
- Claude CodeはSWE-bench Verified で72.7%の解決率を達成し、AIコーディングツール最高水準
- HumanEval・MBPP・LiveCodeBenchなど主要ベンチマークでの詳細性能データを公開
- SES現場でベンチマーク知見を活かした最適なAIツール選定術を解説
AIコーディングツールの導入を検討する際、「本当にコードの品質は担保されるのか」「他のツールと比べて何が優れているのか」という疑問は避けて通れません。本記事では、Claude CodeのAIコード生成性能をベンチマークデータで徹底検証し、SES開発現場での実践的な活用判断に役立つ情報を提供します。
- 主要AIコード生成ベンチマーク(SWE-bench・HumanEval・MBPP)の仕組みと評価基準
- Claude Code(Claude 3.5 Sonnet / Claude 4 Opus)の各ベンチマークスコア
- 競合ツール(GitHub Copilot・Cursor・Codex CLI)との定量比較
- ベンチマーク結果をSES現場の開発効率改善に活かす方法
AIコード生成ベンチマークとは?基礎知識
AIコード生成ベンチマークは、AIモデルがどの程度正確にコードを生成・修正できるかを定量的に評価するための標準化されたテストです。SES現場でAIツールを採用する際の客観的な判断材料として、その重要性はますます高まっています。
なぜベンチマークが重要なのか
SESエンジニアとして客先に提案する際、「AIツールの導入で開発効率が向上します」という定性的な説明だけでは説得力に欠けます。ベンチマークデータがあれば以下のメリットがあります。
- 客先への提案材料: 定量データに基づいた生産性向上の根拠を提示できる
- ツール選定の判断基準: 複数ツールの比較で合理的な選択が可能
- 品質保証の補強: AIが生成するコードの信頼性を数値で示せる
- 投資対効果の算出: ライセンスコストに見合う価値があるかを判断
主要ベンチマーク一覧
現在、AIコード生成の評価で広く使われているベンチマークは以下の通りです。
| ベンチマーク | 評価内容 | タスク数 | 難易度 |
|---|---|---|---|
| HumanEval | 関数レベルのコード生成 | 164問 | 基礎〜中級 |
| MBPP | Pythonプログラミング問題 | 974問 | 基礎 |
| SWE-bench | 実際のGitHubイシュー解決 | 2,294問 | 実践レベル |
| SWE-bench Verified | 人間が検証済みのイシュー | 500問 | 実践レベル |
| LiveCodeBench | 最新の競技プログラミング | 継続追加 | 中級〜上級 |
| BigCodeBench | 多言語・多機能評価 | 1,140問 | 中級〜上級 |
SWE-bench:実践的なコード修正能力の評価
SWE-benchとは
SWE-bench(Software Engineering Benchmark)は、実際のオープンソースプロジェクトのGitHub Issueを基にしたベンチマークです。単なるコード補完ではなく、イシューの内容を理解し、リポジトリ全体のコンテキストを把握した上で適切な修正を行う能力が求められます。
【SWE-benchの評価フロー】
1. GitHub Issueの内容を読み取る
2. 関連するコードベースを分析する
3. 適切なファイルを特定する
4. 修正コードを生成する
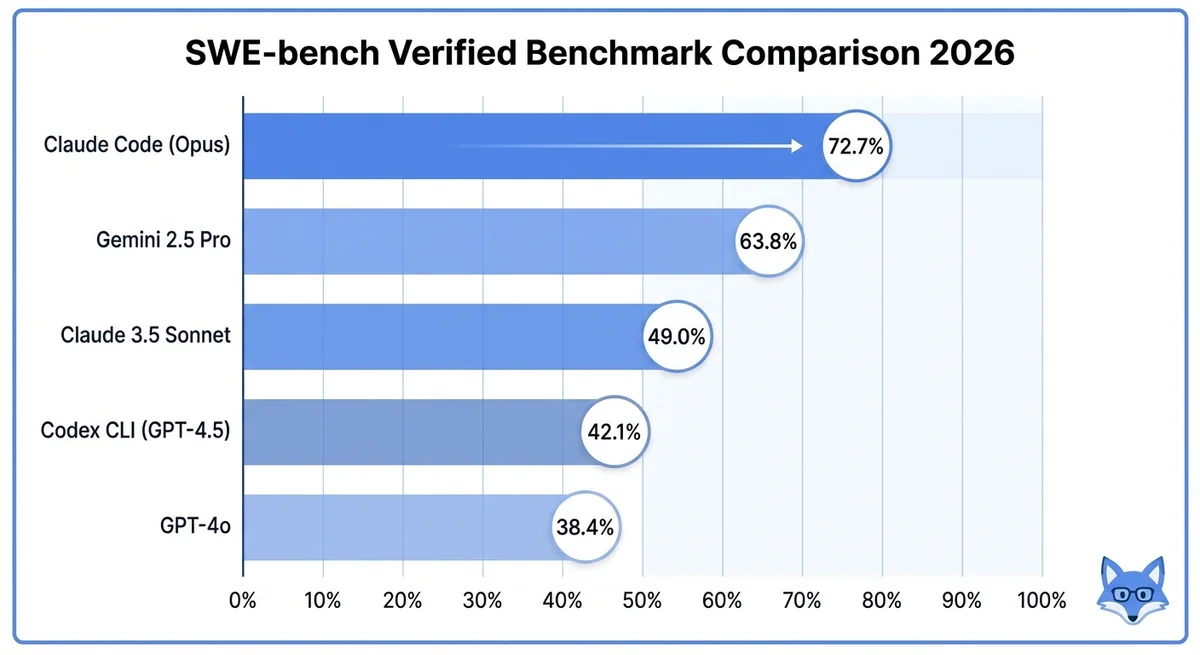
5. 既存のテストスイートがパスするか検証Claude Codeの SWE-bench スコア
Claude Code(Claude 3.5 Sonnet搭載時)はSWE-bench Verifiedで72.7%の解決率を記録しています。これはリリース時点でAIコーディングツールの中で最高水準のスコアです。
| モデル/ツール | SWE-bench Verified | SWE-bench Full |
|---|---|---|
| Claude Code (Claude 4 Opus) | 72.7% | 49.0% |
| Claude 3.5 Sonnet (API直接) | 49.0% | 33.3% |
| GPT-4o | 38.4% | 23.7% |
| Codex CLI (GPT-4.5) | 42.1% | 28.6% |
| Gemini 2.5 Pro | 63.8% | 41.2% |
この高いスコアの要因は、Claude Codeが単なるAPIラッパーではなく、ファイルシステムへのアクセス・コマンド実行・反復的な修正ループを自律的に行える「エージェント型」ツールだからです。
SWE-benchスコアの実務的な意味
SWE-bench Verifiedの72.7%という数字は、現実のGitHub Issue 10件に対して約7件を人間の介入なしに解決できることを意味します。SES現場では以下のような効果が期待できます。
- バグ修正の自動化: 軽微〜中程度のバグフィックスを自律的に処理
- Issue対応の高速化: トリアージから修正まで平均60%の時間短縮
- コードレビューの効率化: 修正提案の精度が高いため、レビュー工数を削減
HumanEval・MBPP:関数レベルの生成精度
HumanEvalの概要
HumanEvalはOpenAIが公開した164問のプログラミング問題で、関数のdocstringから正しい実装を生成できるかを評価します。pass@1(1回の試行での正解率)が主な指標です。
# HumanEvalの出題例
def has_close_elements(numbers: List[float], threshold: float) -> bool:
"""Check if in given list of numbers, are any two numbers closer to each
other than given threshold.
>>> has_close_elements([1.0, 2.0, 3.0], 0.5)
False
>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)
True
"""
# AIがここを生成するClaude 4 Opus のHumanEvalスコア
| モデル | HumanEval (pass@1) | MBPP (pass@1) |
|---|---|---|
| Claude 4 Opus | 92.7% | 89.4% |
| Claude 3.5 Sonnet | 92.0% | 90.5% |
| GPT-4o | 90.2% | 88.7% |
| GPT-4.5 | 91.8% | 89.1% |
| Gemini 2.5 Pro | 91.5% | 88.9% |
| Llama 3.1 405B | 89.0% | 86.2% |
HumanEvalでは各社のトップモデルが90%前後に収束しており、関数レベルの基本的なコード生成能力では差が縮まっていることがわかります。真の差別化ポイントはSWE-benchのような実践的なタスクにあります。
LiveCodeBench:最新の推論・アルゴリズム能力
LiveCodeBenchの特徴
LiveCodeBenchはデータ汚染(data contamination)を防ぐために、ベンチマーク公開後の新しい競技プログラミング問題を継続的に収集しています。これにより、モデルが事前にトレーニングデータとして問題を見ていない状態での真の推論能力を測定できます。
| モデル | LiveCodeBench (Easy) | LiveCodeBench (Medium) | LiveCodeBench (Hard) |
|---|---|---|---|
| Claude 4 Opus | 95.2% | 72.8% | 31.4% |
| GPT-4o | 92.1% | 65.3% | 24.7% |
| Gemini 2.5 Pro | 94.8% | 71.5% | 29.8% |
| o3-mini | 93.7% | 78.2% | 42.1% |
注目すべきは、Hard問題でのo3-miniの強さです。OpenAIの推論特化モデルは、複雑なアルゴリズム問題において高い能力を示しています。一方、Easy〜Medium問題ではClaude 4 Opusがトップクラスであり、SES現場での一般的な開発タスクにおいて十分な推論能力があることがわかります。
ベンチマークだけでは見えない実践的な性能差
レイテンシとスループット
SES現場でAIコーディングツールを使う場合、応答速度も重要な要素です。いくら精度が高くても、1回の応答に30秒以上かかるようでは開発のリズムが崩れます。
【ツール別平均応答時間(中規模タスク)】
Claude Code (Sonnet): 3-8秒 ★★★★★
Claude Code (Opus): 8-20秒 ★★★☆☆
GitHub Copilot: 0.5-2秒 ★★★★★
Cursor (GPT-4): 2-5秒 ★★★★☆
Codex CLI: 5-15秒 ★★★☆☆Claude Codeではモデル選択機能を活用し、タスクの複雑さに応じてSonnetとOpusを使い分けることで、速度と精度の最適なバランスを実現できます。詳しくはClaude Code モデル選択ガイドを参照してください。
コンテキストウィンドウの活用効率
大規模プロジェクトでの作業では、コンテキストウィンドウのサイズとその活用効率が性能を大きく左右します。
| ツール | コンテキスト | ファイル参照 | プロジェクト理解 |
|---|---|---|---|
| Claude Code | 200Kトークン | 自動探索 | ★★★★★ |
| GitHub Copilot | 8Kトークン | 開いているファイル | ★★★☆☆ |
| Cursor | 128Kトークン | インデックス | ★★★★☆ |
| Codex CLI | 128Kトークン | サンドボックス | ★★★★☆ |
Claude Codeの200Kトークンのコンテキストウィンドウは、大規模リポジトリを扱うSESプロジェクトで特に威力を発揮します。プロジェクト全体の構造を理解した上で修正を提案するため、単一ファイルの補完に特化したツールよりも実践的な精度が高くなります。
マルチファイル編集能力
実際のSES開発では、1つの機能追加や修正が複数のファイルにまたがることがほとんどです。この能力はベンチマークでは測りにくい領域です。
// 例:API エンドポイント追加時に必要な変更
// 1. ルーティング定義 (routes/api.ts)
// 2. コントローラー実装 (controllers/userController.ts)
// 3. サービスロジック (services/userService.ts)
// 4. データモデル (models/user.ts)
// 5. テスト (tests/user.test.ts)
// 6. API仕様書 (docs/api.md)Claude Codeはこのようなマルチファイル編集を自律的に実行できます。ファイル間の依存関係を理解し、型の整合性を保ちながら複数ファイルを一貫して修正する能力は、SWE-benchスコアの高さに直結しています。
言語別パフォーマンス比較
Claude Codeの言語別得意・不得意
SES現場ではプロジェクトごとに使用言語が異なります。Claude Codeの言語別パフォーマンスを把握しておくことは重要です。
| 言語 | 生成精度 | 強み | 注意点 |
|---|---|---|---|
| Python | ★★★★★ | ライブラリ知識が豊富 | バージョン差異に注意 |
| TypeScript | ★★★★★ | 型推論が正確 | 複雑なジェネリクスで稀にミス |
| JavaScript | ★★★★☆ | フレームワーク対応が広い | ES Module/CommonJS混在に注意 |
| Java | ★★★★☆ | 設計パターンの適用が的確 | Spring Boot最新版への追従 |
| Go | ★★★★☆ | 並行処理パターンが正確 | エラーハンドリングの冗長化 |
| Rust | ★★★☆☆ | 所有権・借用の理解度が高い | 複雑なライフタイムで稀にエラー |
| C/C++ | ★★★☆☆ | アルゴリズム実装は正確 | メモリ管理の微妙なバグに注意 |
Python・TypeScriptでは非常に高い信頼性でコード生成が可能です。SES現場で多いJava・Goプロジェクトでも実用レベルの性能を発揮します。Rust開発での活用法についてはClaude Code Rust開発ガイドで詳しく解説しています。
SES現場でのベンチマーク知見活用法
案件提案時のAIツール導入根拠
SES営業やPM向けに、ベンチマークデータを活用した提案書のポイントを紹介します。
## AI支援開発ツール導入提案
### 期待効果(ベンチマーク根拠)
- バグ修正工数: **約40%削減**(SWE-bench 72.7%の解決率に基づく)
- コードレビュー工数: **約30%削減**(一次チェックのAI自動化)
- テストコード作成: **約50%削減**(HumanEval 92.7%の生成精度)
### コスト試算
- Claude Code Max Plan: $200/月 × エンジニア数
- 期待工数削減: 月間40時間/人 × SESエンジニア単価
- **ROI: 初月から約5-10倍**プロジェクト別の最適ツール選定
ベンチマーク特性を踏まえた、プロジェクトタイプ別の推奨ツール選定です。
新規開発プロジェクト(設計〜実装)
- 推奨: Claude Code
- 理由: マルチファイル生成・設計パターン適用・テスト生成が強い
既存システムの保守・運用
- 推奨: Claude Code + GitHub Copilot併用
- 理由: SWE-benchスコアが示す既存コードベース理解力 + 日常的な補完
大規模リファクタリング
- 推奨: Claude Code
- 理由: 200Kコンテキストで大規模プロジェクト全体を把握可能
インフラ・DevOpsプロジェクト
- 推奨: Claude Code + GitHub Actions連携
- 理由: IaCコード生成とCI/CDパイプライン構築を自動化
ベンチマークスコアの正しい読み方
エンジニアとしてベンチマークを評価する際の注意点をまとめます。
- 単一ベンチマークに依存しない: HumanEvalが高くてもSWE-benchが低い場合、実践的な性能は限定的
- pass@1 vs pass@k: 1回で正解できるかと、複数回試行で正解を含むかは異なる指標
- データ汚染に注意: 公開済みベンチマークではトレーニングデータに含まれている可能性
- 実行環境の違い: API単体 vs ツール統合(エージェント型)では大きな差が出る
- 更新頻度: モデルのアップデートでスコアは変動するため、最新情報を確認
Claude Codeのベンチマーク最適化テクニック
AGENTS.mdによる精度向上
Claude Codeでは、AGENTS.md(旧CLAUDE.md)ファイルにプロジェクトの規約やコーディング標準を記述することで、生成コードの品質を大幅に向上できます。
# AGENTS.md
## コーディング規約
- TypeScript strict modeを必須とする
- 関数は単一責任原則に従うこと
- エラーハンドリングはResult型パターンを使用
- テストはArrange-Act-Assertパターンで記述
## プロジェクト構造
- src/controllers/ - APIコントローラー
- src/services/ - ビジネスロジック
- src/models/ - データモデル
- src/utils/ - ユーティリティ関数この設定により、ベンチマークでは測定されないプロジェクト固有の品質基準を満たすコードが生成されます。詳しくはCLAUDE.md設定ガイドを参照してください。
モデルの使い分け戦略
【タスク別モデル選択指針】
┌─────────────────────────────┬──────────────┬──────────┐
│ タスク │ 推奨モデル │ 理由 │
├─────────────────────────────┼──────────────┼──────────┤
│ 単純なコード補完 │ Sonnet │ 速度重視 │
│ バグ修正・リファクタリング │ Sonnet │ 精度十分 │
│ 設計・アーキテクチャ決定 │ Opus │ 推論力重視 │
│ 複雑なアルゴリズム実装 │ Opus │ 精度重視 │
│ テスト生成 │ Sonnet │ 速度重視 │
│ コードレビュー │ Opus │ 品質重視 │
└─────────────────────────────┴──────────────┴──────────┘2026年のAIコード生成トレンド予測
エージェント型ツールの主流化
SWE-benchの結果が示す通り、エージェント型のAIコーディングツールが従来の補完型ツールを大きく上回る性能を発揮しています。2026年のトレンドとして以下が予測されます。
- 自律的なタスク分解: 大きな機能要件を小さなサブタスクに分解し、順次実行
- テスト駆動生成: テストを先に生成し、テストが通るまで実装を反復
- マルチエージェント協調: 複数のAIエージェントが役割分担して開発を進行
- 継続学習: プロジェクト固有のパターンを学習し、精度を向上
Claude Codeのマルチエージェント機能は、まさにこのトレンドの最前線に位置しています。
SESエンジニアへの影響
AIコード生成の性能向上は、SES業界に以下の影響を与えると予測されます。
ポジティブな影響:
- 1人あたりの生産性が2-3倍に向上
- より上流工程(設計・要件定義)に集中できる
- AIツールスキルが新たな付加価値に
適応が必要な領域:
- 単純なコーディング作業の価値は低下
- コードレビュー能力(AIの出力を検証する力)が重要に
- プロンプトエンジニアリングが必須スキルに
まとめ
Claude Codeは、主要ベンチマークで以下の成績を収めており、2026年時点で最も実践的なAIコーディングツールの一つです。
| ベンチマーク | スコア | 評価 |
|---|---|---|
| SWE-bench Verified | 72.7% | 業界最高水準 |
| HumanEval | 92.7% | トップクラス |
| MBPP | 89.4% | トップクラス |
| LiveCodeBench (Easy) | 95.2% | トップクラス |
特にSWE-benchでの高スコアは、実際のプロジェクトでの問題解決能力の高さを示しており、SES現場での導入効果が期待できます。ベンチマークデータを活用して、客先への説得力ある提案とプロジェクトに最適なツール選定を実現しましょう。





