
「ブラウザの操作も、その結果を使ったコード生成も、全部AIにやらせたい」——その要望に応えるのが、AntigravityとProject Marinerの連携です。
Google AntigravityのコーディングエージェントとProject MarinerのWebブラウジングエージェントを組み合わせることで、Web上のデータ収集からコード生成まで一気通貫で自動化できます。この記事では、Google Antigravity 完全攻略シリーズ第38弾として、この2つのエージェントを連携させた実践ワークフローを解説します。
この記事を3秒でまとめると
- Project MarinerはGoogleのWebブラウジングエージェントで、Webページの閲覧・操作を自動化
- AntigravityのコーディングエージェントとMarinerを連携させるとデータ収集→コード生成が一貫で完了
- Gemini APIを介した統合パターンとVertex AIでの本番構築を実例で紹介
Project Marinerとは?Antigravityとの関係
Webブラウジングエージェントの概要
Project Marinerは、Googleが2025年末にリリースしたWebブラウジング特化のAIエージェントです。Chromeブラウザ上で動作し、以下の操作を自然言語の指示で自動実行できます。
- Webページの閲覧・スクロール・クリック
- フォームへの入力・送信
- 複数タブを跨いだ情報収集
- スクリーンショットの取得と分析
- 構造化データの抽出
Google公式ブログによれば、MarinerはGemini 2.5のマルチモーダル能力を基盤としており、視覚的な情報とテキストの両方を理解してWeb操作を行います(出典: Google DeepMind Blog - Project Mariner)。
Antigravityのエージェント機能との違い
AntigravityとMarinerは、それぞれ異なる領域に特化したエージェントです。
| 比較項目 | Antigravity | Project Mariner |
|---|---|---|
| 主な領域 | コード生成・ファイル操作 | Webブラウジング・データ取得 |
| 実行環境 | ターミナル / IDE | Chrome ブラウザ |
| 入力形式 | 自然言語 → コード | 自然言語 → Web操作 |
| 出力形式 | コード・ファイル | データ・スクリーンショット |
| 強み | コードベース理解・編集 | 動的ページの操作 |
この2つを連携させることで、**Webからのデータ取得(Mariner)→ データを使った開発(Antigravity)**というワークフローが実現します。
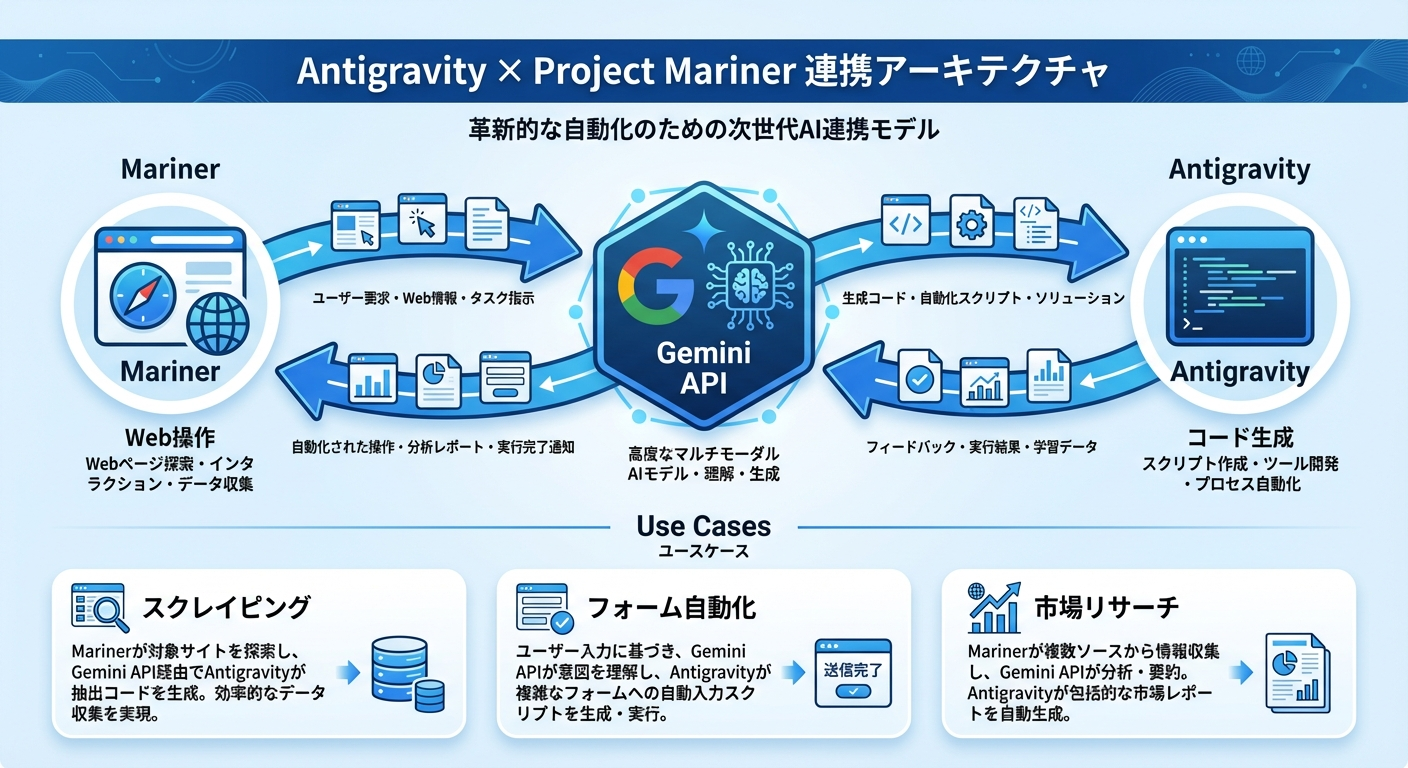
Project Mariner × Antigravity連携のアーキテクチャ
Gemini APIを介した統合パターン
MarinerとAntigravityの連携は、Gemini APIを中心とした以下のアーキテクチャで実現できます。
基本的なフロー:
- Antigravityがタスクを分析し、Web情報の取得が必要と判断
- Gemini API経由でMarinerにWeb操作を指示
- Marinerがブラウザ上でデータを取得・構造化
- 取得データがAntigravityに戻り、コード生成に活用
# 連携のイメージコード
from google.generativeai import mariner, antigravity
# Step 1: MarinerでWebデータ取得
web_data = mariner.browse(
instruction="AWS Kinesisの料金ページから、東京リージョンの料金表を抽出して",
output_format="json"
)
# Step 2: Antigravityでコード生成
antigravity.generate(
instruction=f"以下の料金データを使って、コスト計算クラスを作成して: {web_data}",
output_dir="./src/pricing/"
)Vertex AIでの本番環境構築
本番環境では、Vertex AIのAgent Builder上にMarinerとAntigravityを配置し、オーケストレーション層で連携させます。
構成要素:
- Vertex AI Agent Builder: エージェントのホスティングと管理
- Cloud Run: カスタムロジックの実行環境
- Cloud Storage: 取得データの一時保存
- Cloud Monitoring: エージェント実行の監視
Antigravity API連携ガイドでも、APIの基本的な使い方を解説しています。
Web操作自動化の実践例
Webスクレイピング+コード自動生成
ユースケース: 競合サービスの料金比較ツール作成
1. Mariner: 3つのクラウドサービスの料金ページを巡回し、料金データを構造化JSONで取得
2. Antigravity: 取得した料金データを使って、比較表コンポーネントをReactで生成
3. Antigravity: E2Eテストも自動生成この一連のフローを自然言語で指示するだけで、手作業なら半日かかるタスクを30分で完了できます。
フォーム入力・データ収集の自動化
ユースケース: 行政サービスのデータ収集
Marinerは動的に生成されるフォーム(JavaScript描画のドロップダウン等)にも対応できるため、従来のスクレイピングツール(BeautifulSoup、Scrapy)では困難だった以下の操作が可能です。
- ログインが必要なページへのアクセス
- Ajax通信で動的に読み込まれるコンテンツの取得
- CAPTCHAやreCAPTCHAへの対応(Googleアカウント連携時)
- 複数ステップのフォームウィザードの自動操作
競合調査・市場リサーチの自動化
ユースケース: SES案件の市場調査レポート自動生成
1. Mariner: 求人サイト5つを巡回し、特定スキルの案件単価を100件分収集
2. Antigravity: 収集データを分析し、Pythonで統計レポート(平均・中央値・分布)を生成
3. Antigravity: Chart.jsを使ったビジュアルレポートのHTMLを自動生成エージェント間のタスクハンドオフ設計
MarinerからAntigravityへのデータ受け渡し
効率的なデータ受け渡しのパターンは3つあります。
- インメモリ(小規模データ): JSON/テキストを直接渡す
- ファイル経由(中規模データ): Cloud Storageにファイルを保存し、パスを渡す
- データベース経由(大規模データ): BigQueryやFirestoreに格納し、クエリで取得
マルチエージェント開発ガイドでも、エージェント間通信のパターンを解説しています。
エラーハンドリングとフォールバック
Web操作は不安定になりがちです。以下のエラーハンドリングを組み込みましょう。
- リトライ機構: ネットワークエラー時は最大3回リトライ
- タイムアウト設定: ページ読み込みに30秒以上かかる場合はスキップ
- 代替データソース: 主要ソースが利用不可の場合のフォールバック先を設定
- 部分成功の処理: 5ページ中3ページ成功した場合でも、取得できたデータで処理を続行
セキュリティとプライバシーの注意点
Web操作時の認証情報管理
Marinerにログイン操作を委任する場合、認証情報の管理に細心の注意が必要です。
- OAuth連携を優先: パスワード直接入力より、Googleアカウント連携やOAuth2.0を使用
- Secret Managerで管理: API KeyやパスワードはGoogle Secret Managerに保存
- 最小権限の原則: Marinerに与えるブラウザ権限を必要最小限にする
- セッション管理: 操作完了後にブラウザセッションを確実にクリア
データ取得のコンプライアンス
Web上のデータを自動収集する際のコンプライアンス注意点:
- robots.txtの遵守: スクレイピング対象サイトのrobots.txtを確認
- 利用規約の確認: サイトの利用規約で自動アクセスが禁止されていないか確認
- 個人情報の取り扱い: 収集データに個人情報が含まれる場合の処理ルール策定
- アクセス頻度の制御: DoS攻撃にならないよう、リクエスト間隔を適切に設定
エンタープライズセキュリティガイドでも、セキュリティのベストプラクティスを解説しています。
まとめ:ブラウザ×コードのマルチエージェント開発
AntigravityとProject Marinerの連携は、Web上の情報活用を劇的に効率化する次世代の開発アプローチです。
始めるためのステップ:
- Project Marinerのベータアクセスを申請する
- 小さなタスク(1サイトのデータ取得→コード生成)で試す
- エラーハンドリングを組み込んで本番品質にする
- Vertex AIで本番環境を構築する
**「Webを見て、理解して、コードにする」——この人間の作業フローをAIが再現する時代が来ています。**早めにこの連携パターンを習得し、開発の自動化レベルを一段引き上げましょう。
SES BASEでは、AI・自動化スキルが活かせるSES案件を多数掲載しています。案件を検索するからチェックしてみてください。





