件
既存のPostgreSQL環境からAlloyDBへの移行案件が増加しています。移行の主なステップ:
- 互換性チェック: 使用中のPostgreSQL拡張がAlloyDBでサポートされているか確認
- Database Migration Service(DMS): Googleのマネージド移行ツールで無停止移行
- パフォーマンステスト: 移行後のクエリ性能を比較検証
- 接続先切り替え: AlloyDB Auth Proxyの設定と接続文字列の変更
まとめ:AlloyDBでデータベーススキルの次のステップへ
Google Cloud AlloyDBは、PostgreSQL互換性と独自の高性能アーキテクチャを両立した次世代データベースサービスです。
AlloyDBの3つのポイント:
- 高性能: カラム型エンジンで分析クエリが最大100倍高速化、OLTPも4倍
- AIネイティブ: pgvector最適化とVertex AI連携で、DB上でAI機能を直接実行
- PostgreSQL互換: 既存のスキル・ツール・アプリケーションをそのまま活用可能
PostgreSQLスキルをすでに持つSESエンジニアにとって、AlloyDBはキャリアアップの自然な延長線です。AI機能との組み合わせで、データベースエンジニアとしての市場価値を大きく高めましょう。
関連記事
- Google Cloud入門ガイド - Google Cloudの基礎
- Cloud SQL最適化ガイド - Cloud SQLの運用テクニック
- Cloud Spanner グローバルDB設計ガイド - 分散DBの実践
- Vertex AI ML入門ガイド - AI/MLプラットフォーム





