
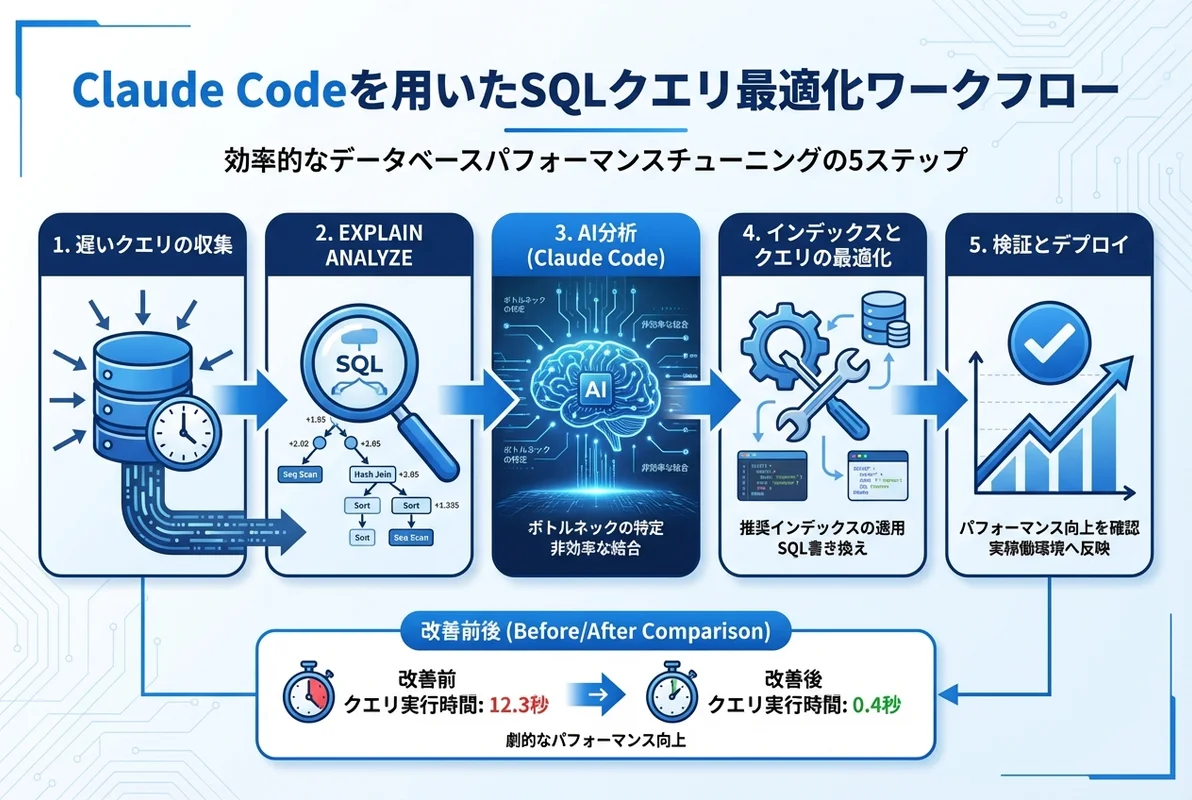
- Claude Codeにスロークエリを渡すだけで、ボトルネック特定からインデックス提案まで自動で行える
- EXPLAIN ANALYZEの出力をClaude Codeに解析させることで、実行計画の読み方を習得できる
- SES現場でのDB改善案件は単価65-85万円と高単価で、SQL最適化スキルは差別化要因になる
「本番環境のSQLクエリが遅い…でもどこから手をつければいいかわからない」
データベースのパフォーマンス問題は、多くのSES現場で頻繁に直面する課題です。特に、レガシーシステムの保守やリプレイス案件では、長年蓄積された非効率なクエリが原因でシステム全体の応答性能が低下しているケースが少なくありません。
Claude Codeを使えば、スロークエリの分析・最適化・インデックス設計を対話的に進められます。この記事では、実践的なSQL最適化ワークフローを体系的に解説します。
- Claude Codeを使ったスロークエリの特定・分析方法
- EXPLAIN ANALYZEの出力をAIで読み解くテクニック
- インデックス設計の自動提案と検証ワークフロー
- N+1問題・サブクエリ・JOINの最適化パターン
- SES現場でのDB最適化案件の需要と必要スキル
Claude Code × SQL最適化の基本ワークフロー
なぜClaude CodeでSQL最適化なのか
従来のSQL最適化では、DBAやシニアエンジニアが実行計画を手動で分析し、経験に基づいてチューニングを行っていました。Claude Codeを活用することで、このプロセスを大幅に効率化できます。
| 従来のアプローチ | Claude Code活用 |
|---|---|
| EXPLAIN結果を手動で解析 | 実行計画をコピペして自動分析 |
| インデックス設計を経験ベースで判断 | データ分布とクエリパターンから最適解を提案 |
| チューニング効果の検証に数時間 | 複数パターンを即座に生成・比較 |
| ドキュメント作成が後回し | 最適化の理由と効果を自動文書化 |
基本的な使い方
Claude Codeにスロークエリを渡す際は、以下の情報を含めると精度が上がります。
# Claude Codeに渡すコンテキストの例
claude "以下のSQLクエリを最適化してください。
-- 現在のクエリ(実行時間: 12.3秒)
SELECT u.name, u.email, COUNT(o.id) as order_count,
SUM(o.total_amount) as total_spent
FROM users u
LEFT JOIN orders o ON u.id = o.user_id
WHERE u.created_at >= '2025-01-01'
AND o.status = 'completed'
GROUP BY u.id, u.name, u.email
HAVING COUNT(o.id) > 5
ORDER BY total_spent DESC
LIMIT 100;
-- テーブル情報
-- users: 500万行, orders: 2000万行
-- 既存インデックス: users(id), orders(id), orders(user_id)
-- DB: PostgreSQL 16
-- 問題: フルテーブルスキャンが発生している"Claude Codeは以下のような最適化提案を返します。
-- 最適化後のクエリ
SELECT u.name, u.email, o_agg.order_count, o_agg.total_spent
FROM users u
INNER JOIN (
SELECT user_id,
COUNT(*) as order_count,
SUM(total_amount) as total_spent
FROM orders
WHERE status = 'completed'
GROUP BY user_id
HAVING COUNT(*) > 5
) o_agg ON u.id = o_agg.user_id
WHERE u.created_at >= '2025-01-01'
ORDER BY o_agg.total_spent DESC
LIMIT 100;
-- 推奨インデックス
CREATE INDEX idx_orders_status_user ON orders(status, user_id)
INCLUDE (total_amount);
CREATE INDEX idx_users_created_at ON users(created_at);EXPLAIN ANALYZEの自動解析
実行計画をClaude Codeに読ませる
SQL最適化で最も重要なのは、実行計画(Execution Plan)を正しく読むことです。Claude Codeは、EXPLAINの出力を構造的に解析し、ボトルネックを特定できます。
# PostgreSQLの実行計画を取得してClaude Codeに渡す
psql -d mydb -c "EXPLAIN (ANALYZE, BUFFERS, FORMAT TEXT)
SELECT ... " > /tmp/explain_output.txt
claude "以下のEXPLAIN ANALYZE結果を分析して、
ボトルネックと改善案を教えてください。
$(cat /tmp/explain_output.txt)"Claude Codeが特定する主なボトルネック
Claude Codeは以下のパターンを自動的に検出します。
1. Sequential Scan(全件スキャン)
Seq Scan on orders (cost=0.00..458432.00 rows=20000000)
Filter: (status = 'completed')
Rows Removed by Filter: 15000000Claude Codeの分析結果例:
「ordersテーブルで全件スキャンが発生しています。status列の選択性が高い(completed = 25%)ため、
CREATE INDEX idx_orders_status ON orders(status)で大幅に改善できます。」
2. Nested Loop(ネステッドループ)の過剰使用
Nested Loop (cost=0.43..2584621.43 rows=5000000)
-> Seq Scan on users
-> Index Scan using idx_orders_user_id on ordersClaude Codeの分析結果例:
「500万行のusersテーブルに対してNested Loopが使われています。Hash Joinに切り替わるように
SET work_mem = '256MB'を試すか、usersテーブルにWHERE句を追加して走査行数を減らしてください。」
3. Sort + Limit(ソートのコスト)
Sort (cost=1235678.90..1235690.12 rows=5000)
Sort Key: total_spent DESC
Sort Method: external merge Disk: 102400kBClaude Codeの分析結果例:
「ソートがディスクに溢れています(102MB)。
work_memを増やすか、インデックスを活用してソートを不要にする方法を検討してください。」
インデックス設計の自動提案
カバリングインデックスの提案
Claude Codeにテーブル定義とクエリパターンを渡すと、カバリングインデックスを提案してくれます。
claude "以下のクエリパターンに最適なインデックスを設計してください。
-- クエリ1: ユーザー一覧(頻度: 1000回/分)
SELECT id, name, email FROM users
WHERE status = 'active' AND department_id = 3
ORDER BY created_at DESC LIMIT 20;
-- クエリ2: ユーザー検索(頻度: 500回/分)
SELECT id, name, email, phone FROM users
WHERE email LIKE 'tanaka%' AND status = 'active';
-- クエリ3: 集計(頻度: 10回/分)
SELECT department_id, COUNT(*) FROM users
WHERE status = 'active'
GROUP BY department_id;
-- テーブル定義
CREATE TABLE users (
id BIGINT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(255),
phone VARCHAR(20),
status VARCHAR(20),
department_id INT,
created_at TIMESTAMP
);
-- 行数: 300万行
-- statusの分布: active=70%, inactive=20%, suspended=10%"Claude Codeの提案例:
-- クエリ1+3をカバー(最も頻度が高い)
CREATE INDEX idx_users_status_dept_created
ON users(status, department_id, created_at DESC)
INCLUDE (name, email);
-- クエリ2をカバー
CREATE INDEX idx_users_email_prefix
ON users(email varchar_pattern_ops)
WHERE status = 'active';
-- 部分インデックスで70%の行だけに適用しサイズ削減インデックスの効果検証
Claude Codeに最適化前後の実行計画を比較させることで、効果を定量的に評価できます。
claude "以下の2つのEXPLAIN ANALYZE結果を比較して、
改善効果をレポートしてください。
=== BEFORE(インデックス追加前)===
$(cat /tmp/explain_before.txt)
=== AFTER(インデックス追加後)===
$(cat /tmp/explain_after.txt)"N+1問題の検出と解決
N+1問題をClaude Codeで検出する
N+1問題は、SES現場でよく遭遇するパフォーマンス問題の代表格です。Claude Codeにアプリケーションコードを分析させることで、N+1問題を自動検出できます。
# Railsアプリケーションの例
claude "以下のRailsコードにN+1問題がないか分析してください。
# app/controllers/projects_controller.rb
class ProjectsController < ApplicationController
def index
@projects = Project.where(status: 'active')
.order(created_at: :desc)
.page(params[:page])
end
end
# app/views/projects/index.html.erb
<% @projects.each do |project| %>
<div>
<h3><%= project.name %></h3>
<p>担当: <%= project.manager.name %></p>
<p>メンバー数: <%= project.members.count %></p>
<p>最新タスク: <%= project.tasks.recent.first&.title %></p>
<p>進捗: <%= project.completion_percentage %>%</p>
</div>
<% end %>"Claude Codeが検出するN+1クエリ:
# 修正前: N+1が4箇所
# 1. project.manager → 各projectごとにSELECT
# 2. project.members.count → 各projectごとにCOUNT
# 3. project.tasks.recent.first → 各projectごとにSELECT
# 4. project.completion_percentage → 内部でtasksを再取得
# 修正後: Eager Loadingで一括取得
@projects = Project.where(status: 'active')
.includes(:manager, :members)
.includes(tasks: :assignee)
.select('projects.*, (
SELECT COUNT(*) FROM tasks
WHERE tasks.project_id = projects.id
AND tasks.status = \'done\'
) * 100.0 / NULLIF((
SELECT COUNT(*) FROM tasks
WHERE tasks.project_id = projects.id
), 0) as cached_completion')
.order(created_at: :desc)
.page(params[:page])ORMが生成するSQLの最適化
Claude Codeは、ORMが生成するSQLを分析し、より効率的なクエリに書き換える提案もできます。
claude "以下はDjangoのORMが生成したSQLです。
手書きSQLで最適化してください。
-- Django ORM生成SQL
SELECT \"app_order\".\"id\", \"app_order\".\"user_id\",
\"app_order\".\"total_amount\", \"app_order\".\"status\",
\"app_order\".\"created_at\"
FROM \"app_order\"
WHERE \"app_order\".\"created_at\" >= '2025-01-01'
ORDER BY \"app_order\".\"created_at\" DESC;
-- 後続のPythonコードでuser_idごとにグルーピングしている
-- 行数: 200万行、取得対象: 50万行"サブクエリとJOINの最適化
相関サブクエリの排除
Claude Codeは、パフォーマンスを低下させる相関サブクエリを検出し、JOINやウィンドウ関数に書き換えます。
claude "以下の相関サブクエリを含むSQLを最適化してください。
SELECT e.name, e.department,
(SELECT MAX(s.amount) FROM sales s WHERE s.employee_id = e.id) as max_sale,
(SELECT COUNT(*) FROM sales s WHERE s.employee_id = e.id AND s.created_at >= '2025-01-01') as recent_sales,
(SELECT AVG(r.score) FROM reviews r WHERE r.employee_id = e.id) as avg_review
FROM employees e
WHERE e.status = 'active'
AND (SELECT COUNT(*) FROM sales s WHERE s.employee_id = e.id) > 10
ORDER BY max_sale DESC;"Claude Codeの最適化結果:
-- 相関サブクエリを排除し、1回のJOINに統合
WITH sale_stats AS (
SELECT employee_id,
MAX(amount) as max_sale,
COUNT(*) as total_sales,
COUNT(*) FILTER (WHERE created_at >= '2025-01-01') as recent_sales
FROM sales
GROUP BY employee_id
HAVING COUNT(*) > 10
),
review_stats AS (
SELECT employee_id,
AVG(score) as avg_review
FROM reviews
GROUP BY employee_id
)
SELECT e.name, e.department,
ss.max_sale, ss.recent_sales,
rs.avg_review
FROM employees e
INNER JOIN sale_stats ss ON e.id = ss.employee_id
LEFT JOIN review_stats rs ON e.id = rs.employee_id
WHERE e.status = 'active'
ORDER BY ss.max_sale DESC;JOINの順序最適化
大規模テーブルのJOINでは、結合順序がパフォーマンスに大きく影響します。
claude "以下の4テーブルJOINを最適化してください。
各テーブルの行数とカーディナリティも考慮してください。
SELECT p.name, c.category_name, s.supplier_name,
SUM(oi.quantity) as total_sold
FROM products p
JOIN categories c ON p.category_id = c.id
JOIN order_items oi ON p.id = oi.product_id
JOIN suppliers s ON p.supplier_id = s.id
WHERE c.is_active = true
AND oi.created_at >= '2025-06-01'
AND s.region = 'tokyo'
GROUP BY p.id, p.name, c.category_name, s.supplier_name
ORDER BY total_sold DESC
LIMIT 50;
-- products: 10万行
-- categories: 200行(is_active=trueは150行)
-- order_items: 5000万行(6ヶ月分は800万行)
-- suppliers: 5000行(tokyo=1200行)"パーティショニングの提案
大規模テーブルの分割戦略
Claude Codeは、テーブルサイズとクエリパターンから最適なパーティショニング戦略を提案します。
claude "以下のテーブルにパーティショニングを導入したいです。
最適な戦略を提案してください。
-- テーブル定義
CREATE TABLE audit_logs (
id BIGSERIAL PRIMARY KEY,
user_id BIGINT NOT NULL,
action VARCHAR(50) NOT NULL,
resource_type VARCHAR(50),
resource_id BIGINT,
metadata JSONB,
ip_address INET,
created_at TIMESTAMP NOT NULL DEFAULT NOW()
);
-- 現在: 20億行、500GB
-- 増加ペース: 月500万行
-- 主なクエリパターン:
-- 1. WHERE created_at BETWEEN ... AND ... (90%)
-- 2. WHERE user_id = ? AND created_at >= ... (8%)
-- 3. WHERE action = ? AND created_at >= ... (2%)
-- 保持期間: 3年(古いデータは削除OK)"Claude Codeの提案例:
-- 月単位のレンジパーティショニング
CREATE TABLE audit_logs (
id BIGSERIAL,
user_id BIGINT NOT NULL,
action VARCHAR(50) NOT NULL,
resource_type VARCHAR(50),
resource_id BIGINT,
metadata JSONB,
ip_address INET,
created_at TIMESTAMP NOT NULL DEFAULT NOW()
) PARTITION BY RANGE (created_at);
-- 自動パーティション作成(月次)
CREATE TABLE audit_logs_2026_01
PARTITION OF audit_logs
FOR VALUES FROM ('2026-01-01') TO ('2026-02-01');
-- 古いパーティションの効率的な削除
-- DROP TABLE audit_logs_2023_01; -- DELETEより100倍高速
-- パーティション内のインデックス
CREATE INDEX idx_audit_user_created ON audit_logs(user_id, created_at);
CREATE INDEX idx_audit_action_created ON audit_logs(action, created_at);バッチ処理のSQL最適化
大量データの効率的な更新
SES現場では、バッチ処理での大量UPDATE/DELETEが問題になることが多いです。
claude "以下のバッチ更新SQLを最適化してください。
現在1000万行の更新に2時間かかっています。
-- 現在のバッチ処理
UPDATE orders
SET status = 'archived',
updated_at = NOW()
WHERE created_at < '2024-01-01'
AND status = 'completed';
-- 対象: 約1000万行"Claude Codeの最適化提案:
-- 分割バッチ処理(ロック競合を回避)
DO $$
DECLARE
batch_size INT := 10000;
affected INT := 1;
total INT := 0;
BEGIN
WHILE affected > 0 LOOP
WITH target AS (
SELECT id FROM orders
WHERE created_at < '2024-01-01'
AND status = 'completed'
LIMIT batch_size
FOR UPDATE SKIP LOCKED
)
UPDATE orders o
SET status = 'archived',
updated_at = NOW()
FROM target t
WHERE o.id = t.id;
GET DIAGNOSTICS affected = ROW_COUNT;
total := total + affected;
RAISE NOTICE 'Updated % rows (total: %)', affected, total;
PERFORM pg_sleep(0.1); -- 他のトランザクションに処理時間を譲る
COMMIT;
END LOOP;
END $$;MySQL固有の最適化テクニック
MySQLの実行計画分析
MySQLとPostgreSQLでは実行計画の読み方が異なります。Claude Codeは両方に対応しています。
claude "以下のMySQL EXPLAIN結果を分析してください。
+----+-------------+-------+------+---------------+------+---------+------+----------+-----------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+----------+-----------------------------+
| 1 | SIMPLE | o | ALL | NULL | NULL | NULL | NULL | 18532940 | Using where; Using filesort |
| 1 | SIMPLE | u | ALL | PRIMARY | NULL | NULL | NULL | 4832100 | Using where; Using join buf |
+----+-------------+-------+------+---------------+------+---------+------+----------+-----------------------------+
MySQL 8.0, InnoDB
テーブル: orders(o), users(u)"MySQLのインデックスヒント
-- Claude Codeが提案するMySQL固有の最適化
-- 1. FORCE INDEXでオプティマイザの誤判断を防ぐ
SELECT /*+ JOIN_ORDER(u, o) */ u.name, COUNT(o.id)
FROM users u FORCE INDEX (idx_users_status)
JOIN orders o FORCE INDEX (idx_orders_user_status)
ON u.id = o.user_id
WHERE u.status = 'active'
AND o.status = 'completed'
GROUP BY u.id;
-- 2. InnoDB Buffer Poolの活用状況確認
SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool%';実践ワークフロー:プロジェクトでの活用
ステップ1: スロークエリログの収集
# PostgreSQLのスロークエリログを収集
claude "pg_stat_statementsから実行時間TOP20のクエリを取得して
分析してください。
SELECT query, calls, total_exec_time, mean_exec_time,
rows, shared_blks_hit, shared_blks_read
FROM pg_stat_statements
ORDER BY total_exec_time DESC
LIMIT 20;"ステップ2: 影響度の高いクエリから最適化
# Claude Codeに優先順位をつけさせる
claude "以下のスロークエリリストを分析して、
最適化の優先順位(影響度 × 改善可能性)を付けてください。
$(cat /tmp/slow_queries.txt)"ステップ3: 段階的な改善
# 各クエリの最適化を段階的に実施
claude "以下のクエリの最適化案を3段階で提示してください。
1. クエリ書き換えのみ(インデックス変更なし)
2. インデックス追加あり
3. テーブル設計の変更あり
$(cat /tmp/target_query.sql)"ステップ4: 本番適用前のレビュー
# 最適化結果のレビューと影響分析
claude "以下の最適化を本番に適用する前に、
リスク分析とロールバック手順を作成してください。
-- 追加するインデックス
$(cat /tmp/new_indexes.sql)
-- 変更するクエリ
$(cat /tmp/optimized_queries.sql)
注意事項:
- 本番テーブルサイズ: orders 200GB, users 50GB
- ピーク時間帯: 9:00-12:00 JST
- メンテナンスウィンドウ: 毎週日曜 2:00-6:00"SES現場でのDB最適化案件
需要と単価
データベース最適化のスキルは、SES市場で高く評価されています。
| 案件タイプ | 月単価目安 | 求められるスキル |
|---|---|---|
| DB性能改善コンサル | 75-90万円 | 実行計画分析、インデックス設計、パーティショニング |
| レガシーDB移行 | 70-85万円 | MySQL→PostgreSQL移行、スキーマ設計 |
| DWH/分析基盤構築 | 80-100万円 | BigQuery、Redshift、パーティション設計 |
| アプリケーションDBA | 65-80万円 | ORM最適化、N+1解消、バッチ処理改善 |
Claude Codeで差別化するポイント
- 分析速度: 数百行のEXPLAIN結果を瞬時に解析できる
- 網羅性: 見落としがちなインデックスの組み合わせも提案
- ドキュメント: 最適化の根拠と効果を自動文書化
- 学習: 実際のクエリ分析を通じてSQL最適化スキルが身につく
面談でアピールできるスキルセット
Claude Codeを活用したSQL最適化経験は、以下のようにアピールできます。
【DB最適化実績】
- PostgreSQL 16環境で月間100億リクエストのシステムを担当
- スロークエリTOP20を分析し、平均応答時間を3.2秒→0.4秒に改善
- カバリングインデックスとパーティショニングで
ストレージI/Oを70%削減
- Claude Codeを活用した分析ワークフローを構築し
最適化サイクルを2週間→3日に短縮まとめ
Claude Codeを活用したSQL最適化は、以下のステップで進めるのが効果的です。
- スロークエリの収集:
pg_stat_statementsやスロークエリログから対象を特定 - 実行計画の分析: EXPLAIN ANALYZEの結果をClaude Codeに解析させる
- 最適化案の生成: インデックス設計・クエリ書き換え・パーティショニングを提案
- 効果の検証: 最適化前後の実行計画を比較して効果を定量化
- 本番適用: リスク分析とロールバック手順を用意して段階的に適用
SQL最適化スキルは、SES市場で高い需要があります。Claude Codeを活用して効率的にスキルを身につけ、高単価案件を獲得しましょう。
関連記事
- Claude Codeデータベース設計ガイドでは、テーブル設計の基礎から正規化まで解説
- Claude Codeデータベース移行ガイドでは、マイグレーション戦略を詳しく紹介
- Claude Code パフォーマンス最適化ガイドでは、アプリケーション全体のパフォーマンス改善を解説





