
- Gemini CLIはSentry・Datadog・CloudWatch等の監視ツールと連携し、アラートルール生成からインシデント分析までを自動化する
- エラーログのパターン分析により、アラート疲れの原因を特定し、最適なしきい値・グルーピングを提案してくれる
- インシデント発生時のランブック(対応手順書)自動生成やSlack通知テンプレートの作成も可能
「本番環境のエラーアラートが多すぎて、本当に重要なものを見落としてしまった…」 「Sentryのエラーグルーピングが適切じゃなくて、同じエラーが別々にカウントされている…」
エラー監視は本番運用の生命線ですが、適切な監視設計がなければアラート疲れや見落としが発生します。Gemini CLIを活用すれば、監視ルールの設計からインシデント対応の自動化まで、エラー監視のライフサイクル全体を効率化できます。
この記事では、Gemini CLIを使ったエラー監視・アラート自動化の実践テクニックを、主要監視ツールとの連携パターンとともに解説します。
- Gemini CLIでSentry・Datadog・CloudWatchの監視ルールを効率的に設計する方法
- アラート疲れを防ぐための最適なしきい値設計とグルーピング戦略
- インシデント発生時の自動分析・ランブック生成テクニック
- SES現場でのSRE・監視案件に活かせる実践パターン
エラー監視の全体設計
監視ツールの選択と役割分担
本番環境のエラー監視には、複数のツールを組み合わせるのが一般的です。Gemini CLIに監視設計を相談するところから始めましょう。
gemini "以下のアーキテクチャに最適な監視戦略を設計して:
- フロントエンド: Next.js (Vercel)
- バックエンド: Go (Kubernetes on GKE)
- データベース: PostgreSQL (Cloud SQL)
- キュー: Redis (Memorystore)
- 外部連携: Stripe, SendGrid
監視レイヤーごとに最適なツールと、カバーすべきメトリクスを提案して"Gemini CLIが提案する監視アーキテクチャ:
| 監視レイヤー | ツール | 対象メトリクス |
|---|---|---|
| アプリケーションエラー | Sentry | 例外・クラッシュ・パフォーマンス |
| インフラメトリクス | Datadog / Cloud Monitoring | CPU・メモリ・ディスク・ネットワーク |
| ログ集約 | Cloud Logging | 構造化ログ・監査ログ |
| APM(パフォーマンス) | Datadog APM / Cloud Trace | レイテンシ・スループット・エラー率 |
| 外部サービス | 各ツールの Webhook + Betteruptime | API可用性・レスポンスタイム |
| アラート配信 | PagerDuty / Opsgenie | エスカレーション・オンコール管理 |
監視設計のIaC化
Gemini CLIを使えば、監視ルールをInfrastructure as Code(IaC)として管理するための設定ファイルも生成できます。
gemini "Terraformで以下のDatadog監視ルールを定義して:
1. APIエラー率 > 5% → warning、> 10% → critical
2. レスポンスタイム P95 > 500ms → warning、> 1000ms → critical
3. Pod再起動回数 > 3回/5分 → critical
4. DB接続プール使用率 > 80% → warning
5. Redis メモリ使用率 > 70% → warning
各アラートにSlack通知(#alerts-production)とPagerDuty連携を設定"生成されるTerraformコード:
# monitoring/datadog_monitors.tf
resource "datadog_monitor" "api_error_rate" {
name = "[Production] API Error Rate High"
type = "query alert"
message = <<-EOT
## API Error Rate Alert
API error rate has exceeded threshold.
### Impact
- Users may be experiencing failures
- Check recent deployments
### Investigation Steps
1. Check Sentry for new error clusters
2. Review recent deployments in ArgoCD
3. Check dependent service status
@slack-alerts-production
@pagerduty-production-oncall
EOT
query = "sum(last_5m):sum:http.requests.errors{service:api,env:production}.as_rate() / sum:http.requests.total{service:api,env:production}.as_rate() * 100 > 10"
monitor_thresholds {
warning = 5
critical = 10
}
notify_no_data = true
no_data_timeframe = 10
renotify_interval = 30
tags = ["service:api", "env:production", "team:backend"]
}
resource "datadog_monitor" "api_latency_p95" {
name = "[Production] API Latency P95 High"
type = "query alert"
message = <<-EOT
## API Latency P95 Alert
P95 latency: {{value}}ms (threshold: {{threshold}}ms)
### Potential Causes
- Database query slowdown
- External service degradation
- Resource contention
@slack-alerts-production
{{#is_critical}}@pagerduty-production-oncall{{/is_critical}}
EOT
query = "percentile(last_5m):p95:trace.http.request.duration{service:api,env:production} > 1000000000"
monitor_thresholds {
warning = 500000000 # 500ms in nanoseconds
critical = 1000000000 # 1000ms in nanoseconds
}
tags = ["service:api", "env:production", "team:backend"]
}
resource "datadog_monitor" "pod_restart" {
name = "[Production] Pod Restart Count High"
type = "query alert"
message = <<-EOT
## Pod Restart Alert
Pod {{pod_name.name}} has restarted {{value}} times in the last 5 minutes.
### Investigation
1. `kubectl describe pod {{pod_name.name}} -n production`
2. `kubectl logs {{pod_name.name}} -n production --previous`
3. Check OOMKilled or CrashLoopBackOff events
@slack-alerts-production @pagerduty-production-oncall
EOT
query = "sum(last_5m):sum:kubernetes.containers.restarts{kube_namespace:production} by {pod_name} > 3"
monitor_thresholds {
critical = 3
}
tags = ["env:production", "team:platform"]
}
resource "datadog_monitor" "db_connection_pool" {
name = "[Production] DB Connection Pool Usage High"
type = "query alert"
message = <<-EOT
## Database Connection Pool Alert
Connection pool usage: {{value}}%
### Actions
- Check for long-running queries
- Consider increasing pool size
- Review connection leak patterns
@slack-alerts-production
EOT
query = "avg(last_5m):avg:postgresql.connections.active{env:production} / avg:postgresql.connections.max{env:production} * 100 > 80"
monitor_thresholds {
warning = 80
critical = 95
}
tags = ["service:postgresql", "env:production", "team:backend"]
}
resource "datadog_monitor" "redis_memory" {
name = "[Production] Redis Memory Usage High"
type = "query alert"
message = <<-EOT
## Redis Memory Alert
Redis memory usage: {{value}}%
### Actions
- Check for key accumulation patterns
- Review TTL settings
- Consider eviction policy
@slack-alerts-production
EOT
query = "avg(last_5m):avg:redis.mem.used{env:production} / avg:redis.mem.max_memory{env:production} * 100 > 70"
monitor_thresholds {
warning = 70
critical = 90
}
tags = ["service:redis", "env:production", "team:backend"]
}Sentryでのエラー監視設計
Sentry SDK設定の最適化
Gemini CLIにSentry SDKの設定を最適化させましょう。
gemini "Next.js + Go のプロジェクトでSentry SDKの設定を最適化して。
以下を含めて:
- 環境ごとのサンプリングレート(dev: 100%, staging: 50%, production: 10%)
- パフォーマンストレース設定
- ユーザーコンテキスト設定
- PII(個人情報)のスクラビング
- カスタムタグ(service, version, region)
- 不要なエラーのフィルタリング(ResizeObserverのエラー等)"フロントエンド側(Next.js)の設定:
// sentry.client.config.ts
import * as Sentry from '@sentry/nextjs';
Sentry.init({
dsn: process.env.NEXT_PUBLIC_SENTRY_DSN,
environment: process.env.NEXT_PUBLIC_APP_ENV,
release: process.env.NEXT_PUBLIC_APP_VERSION,
// 環境別サンプリングレート
tracesSampleRate: {
production: 0.1,
staging: 0.5,
development: 1.0,
}[process.env.NEXT_PUBLIC_APP_ENV ?? 'development'] ?? 1.0,
// エラーフィルタリング
beforeSend(event) {
// ResizeObserver系のノイズを除外
if (event.exception?.values?.some(e =>
e.value?.includes('ResizeObserver') ||
e.value?.includes('Non-Error promise rejection')
)) {
return null;
}
// PII スクラビング
if (event.request?.cookies) {
event.request.cookies = '[Filtered]';
}
return event;
},
// パフォーマンスモニタリング
integrations: [
Sentry.browserTracingIntegration({
tracePropagationTargets: [
'localhost',
/^https:\/\/api\.example\.com/,
],
}),
Sentry.replayIntegration({
maskAllText: true,
blockAllMedia: true,
}),
],
// Session Replay(本番のみ、エラー発生時は100%)
replaysSessionSampleRate: process.env.NEXT_PUBLIC_APP_ENV === 'production' ? 0.01 : 0,
replaysOnErrorSampleRate: 1.0,
});バックエンド側(Go)の設定:
// internal/observability/sentry.go
package observability
import (
"os"
"time"
"github.com/getsentry/sentry-go"
)
func InitSentry() error {
env := os.Getenv("APP_ENV")
sampleRate := 1.0
switch env {
case "production":
sampleRate = 0.1
case "staging":
sampleRate = 0.5
}
return sentry.Init(sentry.ClientOptions{
Dsn: os.Getenv("SENTRY_DSN"),
Environment: env,
Release: os.Getenv("APP_VERSION"),
TracesSampleRate: sampleRate,
BeforeSend: func(event *sentry.Event, hint *sentry.EventHint) *sentry.Event {
// PIIスクラビング
for i := range event.Exception {
event.Exception[i].Value = scrubPII(event.Exception[i].Value)
}
// カスタムタグ追加
event.Tags["service"] = "api"
event.Tags["region"] = os.Getenv("CLOUD_REGION")
return event
},
// HTTPクライアントのタイムアウト
HTTPTransport: &sentry.HTTPTransport{
Timeout: 5 * time.Second,
},
})
}アラートルールの自動生成
Sentryのアラートルールをプログラマティックに管理します。
gemini "Sentry APIでアラートルールを作成するスクリプトを書いて。
以下のルールを設定:
1. 新しいエラーが発生 → Slack即時通知
2. エラー頻度が1時間で100回超 → PagerDuty
3. 特定エンドポイントのP95レイテンシ > 2秒 → Slack
4. リリース後24時間のエラー率が前リリース比200%超 → Critical通知"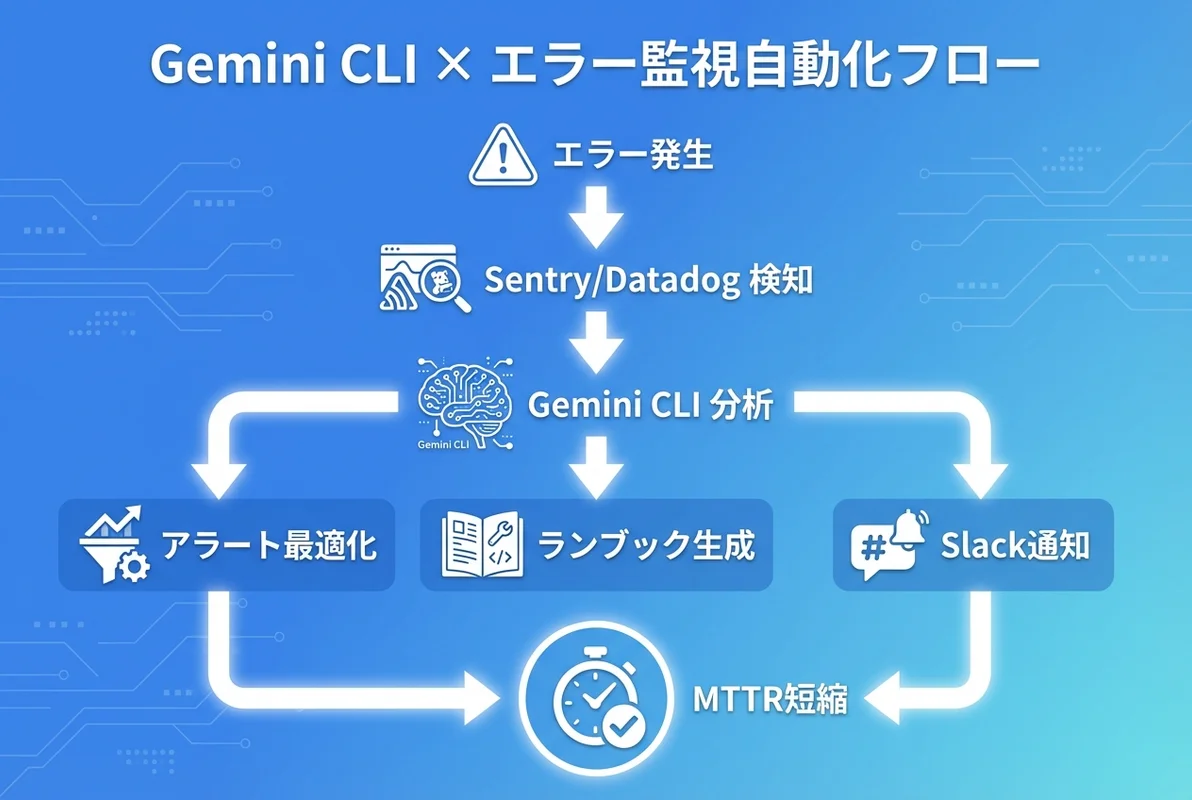
アラート疲れの解消
ノイズ分析と最適化
アラート疲れは多くのSRE/DevOpsチームが直面する問題です。Gemini CLIで過去のアラートデータを分析し、改善策を提案させましょう。
gemini "以下の過去30日のアラートデータを分析して、アラート疲れの原因と改善策を提案して:
- 総アラート数: 2,847件
- 内訳:
- API 5xxエラー: 1,203件(42%)→ 対応率12%
- Pod再起動: 856件(30%)→ 対応率5%
- メモリ使用率: 412件(14%)→ 対応率3%
- DB接続エラー: 198件(7%)→ 対応率45%
- 外部サービス障害: 178件(6%)→ 対応率68%
- 夜間(22:00-08:00)のアラート: 全体の43%
- 月曜日のアラート: 全体の22%
対応率が低いアラートのしきい値を見直し、actionableなアラートのみにする方法を具体的に教えて"Gemini CLIの分析と提案:
## アラート疲れ分析レポート
### 問題点
1. **Signal-to-Noise比が極めて低い**: 対応率の加重平均が約15%
→ 85%のアラートが「ノイズ」
2. **Pod再起動アラートが過剰**: 30%を占めるが対応率5%
→ OOMKillされるがKubernetesが自動回復するケースが大半
3. **月曜スパイク**: 週末のバッチ処理やcronジョブが原因の可能性
### 改善提案
#### 1. API 5xxエラーのしきい値見直し
- 現在: 1回でもアラート → 改善: 5分間で10回以上
- 根拠: 単発のエラーは自然回復が多い(対応率12%)
- 効果: 推定70%のアラート削減
#### 2. Pod再起動アラートの再設計
- 現在: 再起動ごとにアラート → 改善: 5分間で3回以上のCrashLoopBackOff
- OOMKillは別アラート(メモリリミット調整の検討材料として)
- 効果: 推定85%のアラート削減
#### 3. メモリ使用率のしきい値引き上げ
- 現在: 70% → 改善: 85%(warning), 95%(critical)
- GKEのHPA設定でスケールアウト済みなら、70%は正常動作範囲
- 効果: 推定60%のアラート削減
#### 4. 夜間アラートポリシーの導入
- 夜間(22:00-08:00)はcriticalのみ通知
- warningは翌朝のダイジェストにまとめる
- 効果: 夜間の不要な起床を防止アラートの優先度設計
gemini "4段階のアラート優先度マトリクスを設計して:
P1(即座にページ)、P2(30分以内に対応)、P3(営業時間内に対応)、P4(週次レビュー)
各優先度の条件、通知先、エスカレーションルールも含めて"| 優先度 | 条件例 | 通知先 | エスカレーション |
|---|---|---|---|
| P1 Critical | サービス全断、データ損失の恐れ | PagerDuty → オンコール電話 | 15分未応答 → マネージャー |
| P2 High | 機能一部障害、エラー率急増 | Slack #alerts + PagerDuty | 30分未応答 → P1昇格 |
| P3 Medium | パフォーマンス劣化、非致命的エラー | Slack #alerts のみ | 営業時間内に対応 |
| P4 Low | しきい値接近、改善推奨 | 週次ダイジェスト | レビュー時に判断 |
インシデント対応の自動化
ランブック(対応手順書)の自動生成
Gemini CLIを使って、インシデント種類ごとのランブックを自動生成できます。
gemini "以下のインシデントタイプごとにランブックを作成して。
各ランブックに含めるもの:
- 症状と影響範囲の特定方法
- 初動対応手順(コマンド付き)
- エスカレーション基準
- 復旧確認の手順
インシデントタイプ:
1. APIサーバー応答なし
2. データベース接続タイムアウト
3. メモリリーク(OOMKill多発)
4. 外部APIレート制限到達
5. 証明書期限切れ"生成されるランブック例(APIサーバー応答なし):
# ランブック: APIサーバー応答なし
## 症状
- ヘルスチェック失敗
- HTTP 502/503 エラー増加
- フロントエンドからのAPI呼び出し全失敗
## 影響範囲の確認
```bash
# 1. Pod状態の確認
kubectl get pods -n production -l app=api
# 2. 最新のイベント確認
kubectl get events -n production --sort-by=.lastTimestamp | tail -20
# 3. サービスエンドポイント確認
kubectl get endpoints api-service -n production
# 4. Ingress/LoadBalancer状態確認
kubectl describe ingress api-ingress -n production初動対応
Step 1: 原因の切り分け(5分以内)
# Podのログ確認
kubectl logs -l app=api -n production --tail=100
# リソース使用状況
kubectl top pods -n production -l app=api
# 直近のデプロイ確認
kubectl rollout history deployment/api -n productionStep 2: 即時復旧(10分以内)
# Option A: Podの再起動
kubectl rollout restart deployment/api -n production
# Option B: 前バージョンへのロールバック
kubectl rollout undo deployment/api -n production
# Option C: スケールアウト
kubectl scale deployment/api -n production --replicas=5エスカレーション基準
- 15分以内に復旧しない場合 → P1昇格、CTO通知
- データ損失の疑いがある場合 → 即座にP1、全チームメンバー招集
復旧確認
# ヘルスチェック
curl -s https://api.example.com/health | jq .
# エラー率の確認(Datadog)
# ダッシュボード: https://app.datadoghq.com/dashboard/xxx
# 直近5分のリクエスト成功率
kubectl logs -l app=api -n production --since=5m | grep -c "200 OK"
### Slack通知テンプレートの生成
```bash
gemini "インシデント発生時のSlack通知テンプレートを3パターン作成して:
1. インシデント発生通知(Block Kit形式)
2. 調査中アップデート
3. 復旧完了通知
JSONでBlock Kit形式で出力して"{
"blocks": [
{
"type": "header",
"text": {
"type": "plain_text",
"text": "🚨 インシデント発生 [P1]",
"emoji": true
}
},
{
"type": "section",
"fields": [
{
"type": "mrkdwn",
"text": "*影響サービス:*\nAPI Gateway"
},
{
"type": "mrkdwn",
"text": "*検知時刻:*\n2026-03-24 14:30 JST"
},
{
"type": "mrkdwn",
"text": "*影響範囲:*\n全ユーザー"
},
{
"type": "mrkdwn",
"text": "*担当者:*\n@oncall-engineer"
}
]
},
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": "*症状:* APIエンドポイントが502を返却。ユーザーのログイン・データ取得が不可。"
}
},
{
"type": "actions",
"elements": [
{
"type": "button",
"text": { "type": "plain_text", "text": "📊 ダッシュボード" },
"url": "https://app.datadoghq.com/dashboard/xxx"
},
{
"type": "button",
"text": { "type": "plain_text", "text": "📋 ランブック" },
"url": "https://wiki.example.com/runbooks/api-down"
}
]
}
]
}CloudWatch + Gemini CLIの連携
CloudWatchアラームの効率的な設定
AWS環境でのエラー監視は、CloudWatchが中心になります。Gemini CLIでアラーム設定を効率化しましょう。
gemini "CloudFormationで以下のCloudWatchアラームを作成して:
- ALBのHTTP 5xxエラー率 > 5%
- Lambda関数のエラー率 > 3%
- RDSのCPU使用率 > 80%
- SQSのデッドレターキュー深度 > 10
- ECSタスクの異常終了
SNSトピック経由でSlackとPagerDutyに通知"# cloudwatch-alarms.yaml
AWSTemplateFormatVersion: '2010-09-09'
Description: Production Monitoring Alarms
Parameters:
AlertSNSTopicArn:
Type: String
Description: SNS Topic for alert notifications
Resources:
ALB5xxAlarm:
Type: AWS::CloudWatch::Alarm
Properties:
AlarmName: production-alb-5xx-rate
AlarmDescription: ALB HTTP 5xx error rate exceeds 5%
Namespace: AWS/ApplicationELB
MetricName: HTTPCode_Target_5XX_Count
Dimensions:
- Name: LoadBalancer
Value: !Ref ALBArn
Statistic: Sum
Period: 300
EvaluationPeriods: 2
Threshold: 5
ComparisonOperator: GreaterThanThreshold
TreatMissingData: notBreaching
AlarmActions:
- !Ref AlertSNSTopicArn
OKActions:
- !Ref AlertSNSTopicArn
LambdaErrorAlarm:
Type: AWS::CloudWatch::Alarm
Properties:
AlarmName: production-lambda-error-rate
AlarmDescription: Lambda error rate exceeds 3%
Namespace: AWS/Lambda
MetricName: Errors
Statistic: Sum
Period: 300
EvaluationPeriods: 2
Threshold: 3
ComparisonOperator: GreaterThanThreshold
AlarmActions:
- !Ref AlertSNSTopicArn
RDSCPUAlarm:
Type: AWS::CloudWatch::Alarm
Properties:
AlarmName: production-rds-cpu-high
AlarmDescription: RDS CPU utilization exceeds 80%
Namespace: AWS/RDS
MetricName: CPUUtilization
Dimensions:
- Name: DBInstanceIdentifier
Value: !Ref RDSInstanceId
Statistic: Average
Period: 300
EvaluationPeriods: 3
Threshold: 80
ComparisonOperator: GreaterThanThreshold
AlarmActions:
- !Ref AlertSNSTopicArn
DLQDepthAlarm:
Type: AWS::CloudWatch::Alarm
Properties:
AlarmName: production-dlq-depth
AlarmDescription: Dead letter queue depth exceeds 10
Namespace: AWS/SQS
MetricName: ApproximateNumberOfMessagesVisible
Dimensions:
- Name: QueueName
Value: !Ref DLQName
Statistic: Maximum
Period: 60
EvaluationPeriods: 1
Threshold: 10
ComparisonOperator: GreaterThanThreshold
AlarmActions:
- !Ref AlertSNSTopicArn構造化ログとエラー分析
ログからのパターン検出
Gemini CLIにログデータを分析させ、エラーのパターンを検出します。
gemini "以下のアプリケーションログからエラーパターンを分析して:
- 過去24時間のエラーログ1,234件
- 上位5つのエラータイプと発生頻度
- 時間帯ごとの分布
- 相関関係(特定のデプロイ後に増加したか等)
具体的な改善アクションも提案して"構造化ログの設計支援
gemini "GoのWebアプリケーション向けに構造化ログの設計を行って:
- ログライブラリ: slog(Go 1.21標準)
- 出力先: Cloud Logging(JSON形式)
- リクエストごとにtraceIdとspanIdを付与
- エラーログにはスタックトレースを含める
- PIIフィールド(email, phone等)は自動マスク
- ログレベル: DEBUG/INFO/WARN/ERROR/FATAL"// internal/logger/logger.go
package logger
import (
"context"
"log/slog"
"os"
"runtime"
"strings"
)
var piiFields = map[string]bool{
"email": true, "phone": true, "password": true,
"credit_card": true, "ssn": true, "address": true,
}
type PIIMaskHandler struct {
slog.Handler
}
func (h *PIIMaskHandler) Handle(ctx context.Context, r slog.Record) error {
var masked []slog.Attr
r.Attrs(func(a slog.Attr) bool {
key := strings.ToLower(a.Key)
if piiFields[key] {
masked = append(masked, slog.String(a.Key, "[REDACTED]"))
}
return true
})
for _, a := range masked {
r.AddAttrs(a)
}
return h.Handler.Handle(ctx, r)
}
func NewLogger() *slog.Logger {
baseHandler := slog.NewJSONHandler(os.Stdout, &slog.HandlerOptions{
Level: slog.LevelInfo,
AddSource: true,
})
return slog.New(&PIIMaskHandler{Handler: baseHandler})
}
func ErrorWithStack(msg string, err error) slog.Attr {
buf := make([]byte, 4096)
n := runtime.Stack(buf, false)
return slog.Group("error",
slog.String("message", err.Error()),
slog.String("stack", string(buf[:n])),
)
}SES現場での監視スキル
SRE/DevOps案件での需要
エラー監視・インシデント対応のスキルは、SES市場でSRE・DevOps系案件の中核スキルです。
| スキルセット | 月額単価相場(2026年) |
|---|---|
| インフラ監視(基本) | 55〜70万円 |
| Datadog / New Relic 運用経験 | 70〜90万円 |
| SRE(監視設計・インシデント対応) | 80〜100万円 |
| 監視IaC + 自動復旧設計 | 85〜105万円 |
| 上記 + AIツール活用 | 90〜110万円 |
監視設計のポートフォリオ作成
SES面談でアピールできる監視設計の実績をGemini CLIで整理しましょう。
gemini "SRE/DevOps案件の面談向けに、以下の監視設計実績をまとめたポートフォリオドキュメントを作成して:
- 監視ツール: Datadog, Sentry, CloudWatch, PagerDuty
- 対象: Kubernetes(GKE)上のマイクロサービス10サービス
- 実績: アラート数73%削減、MTTR 45分→12分に短縮
- 導入したプラクティス: SLI/SLO設計、エラーバジェット運用、ランブック整備"まとめ — エラー監視をAIで進化させる
Gemini CLIを活用したエラー監視・アラート自動化は、本番運用の信頼性を大幅に向上させます。
- 監視設計のIaC化: Terraform/CloudFormationで監視ルールをコード管理し、レビュー可能に
- アラート疲れの解消: 過去データの分析からしきい値最適化、ノイズの85%削減を実現
- インシデント対応の高速化: ランブック自動生成とSlack通知テンプレートで初動を標準化
- 構造化ログ設計: PIIマスク・トレーシング・スタックトレースを含むログ基盤を効率的に構築
Gemini CLI入門ガイドで基本操作を押さえた上で、CI/CD自動化ガイドや監視ガイドと合わせて活用してください。SES現場でのSRE・DevOps案件での評価をクラウドデプロイガイドの知識と組み合わせて高めましょう。





