
- Gemini CLIでデータベースのスキーマ変更・データ移行・ロールバック手順を自動生成できる
- ゼロダウンタイムマイグレーションの設計パターンを対話的に構築し、本番リスクを最小化
- SES現場でのDB設計・移行スキルは月額80〜110万円クラスの案件に直結する
「本番DBのスキーマ変更が怖くて、毎回深夜メンテナンスで対応している…」「テーブル設計の変更を安全に行う手順を毎回ゼロから考えるのが大変…」——SES現場でデータベース関連の作業に不安を感じたことはありませんか。
結論から言うと、Gemini CLI(Google Antigravity)を活用すれば、データベースマイグレーションの設計・実装・検証を対話的に自動化できます。安全なスキーマ変更手順の生成、データ移行スクリプトの作成、ロールバック戦略の立案まで幅広く支援してくれます。
この記事はGemini CLI完全攻略シリーズとして、データベースマイグレーションの実践手法を解説します。
- Gemini CLIでマイグレーションファイルを自動生成する方法
- ゼロダウンタイムでスキーマ変更を行う設計パターン
- 大規模データ移行の安全な実行戦略
- ロールバック手順の自動生成とテスト方法
- SES現場でのDB移行プロジェクトの進め方
データベースマイグレーションの基礎知識
マイグレーションとは
データベースマイグレーションとは、DBのスキーマ(テーブル構造、インデックス、制約など)やデータを計画的に変更する作業です。
主なマイグレーションの種類は次の通りです。
| 種類 | 内容 | リスクレベル |
|---|---|---|
| スキーマ追加 | テーブル・カラムの追加 | 低 |
| スキーマ変更 | カラム型変更・制約追加 | 中 |
| スキーマ削除 | テーブル・カラムの削除 | 高 |
| データ移行 | レコードの変換・移動 | 高 |
| DB間移行 | MySQL→PostgreSQLなど | 非常に高 |
Gemini CLIがマイグレーションで力を発揮する場面
Gemini CLIは以下の場面で特に役立ちます。
- マイグレーションファイルの自動生成:要件を伝えるだけでSQLやORMマイグレーションを作成
- ゼロダウンタイム戦略の提案:複雑なスキーマ変更の安全な手順を設計
- ロールバックスクリプトの自動生成:変更を元に戻す手順を確実に準備
- データ整合性チェックの実装:移行後のデータ検証クエリを生成
- パフォーマンス影響の分析:インデックスやロック時間の見積もり
マイグレーションファイルの自動生成
基本的なマイグレーション生成
Gemini CLIに要件を伝えてマイグレーションを生成します。
usersテーブルにプロフィール情報を追加するマイグレーションを作成してください。
追加するカラム:
- display_name (varchar(100), nullable)
- avatar_url (text, nullable)
- bio (text, nullable)
- location (varchar(100), nullable)
- website_url (varchar(255), nullable)
- created_at, updated_at (timestamp)
使用DB: PostgreSQL 16
ORMマイグレーション: PrismaGemini CLIが生成するPrismaマイグレーションの例です。
-- migration.sql
-- CreateTable: user_profiles
CREATE TABLE "user_profiles" (
"id" UUID NOT NULL DEFAULT gen_random_uuid(),
"user_id" UUID NOT NULL,
"display_name" VARCHAR(100),
"avatar_url" TEXT,
"bio" TEXT,
"location" VARCHAR(100),
"website_url" VARCHAR(255),
"created_at" TIMESTAMP(3) NOT NULL DEFAULT CURRENT_TIMESTAMP,
"updated_at" TIMESTAMP(3) NOT NULL DEFAULT CURRENT_TIMESTAMP,
CONSTRAINT "user_profiles_pkey" PRIMARY KEY ("id")
);
-- CreateIndex
CREATE UNIQUE INDEX "user_profiles_user_id_key" ON "user_profiles"("user_id");
-- AddForeignKey
ALTER TABLE "user_profiles"
ADD CONSTRAINT "user_profiles_user_id_fkey"
FOREIGN KEY ("user_id") REFERENCES "users"("id")
ON DELETE CASCADE ON UPDATE CASCADE;
-- Trigger: updated_at自動更新
CREATE OR REPLACE FUNCTION update_updated_at_column()
RETURNS TRIGGER AS $$
BEGIN
NEW.updated_at = CURRENT_TIMESTAMP;
RETURN NEW;
END;
$$ language 'plpgsql';
CREATE TRIGGER update_user_profiles_updated_at
BEFORE UPDATE ON "user_profiles"
FOR EACH ROW
EXECUTE FUNCTION update_updated_at_column();Prismaスキーマの同期
// schema.prisma
model UserProfile {
id String @id @default(uuid()) @db.Uuid
userId String @unique @map("user_id") @db.Uuid
displayName String? @map("display_name") @db.VarChar(100)
avatarUrl String? @map("avatar_url") @db.Text
bio String? @db.Text
location String? @db.VarChar(100)
websiteUrl String? @map("website_url") @db.VarChar(255)
createdAt DateTime @default(now()) @map("created_at")
updatedAt DateTime @default(now()) @updatedAt @map("updated_at")
user User @relation(fields: [userId], references: [id], onDelete: Cascade)
@@map("user_profiles")
}ゼロダウンタイムマイグレーションの設計
Expand and Contract パターン
本番環境での安全なスキーマ変更にはExpand and Contractパターンが有効です。Gemini CLIにこのパターンでのマイグレーション手順を生成させます。
ordersテーブルのstatusカラムをvarcharからenumに変更したいです。
Expand and Contractパターンで、ゼロダウンタイムで移行する
手順を作成してください。Phase 1: Expand(拡張)
-- V001_add_status_enum.sql
-- 1. ENUM型を作成
CREATE TYPE order_status AS ENUM (
'pending', 'confirmed', 'processing',
'shipped', 'delivered', 'cancelled', 'refunded'
);
-- 2. 新しいカラムを追加(旧カラムは残す)
ALTER TABLE orders ADD COLUMN status_new order_status;
-- 3. トリガーで旧→新を同期
CREATE OR REPLACE FUNCTION sync_order_status()
RETURNS TRIGGER AS $$
BEGIN
IF TG_OP = 'INSERT' OR NEW.status IS DISTINCT FROM OLD.status THEN
NEW.status_new = NEW.status::order_status;
END IF;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER sync_status_trigger
BEFORE INSERT OR UPDATE ON orders
FOR EACH ROW
EXECUTE FUNCTION sync_order_status();Phase 2: Migrate(データ移行)
-- V002_migrate_status_data.sql
-- バッチ処理でデータを移行(大量データに対応)
DO $$
DECLARE
batch_size INT := 10000;
total_updated INT := 0;
rows_affected INT;
BEGIN
LOOP
UPDATE orders
SET status_new = status::order_status
WHERE status_new IS NULL
AND id IN (
SELECT id FROM orders
WHERE status_new IS NULL
LIMIT batch_size
FOR UPDATE SKIP LOCKED
);
GET DIAGNOSTICS rows_affected = ROW_COUNT;
total_updated := total_updated + rows_affected;
RAISE NOTICE 'Updated % rows (total: %)', rows_affected, total_updated;
EXIT WHEN rows_affected = 0;
-- 他のトランザクションに譲る
PERFORM pg_sleep(0.1);
END LOOP;
RAISE NOTICE 'Migration complete. Total rows: %', total_updated;
END $$;Phase 3: Contract(収縮)
-- V003_finalize_status_enum.sql
-- アプリケーションが完全にstatus_newを使うことを確認後
-- 1. NOT NULL制約を追加
ALTER TABLE orders ALTER COLUMN status_new SET NOT NULL;
-- 2. 旧カラムをリネーム
ALTER TABLE orders RENAME COLUMN status TO status_old;
ALTER TABLE orders RENAME COLUMN status_new TO status;
-- 3. トリガーを削除
DROP TRIGGER IF EXISTS sync_status_trigger ON orders;
DROP FUNCTION IF EXISTS sync_order_status();
-- 4. 旧カラムを削除(一定期間後)
-- ALTER TABLE orders DROP COLUMN status_old;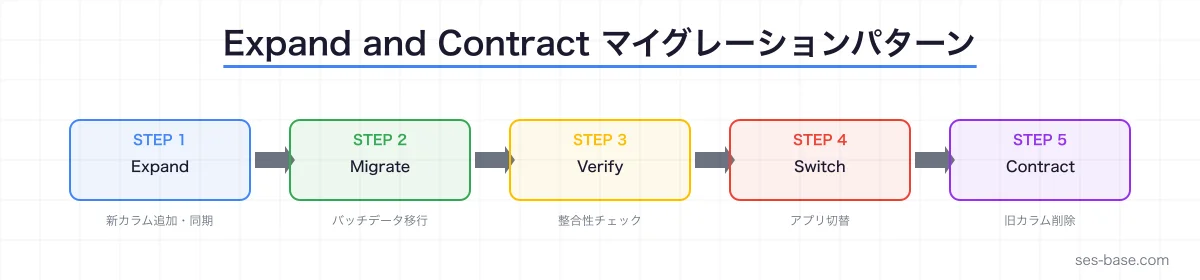
大規模データ移行の戦略
バッチ処理による安全な移行
数百万〜数億レコードのデータ移行では、バッチ処理が必須です。Gemini CLIで最適なバッチ移行スクリプトを生成します。
// scripts/migrate-data.ts
import { PrismaClient } from '@prisma/client';
const prisma = new PrismaClient();
interface MigrationConfig {
batchSize: number;
delayMs: number;
dryRun: boolean;
startId?: string;
}
async function migrateOrderData(config: MigrationConfig) {
const { batchSize, delayMs, dryRun, startId } = config;
let cursor = startId || undefined;
let totalProcessed = 0;
let totalErrors = 0;
console.log(`Starting migration (batchSize: ${batchSize}, dryRun: ${dryRun})`);
while (true) {
const orders = await prisma.order.findMany({
take: batchSize,
...(cursor ? {
skip: 1,
cursor: { id: cursor },
} : {}),
orderBy: { id: 'asc' },
where: {
migratedAt: null,
},
});
if (orders.length === 0) break;
const operations = orders.map(order => {
try {
const newData = transformOrderData(order);
return prisma.order.update({
where: { id: order.id },
data: {
...newData,
migratedAt: new Date(),
},
});
} catch (error) {
totalErrors++;
console.error(`Error processing order ${order.id}:`, error);
return prisma.migrationError.create({
data: {
entityId: order.id,
entityType: 'order',
error: String(error),
},
});
}
});
if (!dryRun) {
await prisma.$transaction(operations);
}
totalProcessed += orders.length;
cursor = orders[orders.length - 1].id;
console.log(
`Processed: ${totalProcessed}, Errors: ${totalErrors}, ` +
`Last ID: ${cursor}`
);
// レート制限
await new Promise(resolve => setTimeout(resolve, delayMs));
}
console.log(`Migration complete. Total: ${totalProcessed}, Errors: ${totalErrors}`);
}
function transformOrderData(order: any) {
return {
statusEnum: mapStatusToEnum(order.status),
totalAmountCents: Math.round(order.totalAmount * 100),
customerEmail: order.customer?.email?.toLowerCase(),
};
}
function mapStatusToEnum(status: string): string {
const mapping: Record<string, string> = {
'pending': 'PENDING',
'confirmed': 'CONFIRMED',
'processing': 'PROCESSING',
'shipped': 'SHIPPED',
'delivered': 'DELIVERED',
'cancelled': 'CANCELLED',
'refunded': 'REFUNDED',
};
return mapping[status] || 'PENDING';
}
// 実行
migrateOrderData({
batchSize: 5000,
delayMs: 100,
dryRun: process.argv.includes('--dry-run'),
startId: process.argv.find(a => a.startsWith('--start-id='))?.split('=')[1],
}).catch(console.error)
.finally(() => prisma.$disconnect());データ整合性チェック
移行後のデータ整合性を検証するスクリプトもGemini CLIで生成できます。
-- verify-migration.sql
-- 1. レコード数の一致確認
SELECT
'orders' AS table_name,
(SELECT COUNT(*) FROM orders) AS total_rows,
(SELECT COUNT(*) FROM orders WHERE migrated_at IS NOT NULL) AS migrated_rows,
(SELECT COUNT(*) FROM orders WHERE migrated_at IS NULL) AS pending_rows;
-- 2. ENUM値の分布確認
SELECT status_enum, COUNT(*) AS cnt
FROM orders
WHERE migrated_at IS NOT NULL
GROUP BY status_enum
ORDER BY cnt DESC;
-- 3. NULL値チェック(必須カラム)
SELECT COUNT(*) AS null_status_count
FROM orders
WHERE migrated_at IS NOT NULL
AND status_enum IS NULL;
-- 4. 金額変換の検証(サンプリング)
SELECT
id,
total_amount AS original,
total_amount_cents AS converted,
CASE
WHEN total_amount_cents = ROUND(total_amount * 100)
THEN 'OK'
ELSE 'MISMATCH'
END AS status
FROM orders
WHERE migrated_at IS NOT NULL
ORDER BY RANDOM()
LIMIT 1000;ロールバック戦略
自動ロールバックスクリプトの生成
Gemini CLIに「このマイグレーションのロールバック手順を作成して」と依頼すると、安全なロールバックスクリプトを生成します。
-- rollback_V001.sql
-- Phase 1のロールバック
-- 1. トリガーを削除
DROP TRIGGER IF EXISTS sync_status_trigger ON orders;
DROP FUNCTION IF EXISTS sync_order_status();
-- 2. 新カラムを削除
ALTER TABLE orders DROP COLUMN IF EXISTS status_new;
-- 3. ENUM型を削除
DROP TYPE IF EXISTS order_status;ロールバックのテスト
#!/bin/bash
# test-rollback.sh
set -euo pipefail
DB_URL="postgresql://user:pass@localhost:5432/testdb"
echo "🧪 ロールバックテスト開始..."
# テストDBをリストア
pg_restore -d "$DB_URL" --clean latest-backup.dump
# マイグレーション適用
echo "📦 マイグレーション適用中..."
psql "$DB_URL" -f migrations/V001_add_status_enum.sql
psql "$DB_URL" -f migrations/V002_migrate_status_data.sql
# データ整合性チェック
echo "✅ 移行後の整合性チェック..."
psql "$DB_URL" -f verify-migration.sql
# ロールバック実行
echo "🔄 ロールバック実行中..."
psql "$DB_URL" -f rollback/rollback_V002.sql
psql "$DB_URL" -f rollback/rollback_V001.sql
# ロールバック後の整合性チェック
echo "✅ ロールバック後の整合性チェック..."
ORIGINAL_COUNT=$(psql "$DB_URL" -t -c "SELECT COUNT(*) FROM orders")
AFTER_COUNT=$(psql "$DB_URL" -t -c "SELECT COUNT(*) FROM orders")
if [ "$ORIGINAL_COUNT" = "$AFTER_COUNT" ]; then
echo "🎉 ロールバックテスト成功!レコード数: $AFTER_COUNT"
else
echo "🚫 ロールバックテスト失敗!$ORIGINAL_COUNT → $AFTER_COUNT"
exit 1
fiDB間マイグレーション(MySQL → PostgreSQL)
移行計画の自動生成
Gemini CLIに「MySQL 8.0からPostgreSQL 16への移行計画を作成して」と依頼すると、包括的な移行計画を提案します。
現在MySQL 8.0で運用しているECサイトのデータベースを
PostgreSQL 16に移行したいです。
テーブル数: 45
総データ量: 約50GB
許容ダウンタイム: 最大2時間
移行計画を作成してください。型マッピングの自動生成
// mysql-to-postgres-type-mapping.ts
const TYPE_MAPPING: Record<string, string> = {
// 数値型
'tinyint(1)': 'boolean',
'tinyint': 'smallint',
'smallint': 'smallint',
'mediumint': 'integer',
'int': 'integer',
'bigint': 'bigint',
'float': 'real',
'double': 'double precision',
'decimal': 'numeric',
// 文字列型
'varchar': 'varchar',
'char': 'char',
'tinytext': 'text',
'text': 'text',
'mediumtext': 'text',
'longtext': 'text',
'enum': 'varchar', // PostgreSQLのENUM型に変換推奨
// 日付・時刻型
'date': 'date',
'datetime': 'timestamp',
'timestamp': 'timestamptz',
'time': 'time',
'year': 'smallint',
// バイナリ型
'blob': 'bytea',
'mediumblob': 'bytea',
'longblob': 'bytea',
// JSON
'json': 'jsonb',
};pgloaderによるデータ移行
;; pgloader-config.load
LOAD DATABASE
FROM mysql://user:pass@mysql-host:3306/ecommerce
INTO postgresql://user:pass@postgres-host:5432/ecommerce
WITH include drop,
create tables,
create indexes,
reset sequences,
workers = 8,
concurrency = 4,
batch rows = 25000,
prefetch rows = 100000
SET PostgreSQL PARAMETERS
maintenance_work_mem to '512MB',
work_mem to '128MB'
CAST type datetime to timestamptz using zero-dates-to-null,
type tinyint to boolean using tinyint-to-boolean,
type int when (= precision 11) to integer
BEFORE LOAD DO
$$ CREATE SCHEMA IF NOT EXISTS ecommerce; $$
AFTER LOAD DO
$$ ANALYZE; $$
$$ VACUUM ANALYZE; $$;パフォーマンス考慮事項
インデックス作成のベストプラクティス
大規模テーブルでのインデックス作成はロックを伴うため、CONCURRENTLYオプションが重要です。
-- ゼロダウンタイムでのインデックス作成
CREATE INDEX CONCURRENTLY idx_orders_customer_status
ON orders (customer_id, status_enum)
WHERE status_enum NOT IN ('CANCELLED', 'REFUNDED');
-- パーシャルインデックスでディスク使用量を削減
CREATE INDEX CONCURRENTLY idx_orders_pending
ON orders (created_at DESC)
WHERE status_enum = 'PENDING';マイグレーション時のパフォーマンスモニタリング
-- ロック状況の監視
SELECT
pid,
now() - pg_stat_activity.query_start AS duration,
query,
state,
wait_event_type,
wait_event
FROM pg_stat_activity
WHERE state != 'idle'
AND query NOT ILIKE '%pg_stat%'
ORDER BY duration DESC;
-- テーブルサイズとブロート率の確認
SELECT
schemaname || '.' || tablename AS table,
pg_size_pretty(pg_total_relation_size(schemaname || '.' || tablename)) AS total_size,
pg_size_pretty(pg_relation_size(schemaname || '.' || tablename)) AS table_size,
pg_size_pretty(pg_indexes_size(schemaname || '.' || tablename)) AS index_size
FROM pg_tables
WHERE schemaname = 'public'
ORDER BY pg_total_relation_size(schemaname || '.' || tablename) DESC
LIMIT 20;データベース最適化の詳細は「Gemini CLI × データベース最適化ガイド」を参照してください。
CI/CDパイプラインへの統合
GitHub Actionsでのマイグレーション自動化
name: Database Migration
on:
push:
branches: [main]
paths:
- 'prisma/migrations/**'
jobs:
migrate-staging:
runs-on: ubuntu-latest
environment: staging
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
- name: Install dependencies
run: npm ci
- name: Run migration (staging)
env:
DATABASE_URL: ${{ secrets.STAGING_DATABASE_URL }}
run: |
npx prisma migrate deploy
npx prisma db seed
- name: Verify migration
env:
DATABASE_URL: ${{ secrets.STAGING_DATABASE_URL }}
run: |
npx ts-node scripts/verify-migration.tsCI/CD自動化の詳細は「Gemini CLI × CI/CD自動化ガイド」をご覧ください。
SES現場でのDB移行プロジェクトの進め方
プロジェクト計画テンプレート
Gemini CLIで移行プロジェクトの計画書を生成できます。
| フェーズ | 期間 | タスク |
|---|---|---|
| 調査・分析 | 1〜2週間 | 現行DB分析、移行対象の洗い出し |
| 設計 | 1〜2週間 | 移行戦略決定、スクリプト作成 |
| テスト環境検証 | 2〜3週間 | テスト環境での移行実行・検証 |
| ステージング検証 | 1〜2週間 | 本番データを使った最終検証 |
| 本番移行 | 1〜2日 | 本番環境での移行実行 |
| 安定化 | 1〜2週間 | 監視・パフォーマンスチューニング |
SES案件での単価への影響
DB移行スキルはSES市場で非常に高い需要があります。
| スキルレベル | 想定月額単価 | 内容 |
|---|---|---|
| 基本 | 60〜75万円 | ORMマイグレーション、基本的なスキーマ変更 |
| 中級 | 75〜90万円 | ゼロダウンタイム移行、バッチデータ移行 |
| 上級 | 90〜110万円 | DB間移行設計、パフォーマンスチューニング |
| エキスパート | 110万円〜 | 大規模移行プロジェクトのPM・アーキテクト |
テスト自動化と組み合わせることでさらに価値が高まります。詳しくは「Gemini CLI × テスト自動化ガイド」を参照してください。
まとめ:Gemini CLIでデータベース移行を安全に自動化
この記事のポイントをまとめます。
- Gemini CLIでマイグレーションファイルの自動生成が可能(Prisma、生SQL両対応)
- Expand and Contractパターンでゼロダウンタイムのスキーマ変更を実現
- バッチ処理による大規模データ移行で本番環境への影響を最小化
- ロールバックスクリプトの自動生成とテストで安全網を確保
- DB間移行(MySQL→PostgreSQL)も型マッピングからデータ検証まで自動化
- CI/CDパイプラインへの統合でマイグレーションのデプロイを自動化
Gemini CLIを活用して安全なデータベースマイグレーションスキルを身につけ、SES市場での競争力を高めましょう。
SES BASEでデータベース設計案件を探す
DB設計・マイグレーション・データエンジニアリングの経験を活かせるSES案件をSES BASEで検索してみてください。





