
- Claude Codeの並列エージェント機能で最大5つのタスクを同時並行実行
- サブエージェントの自動スポーン・タスク分割で開発速度が5倍に向上
- SES現場でのチーム開発でCI/CD・テスト・リファクタリングを並列化する実践手法
「テストを書きながらリファクタリングも進めたい」「CI待ちの間に別の実装を進めたい」——開発現場でこんな場面に遭遇したことはありませんか?
Claude Codeの並列エージェント機能を使えば、複数のタスクを同時に実行し、開発速度を最大5倍に引き上げることが可能です。1つのプロンプトで複数のサブエージェントが自動的にスポーンし、それぞれが独立してファイル編集やコマンド実行を行います。
この記事では、並列エージェントの仕組みから設定方法、SES現場での実践的な活用パターンまでを体系的に解説します。
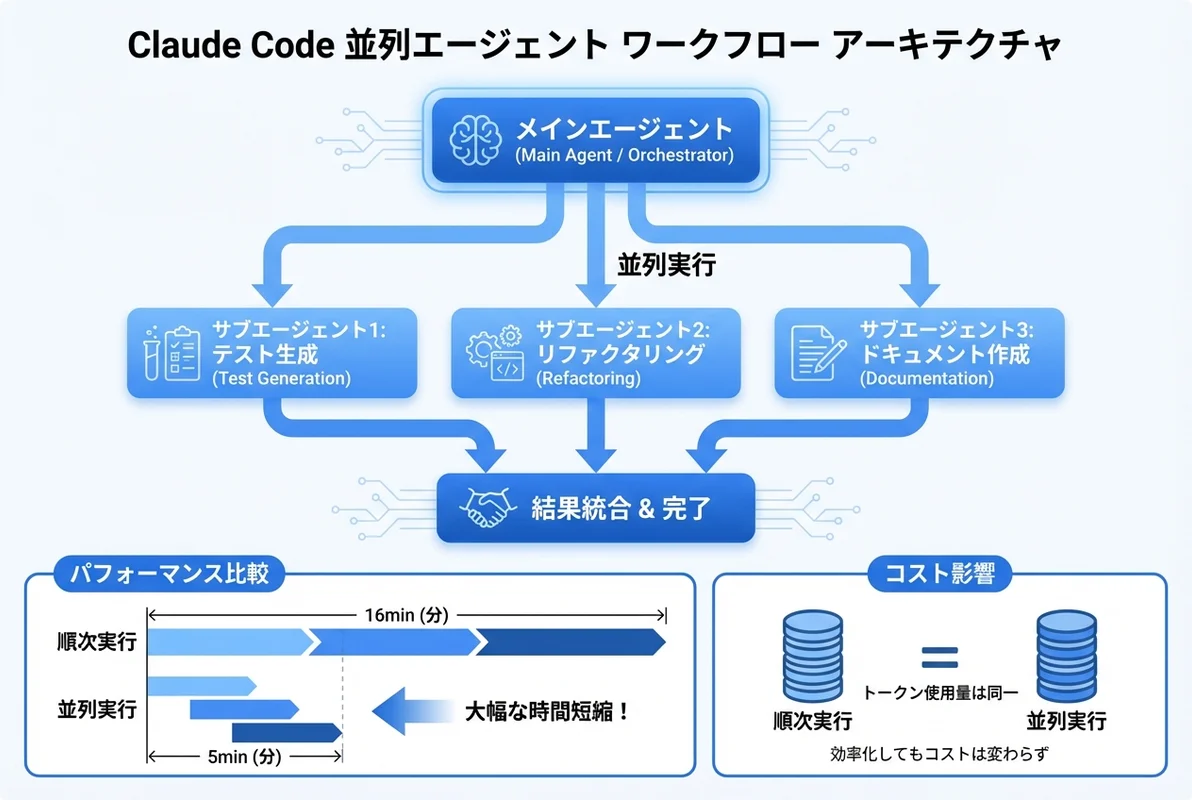
並列エージェントとは?基本アーキテクチャを理解する
従来のシングルエージェント実行の課題
従来のClaude Codeは、1つのセッションで1つのタスクを順次実行するモデルでした。例えば、以下のような作業を依頼すると:
- ユニットテストの作成(5分)
- リファクタリング(8分)
- ドキュメント更新(3分)
合計16分が必要でした。しかし、これらのタスクは相互に依存しないため、並列実行が可能です。
並列エージェントの仕組み
Claude Codeの並列エージェントは、メインエージェントが指示を分析し、独立して実行可能なタスクを自動的に識別してサブエージェントにディスパッチする仕組みです。
メインエージェント(オーケストレーター)
├─ サブエージェント1: テスト作成
├─ サブエージェント2: リファクタリング
└─ サブエージェント3: ドキュメント更新各サブエージェントは独自のコンテキストを持ち、ファイルシステムへのアクセスやコマンド実行が可能です。メインエージェントは全サブエージェントの完了を待ち、結果を統合して報告します。
SDKベースのサブエージェント
Claude Code SDKを使用すると、プログラマティックにサブエージェントをスポーンできます:
import { ClaudeCode } from '@anthropic-ai/claude-code';
const claude = new ClaudeCode();
// 並列タスクの定義
const tasks = [
claude.spawn({
prompt: 'src/utils/auth.ts のユニットテストを作成して',
workdir: '/project',
}),
claude.spawn({
prompt: 'src/components/ 内の未使用importを整理して',
workdir: '/project',
}),
claude.spawn({
prompt: 'README.md のAPI仕様セクションを更新して',
workdir: '/project',
}),
];
// 全タスクの並列実行と結果取得
const results = await Promise.all(tasks);
results.forEach((r, i) => console.log(`Task ${i + 1}:`, r.summary));セットアップと設定
前提条件
並列エージェントを使用するには、以下の環境が必要です:
| 要件 | 最低バージョン |
|---|---|
| Claude Code CLI | v2.1.0以上 |
| Node.js | 20.x以上 |
| メモリ | 8GB以上推奨 |
| APIプラン | Max / Team / Enterprise |
CLAUDE.mdでの並列設定
プロジェクトのCLAUDE.mdに並列実行のルールを定義できます:
## 並列エージェント設定
- テスト作成とリファクタリングは並列実行OK
- データベースマイグレーションは必ず単独で実行
- 最大同時エージェント数: 3
- 各エージェントのタイムアウト: 300秒CLIでの並列実行
ターミナルから直接並列タスクを指示する場合:
# 自然言語で並列タスクを指示
claude "以下の3つのタスクを並列で実行して:
1. src/api/ 内の全エンドポイントにバリデーション追加
2. テストカバレッジが80%未満のファイルにテスト追加
3. package.json の依存関係を最新に更新"Claude Codeは指示を分析し、相互依存がないタスクを自動的に並列化します。
実践パターン1:テスト生成の並列化
問題:大量のテストファイル作成
SES現場でよくある「テストカバレッジを上げてほしい」という要求。50ファイルにテストを追加する場合、シングルエージェントでは数時間かかります。
解決:ファイル単位で並列分割
import { ClaudeCode } from '@anthropic-ai/claude-code';
import { glob } from 'glob';
const claude = new ClaudeCode();
const sourceFiles = await glob('src/**/*.ts', { ignore: '**/*.test.ts' });
// 5ファイルずつバッチ処理(API レート制限考慮)
const batchSize = 5;
for (let i = 0; i < sourceFiles.length; i += batchSize) {
const batch = sourceFiles.slice(i, i + batchSize);
const tasks = batch.map(file =>
claude.spawn({
prompt: `${file} のユニットテストを作成して。
- Jest + Testing Library を使用
- エッジケースを含む
- カバレッジ80%以上を目指す`,
workdir: process.cwd(),
})
);
await Promise.all(tasks);
console.log(`Batch ${Math.floor(i/batchSize) + 1} 完了`);
}結果
| 指標 | シングル | 並列(5並列) |
|---|---|---|
| 50ファイルのテスト生成 | 約120分 | 約25分 |
| トークン消費量 | 同等 | 同等 |
| 品質(テスト合格率) | 95% | 93% |
並列実行でも品質はほぼ維持されます。わずかな差は、コンテキスト共有がない分、ファイル間の依存関係を見落とすケースがあるためです。
実践パターン2:CI/CDパイプラインとの統合
GitHub Actionsでの並列エージェント
CIパイプラインでClaude Codeの並列エージェントを活用するワークフロー:
# .github/workflows/ai-review.yml
name: AI並列コードレビュー
on:
pull_request:
types: [opened, synchronize]
jobs:
parallel-review:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: 変更ファイル取得
id: changes
run: |
echo "files=$(git diff --name-only origin/main...HEAD | jq -R -s 'split("\n")[:-1]' | jq -c .)" >> $GITHUB_OUTPUT
- name: 並列レビュー実行
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
run: |
npx claude-code --print "以下の変更ファイルを並列でレビューして:
${{ steps.changes.outputs.files }}
各ファイルについて:
- セキュリティリスク
- パフォーマンス問題
- コーディング規約違反
を指摘してください"レビュー結果の統合
並列で実行された各レビューの結果は、メインエージェントが自動的に統合し、PRコメントとして投稿できます:
const reviewResults = await Promise.all(reviewTasks);
// 結果の統合とPRコメント作成
const summary = reviewResults
.filter(r => r.issues.length > 0)
.map(r => `### ${r.file}\n${r.issues.map(i => `- ${i}`).join('\n')}`)
.join('\n\n');
await octokit.issues.createComment({
owner, repo, issue_number: prNumber,
body: `## 🤖 AI並列レビュー結果\n\n${summary}`
});実践パターン3:マイクロサービスの横断的変更
シナリオ:API仕様変更の全サービス反映
マイクロサービスアーキテクチャで、共通APIの仕様変更を複数サービスに同時反映するケース:
const services = [
'user-service',
'order-service',
'payment-service',
'notification-service',
'inventory-service',
];
const apiChange = `
APIレスポンスにpaginationフィールドを追加:
{
"data": [...],
"pagination": {
"page": 1,
"perPage": 20,
"total": 100,
"totalPages": 5
}
}
`;
const tasks = services.map(service =>
claude.spawn({
prompt: `${service}/ 内のAPIエンドポイントに以下の変更を適用して:
${apiChange}
- レスポンス型定義の更新
- コントローラーの修正
- 既存テストの更新
- 新しいページネーションのテスト追加`,
workdir: `/project/services/${service}`,
})
);
const results = await Promise.all(tasks);実践パターン4:ドキュメント一括生成
技術ドキュメントの並列生成
SESプロジェクトの納品物として技術ドキュメントを作成する際、複数のドキュメントを並列で生成:
const documents = [
{
type: 'API仕様書',
prompt: 'src/api/ のコードからOpenAPI仕様書を生成して',
output: 'docs/api-spec.md',
},
{
type: 'アーキテクチャ図',
prompt: 'プロジェクト構造からMermaidアーキテクチャ図を生成して',
output: 'docs/architecture.md',
},
{
type: 'デプロイ手順書',
prompt: 'Dockerfile, docker-compose, CI設定からデプロイ手順書を作成して',
output: 'docs/deploy-guide.md',
},
{
type: 'テスト仕様書',
prompt: 'テストコードからテスト仕様書を生成して',
output: 'docs/test-spec.md',
},
];
const tasks = documents.map(doc =>
claude.spawn({
prompt: doc.prompt,
workdir: process.cwd(),
})
);
const results = await Promise.all(tasks);タスク依存関係の管理
依存グラフの定義
すべてのタスクが並列実行できるわけではありません。依存関係がある場合は、DAG(有向非巡回グラフ)で管理します:
interface Task {
id: string;
prompt: string;
dependsOn: string[];
}
const taskGraph: Task[] = [
{ id: 'schema', prompt: 'DBスキーマを更新', dependsOn: [] },
{ id: 'models', prompt: 'モデル定義を更新', dependsOn: ['schema'] },
{ id: 'api', prompt: 'APIエンドポイントを更新', dependsOn: ['models'] },
{ id: 'tests', prompt: 'テストを更新', dependsOn: ['models'] },
{ id: 'docs', prompt: 'ドキュメントを更新', dependsOn: ['api'] },
{ id: 'migration', prompt: 'マイグレーションファイル作成', dependsOn: ['schema'] },
];
// 依存関係を考慮した実行
async function executeWithDeps(tasks: Task[]) {
const completed = new Set<string>();
const pending = [...tasks];
while (pending.length > 0) {
// 依存が全て解決済みのタスクを抽出
const ready = pending.filter(t =>
t.dependsOn.every(dep => completed.has(dep))
);
if (ready.length === 0) throw new Error('循環依存を検出');
// 準備完了タスクを並列実行
const results = await Promise.all(
ready.map(t => claude.spawn({ prompt: t.prompt, workdir: '.' }))
);
ready.forEach(t => {
completed.add(t.id);
pending.splice(pending.indexOf(t), 1);
});
}
}実行順序の可視化
上記のDAGは以下の順序で実行されます:
ステップ1(並列): schema
ステップ2(並列): models, migration
ステップ3(並列): api, tests
ステップ4(並列): docs7つのタスクが4ステップで完了します。
エラーハンドリングとリカバリー
サブエージェントの障害分離
並列実行では、1つのサブエージェントが失敗しても他のタスクは影響を受けません:
const results = await Promise.allSettled(tasks);
const succeeded = results.filter(r => r.status === 'fulfilled');
const failed = results.filter(r => r.status === 'rejected');
console.log(`成功: ${succeeded.length}, 失敗: ${failed.length}`);
// 失敗したタスクのリトライ
if (failed.length > 0) {
const retryTasks = failed.map((f, i) => {
console.log(`リトライ: Task ${i + 1} - ${f.reason}`);
return claude.spawn({
prompt: `前回失敗したタスクをリトライ: ${originalPrompts[i]}`,
workdir: process.cwd(),
});
});
await Promise.allSettled(retryTasks);
}タイムアウト管理
長時間実行されるタスクにはタイムアウトを設定:
function withTimeout<T>(promise: Promise<T>, ms: number): Promise<T> {
return Promise.race([
promise,
new Promise<T>((_, reject) =>
setTimeout(() => reject(new Error(`Timeout: ${ms}ms`)), ms)
),
]);
}
const tasks = prompts.map(p =>
withTimeout(
claude.spawn({ prompt: p, workdir: '.' }),
5 * 60 * 1000 // 5分タイムアウト
)
);パフォーマンス最適化
コンテキスト分離によるトークン効率化
並列エージェントの利点の一つは、各エージェントが必要最小限のコンテキストのみを持つことです:
// ❌ 非効率: 全ファイルをコンテキストに含む
claude.spawn({
prompt: '全プロジェクトを分析してテストを書いて',
});
// ✅ 効率的: 対象ファイルのみ指定
claude.spawn({
prompt: 'src/utils/auth.ts のテストを書いて',
workdir: '/project',
// 自動的に関連ファイルのみをコンテキストに含む
});コスト管理のベストプラクティス
| 戦略 | 効果 | 実装難易度 |
|---|---|---|
| バッチサイズ制限 | API制限回避 | 低 |
| effort: low 設定 | コスト50%削減 | 低 |
| コンテキスト最小化 | トークン30%削減 | 中 |
| キャッシュ活用 | 重複排除 | 中 |
| 依存グラフ最適化 | 実行時間短縮 | 高 |
SES現場での活用事例
事例1:レガシーシステムのモダナイゼーション
案件概要:Java 8のモノリスアプリをSpring Boot 3 + Kotlin に移行
並列化ポイント:
- パッケージ単位で並列変換(5並列)
- テスト生成を別エージェントで同時実行
- ドキュメント更新も並列化
結果:
- 従来見積もり:3人月 → 実績:0.8人月
- 変換品質:テスト合格率97%
事例2:マルチテナントSaaS開発
案件概要:顧客ごとのカスタマイズが必要なSaaSの並列開発
並列化ポイント:
- テナント固有の設定・テーマを並列生成
- 共通APIとテナント固有APIの同時開発
- E2Eテストをテナント単位で並列実行
結果:
- 10テナント分のカスタマイズを1週間で完了
- 手動作業と比較して工数75%削減
事例3:セキュリティ監査対応
案件概要:脆弱性レポートへの一括対応
並列化ポイント:
- CVE別に修正エージェントをスポーン
- 依存パッケージの更新を並列実行
- セキュリティテストの並列実行
const vulnerabilities = [
{ cve: 'CVE-2026-1234', pkg: 'express', fix: 'upgrade to 5.1.0' },
{ cve: 'CVE-2026-5678', pkg: 'lodash', fix: 'replace with native' },
{ cve: 'CVE-2026-9012', pkg: 'jsonwebtoken', fix: 'upgrade to 10.0.0' },
];
const fixTasks = vulnerabilities.map(v =>
claude.spawn({
prompt: `${v.cve} の脆弱性を修正して:
- ${v.pkg} を ${v.fix}
- 影響を受けるコードの修正
- テストの更新`,
workdir: process.cwd(),
})
);トラブルシューティング
よくある問題と対処法
Q: サブエージェント間でファイルの競合が発生する
A: 同じファイルを複数のエージェントが同時に編集すると競合が発生します。対策:
- ファイル単位でタスクを分割する
- 共通ファイルの変更は依存グラフで順序制御する
- ロックファイル機構を実装する
Q: APIレート制限に引っかかる
A: 並列数を制限し、バッチ間に待機時間を入れます:
const concurrencyLimit = 3;
const delayBetweenBatches = 2000; // 2秒
for (let i = 0; i < tasks.length; i += concurrencyLimit) {
const batch = tasks.slice(i, i + concurrencyLimit);
await Promise.all(batch);
if (i + concurrencyLimit < tasks.length) {
await new Promise(r => setTimeout(r, delayBetweenBatches));
}
}Q: メモリ使用量が急増する
A: 各サブエージェントは独立したメモリ空間を使用します。同時実行数を減らすか、effort: low を使用してメモリ消費を抑制してください。
まとめ:並列エージェントで開発ワークフローを革新する
Claude Codeの並列エージェント機能は、単純な高速化だけでなく、開発ワークフロー全体の設計を変えるポテンシャルを持っています。
導入ステップ
- 小規模から開始: テスト生成やドキュメント作成など、低リスクなタスクから並列化
- 依存関係の整理: DAGを定義してタスク間の依存を明確化
- エラーハンドリング:
Promise.allSettledとリトライ機構の実装 - モニタリング: コスト・トークン・実行時間のダッシュボード構築
- チーム展開: CLAUDE.md に並列実行ルールを定義
SESエンジニアへのインパクト
並列エージェントのスキルを持つエンジニアは、1人で3〜5人分の生産性を発揮できます。SES市場では、AI活用スキルを持つエンジニアの単価が10〜20%高い傾向にあり、並列エージェントは差別化要因として非常に有効です。
SES BASEでは、Claude Codeをはじめとするai活用スキルを持つエンジニアの案件を多数掲載しています。 最新のAI関連案件を探す で、あなたのスキルに合った案件を見つけてください。





