
- Lambda Durable Functionsは自動チェックポイントで長時間処理を安全に実行
- 一時停止/再開機能でAI推論パイプラインやバッチジョブに最適
- Lambda Managed Instancesとの組み合わせでGPUワークロードも対応
「Lambda Durable Functionsって従来のLambdaと何が違うの?」「Step Functionsとの使い分けは?」「AI推論パイプラインをサーバーレスで構築したい」
AWS Lambda Durable Functionsは、従来のLambdaの15分制限を超えて長時間処理を安全に実行できる新機能です。 自動チェックポイントにより、処理の途中で中断しても再開可能で、AI推論パイプラインや大規模バッチジョブに最適なソリューションです。
この記事では、AWS完全攻略シリーズEp.51として、Durable Functionsの基礎から実践的な活用法までを解説します。
- Lambda Durable Functionsの仕組みとアーキテクチャ
- 主要ユースケースとStep Functionsとの使い分け
- AI推論パイプラインの構築チュートリアル
- コスト最適化と従来構成との比較
Lambda Durable Functionsとは?従来のLambdaとの違い
サーバーレスの課題を解決する新アプローチ
従来のAWS Lambdaには最大15分のタイムアウト制限がありました。この制限は、以下のようなユースケースで大きな障壁となっていました。
- AI/MLモデルの推論(大量データ処理)
- 動画のトランスコーディング
- 大規模データのETL処理
- 複雑なワークフローの逐次実行
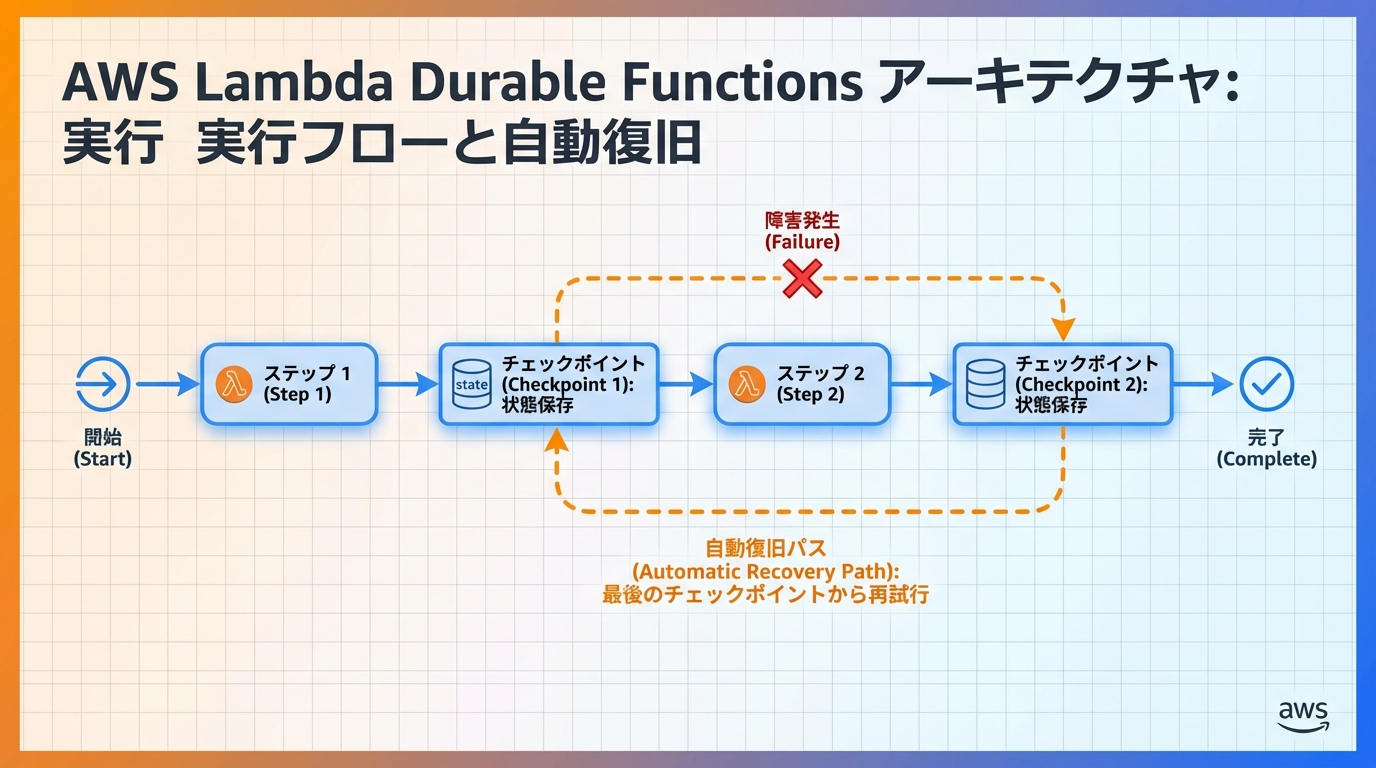
Lambda Durable Functionsは、自動チェックポイントと一時停止/再開のメカニズムにより、これらの課題を根本的に解決します。
| 比較項目 | 従来のLambda | Lambda Durable Functions |
|---|---|---|
| 最大実行時間 | 15分 | 最大24時間(設定次第) |
| チェックポイント | なし | 自動 |
| 障害復旧 | 最初から再実行 | 最後のチェックポイントから再開 |
| 状態管理 | なし | 自動永続化 |
| メモリ | 最大10GB | 最大10GB |
Azure Durable Functionsとの比較
AWSのDurable Functionsは、Microsoft Azureの同名機能にインスパイアされています。
AWS公式ドキュメントによると、AWSは「よりシンプルなAPI」と「自動チェックポイント」で差別化を図っています。
| 比較項目 | AWS Lambda Durable | Azure Durable Functions |
|---|---|---|
| チェックポイント | 自動 | 手動(OrchestrationContext) |
| サポート言語 | Python, Node.js, Java | C#, JavaScript, Python, Java |
| 状態ストア | DynamoDB(自動) | Azure Storage |
| GPU対応 | あり(Managed Instances連携) | なし |
Durable Functionsのアーキテクチャと仕組み
自動チェックポイントの仕組み
Durable Functionsは、関数実行中に自動的にチェックポイントを作成します。
import aws_lambda_durable as durable
@durable.function
def process_data(event, context):
# ステップ1: データ取得
data = fetch_large_dataset(event['source'])
# → ここで自動チェックポイント
# ステップ2: AI推論
results = run_inference(data)
# → ここで自動チェックポイント
# ステップ3: 結果保存
save_results(results)
return {"status": "completed", "count": len(results)}チェックポイントは以下のタイミングで自動作成されます:
await/非同期呼び出しの前後durable.checkpoint()の明示的な呼び出し- 外部サービスへのAPI呼び出しの前後
- 設定した間隔(デフォルト: 5分)
一時停止/再開のメカニズム
実行中の関数が中断された場合(インスタンスのリサイクル、エラー等)、最後のチェックポイントから自動的に再開されます。
[実行開始] → [Step1完了] → [チェックポイント①] → [Step2実行中]
↓
[中断発生]
↓
[チェックポイント①から再開]
↓
[Step2再実行]耐障害性の実現方法
Durable Functionsは、チェックポイントデータをDynamoDBに自動保存します。これにより:
- アベイラビリティゾーン障害に対する耐性
- インスタンス障害からの自動復旧
- デプロイ中の実行継続が可能
主要ユースケース
AI推論パイプライン(長時間処理)
大量のドキュメントをAIで分析するパイプラインの例:
@durable.function
def ai_analysis_pipeline(event, context):
documents = event['documents'] # 10,000件のドキュメント
results = []
for batch in chunks(documents, 100):
# 各バッチ処理後に自動チェックポイント
batch_results = await bedrock.invoke_batch(batch)
results.extend(batch_results)
return aggregate_results(results)AWS Bedrock入門ガイドと組み合わせることで、エンタープライズ規模のAI処理を構築できます。
大規模バッチジョブ
数百万レコードのデータ処理も、チェックポイント付きで安全に実行できます。
マルチステップワークフロー
複数のサービスを跨ぐワークフローを単一の関数で記述できます。
Step Functionsとの使い分け
| ユースケース | Durable Functions | Step Functions |
|---|---|---|
| 長時間の単一処理 | ✅ 最適 | △ オーバースペック |
| 複雑な分岐ロジック | △ コードで記述 | ✅ ビジュアルワークフロー |
| 状態管理 | 自動 | ASL定義が必要 |
| エラーハンドリング | try/catch | Catch/Retry |
| コスト | Lambda料金のみ | 状態遷移ごとに課金 |
Step Functionsガイドとの比較も参考にしてください。
実装チュートリアル:AI推論パイプラインの構築
環境構築とIAM設定
# SAMテンプレートでプロジェクト作成
sam init --runtime python3.12 --app-template durable-function
# IAMポリシー(DynamoDBアクセスが自動追加される)# template.yaml
Resources:
AiPipelineFunction:
Type: AWS::Serverless::Function
Properties:
Handler: app.handler
Runtime: python3.12
Timeout: 86400 # 24時間
MemorySize: 4096
Policies:
- DurableFunctionPolicy # 自動チェックポイント用
- BedrockInvokePolicyDurable Functionの定義
# app.py
import aws_lambda_durable as durable
from aws_lambda_durable import checkpoint
@durable.function(
checkpoint_interval=300, # 5分ごと
max_retries=3
)
def handler(event, context):
# データ取得
s3_objects = list_s3_objects(event['bucket'], event['prefix'])
checkpoint("data_listed")
# バッチ推論
results = []
for i, batch in enumerate(chunks(s3_objects, 50)):
batch_result = process_batch(batch)
results.extend(batch_result)
checkpoint(f"batch_{i}_completed")
# 結果集約・保存
summary = aggregate(results)
save_to_s3(summary, event['output_bucket'])
return {"status": "success", "processed": len(s3_objects)}チェックポイント設計のベストプラクティス
- 高コストな処理の前後にチェックポイントを配置
- 外部API呼び出しの前にチェックポイントを設定
- チェックポイントのデータサイズを最小化(大きなデータはS3に退避)
- 冪等性を確保(再実行しても同じ結果になるように設計)
Lambda Managed Instancesとの組み合わせ
GPU対応ワークロードの実現
Lambda Managed Instancesを使うと、Lambda上でGPUワークロードを実行できます。
Resources:
GpuInferenceFunction:
Type: AWS::Serverless::Function
Properties:
Handler: app.handler
Runtime: python3.12
ManagedInstance:
InstanceType: g5.xlarge # NVIDIA A10G GPU
Durable: true # Durable Functions有効化EC2レベルのカスタマイズ × Lambda運用の簡素さ
Managed Instancesの利点は、EC2のようなインスタンスカスタマイズとLambdaのようなサーバーレス運用を両立できることです。
Lambda入門ガイドとLambdaサーバーレスガイドも合わせて参照してください。
コスト最適化:従来構成 vs Durable Functions
課金モデルの違い
| 課金項目 | 従来のLambda | Durable Functions |
|---|---|---|
| 実行時間 | リクエスト単価 | リクエスト単価(同じ) |
| チェックポイント | — | DynamoDB WCU(低コスト) |
| 状態保存 | — | DynamoDB ストレージ |
| Managed Instance | — | インスタンス稼働時間 |
コスト試算シミュレーション
ユースケース: 1日1回、10万ドキュメントのAI分析(処理時間: 2時間)
| 構成 | 月額コスト |
|---|---|
| EC2 + ECS(常時起動) | $350〜500 |
| Step Functions + Lambda | $150〜250 |
| Lambda Durable Functions | $80〜120 |
Durable Functionsは、EC2/ECS構成と比較して60〜75%のコスト削減が可能です。
サーバーレスプロジェクトガイドでも、コスト最適化のパターンを紹介しています。
SESエンジニアとしてのスキルアップポイント
Lambda Durable Functionsは、以下のSES案件で重宝されるスキルです。
- AI/ML基盤構築案件 — 推論パイプラインの設計・実装
- データエンジニアリング案件 — 大規模ETL処理の効率化
- モダナイゼーション案件 — レガシーバッチ処理のサーバーレス化
AWSエンジニアガイドで、AWS案件全体のスキルマップを確認してください。
まとめ:Durable Functionsで広がるサーバーレスの可能性
Lambda Durable Functionsは、サーバーレスの適用範囲を大幅に拡張する画期的な機能です。
今日から始める3ステップ:
sam init --app-template durable-functionでサンプルプロジェクトを作成- 既存のバッチ処理をDurable Functionsに移行してコスト比較
- AI推論パイプラインのPoCを構築してチームに提案
15分制限に悩まされていたサーバーレスの世界が、Durable Functionsで大きく変わります。





