「バッチ処理はわかるけど、リアルタイム処理は未経験」——データエンジニアリングの世界で、ここを超えられるかが単価の分かれ目です。
AWS Kinesisを使ったリアルタイムデータ処理スキルを持つSESエンジニアは、月額65〜90万円の高単価帯で案件を獲得しています。この記事では、AWS 完全攻略シリーズ第40弾として、Kinesisの基本から実践パターン、SES案件での活かし方まで解説します。
この記事を3秒でまとめると
- AWS Kinesisはリアルタイムデータの収集・処理・分析を実現するマネージドサービス群
- Data Streams / Firehose / Analyticsの3サービスを使い分けることがポイント
- IoT・EC・金融の分野でSES案件の需要が急増中
AWS Kinesisとは?リアルタイムデータ処理の基本
AWS Kinesisは、大量のリアルタイムデータを収集・処理・分析するためのフルマネージドサービス群です。毎秒数百万レコードの処理に対応し、ミリ秒単位のレイテンシーでデータを届けることができます。
Kinesis Data Streams / Firehose / Analyticsの違い
| サービス | 用途 | 特徴 |
|---|---|---|
| Data Streams | リアルタイムデータの取り込み・処理 | カスタム処理ロジックを実装可能 |
| Data Firehose | データの配信・蓄積 | S3/Redshift等への自動配信 |
| Data Analytics | リアルタイム分析 | SQLでストリームデータを分析 |
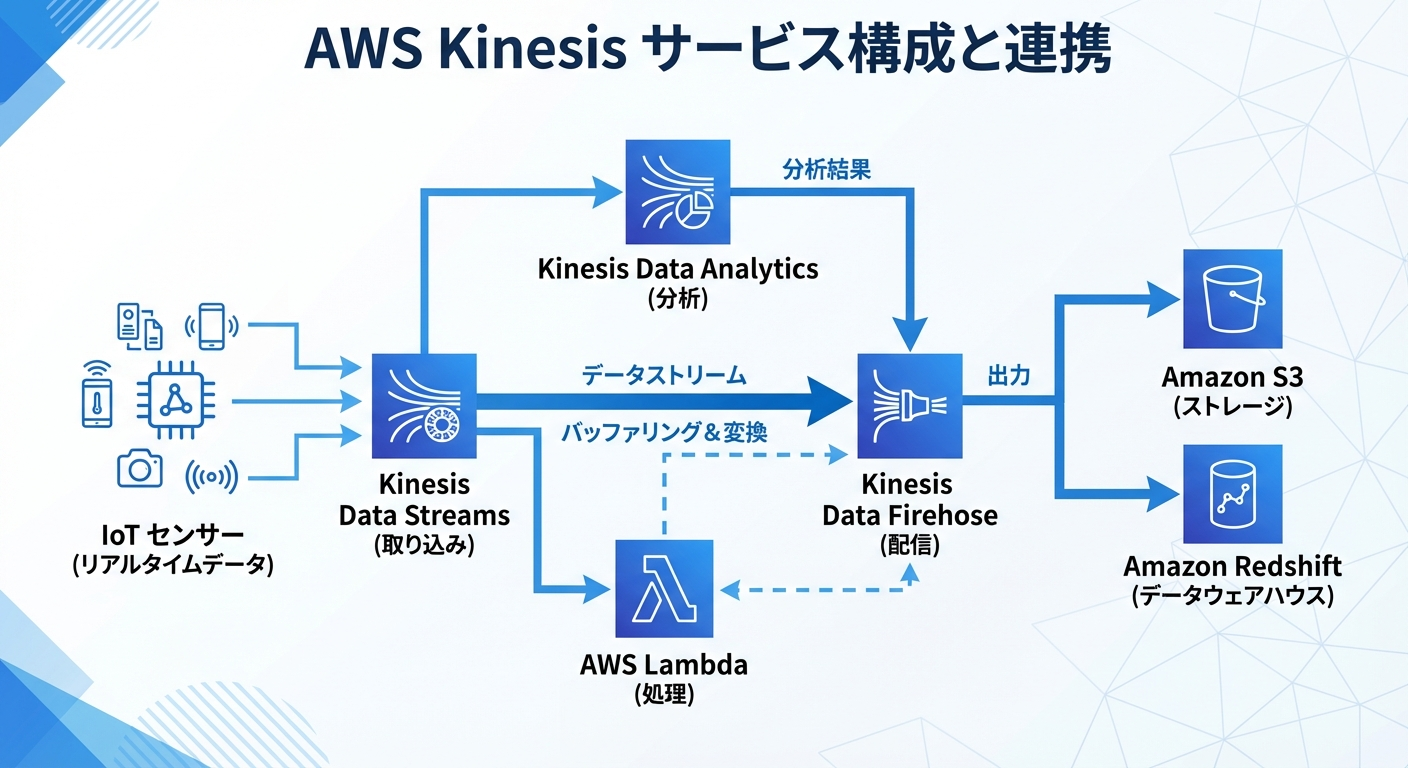
AWS公式ドキュメントによれば、これら3つのサービスは独立して使うことも、組み合わせて使うこともできます(出典: AWS Kinesis ドキュメント)。
ユースケース別の選定ガイド
| ユースケース | 推奨サービス | 理由 |
|---|---|---|
| IoTセンサーデータの収集 | Data Streams | カスタム処理が必要 |
| ログの集約・保存 | Firehose | 配信のみなら最もシンプル |
| リアルタイムダッシュボード | Data Analytics | SQLで即座に集計可能 |
| クリックストリーム分析 | Data Streams + Analytics | 処理+分析の連携 |
| 機械学習パイプライン | Data Streams + Lambda | 前処理→推論の連携 |
SES案件で求められるKinesisスキル
IoT・ストリーミングデータ案件の需要動向
2026年、リアルタイムデータ処理の需要が特に高い業界は以下の通りです。
- IoT/製造: 工場のセンサーデータをリアルタイムで異常検知(月額70〜90万円)
- EC/マーケティング: ユーザー行動のリアルタイム分析・レコメンド(月額65〜85万円)
- 金融: 取引データのリアルタイムモニタリング・不正検知(月額80〜100万円)
- ゲーム: プレイヤーイベントのリアルタイム集計・マッチメイキング(月額65〜80万円)
データエンジニア案件の需要動向でも、最新の市場トレンドを解説しています。
想定単価帯(月額65〜90万円)
Kinesisスキルを持つエンジニアの単価は、経験年数と周辺スキルによって以下のように分布しています。
| 経験レベル | 単価帯 | 求められるスキル |
|---|---|---|
| ジュニア(1〜2年) | 55〜65万円 | Kinesis基本操作、SDK利用 |
| ミドル(3〜5年) | 65〜80万円 | 設計・運用・トラブルシューティング |
| シニア(5年以上) | 80〜100万円 | アーキテクチャ設計・コスト最適化 |
Kinesis Data Streamsの実装パターン
プロデューサー・コンシューマー設計
Kinesis Data Streamsの基本アーキテクチャは、**プロデューサー(データ送信側)とコンシューマー(データ受信側)**の分離です。
# プロデューサーの例(Python / boto3)
import boto3
import json
kinesis = boto3.client('kinesis', region_name='ap-northeast-1')
def send_event(stream_name, event_data):
response = kinesis.put_record(
StreamName=stream_name,
Data=json.dumps(event_data),
PartitionKey=event_data['device_id']
)
return response
# IoTセンサーデータの送信例
send_event('sensor-stream', {
'device_id': 'sensor-001',
'temperature': 25.3,
'humidity': 60,
'timestamp': '2026-03-20T07:00:00Z'
})# コンシューマーの例(Kinesis Client Library - KCL)
from amazon_kinesalite import KCLProcess
class RecordProcessor:
def process_records(self, records, checkpointer):
for record in records:
data = json.loads(record['data'])
# 異常検知ロジック
if data['temperature'] > 40:
alert(f"高温警告: {data['device_id']}")
checkpointer.checkpoint()シャード管理とスケーリング戦略
Kinesisのスループットはシャード数で決まります。1シャードあたり、入力1MB/秒・出力2MB/秒の処理能力があります。
スケーリングのベストプラクティス:
- パーティションキーの設計: データの偏りを避けるキー設計が重要
- On-Demandモード: トラフィック変動が予測できない場合に推奨
- メトリクス監視: WriteProvisionedThroughputExceededメトリクスでスロットリングを検出
Kinesis Data Firehoseによるデータレイク構築
S3 / Redshift / OpenSearchへの配信設定
Firehoseは、ストリームデータをコードなしで各種データストアに配信できます。
{
"DeliveryStreamName": "sensor-data-to-s3",
"S3DestinationConfiguration": {
"BucketARN": "arn:aws:s3:::my-data-lake",
"Prefix": "raw/sensors/year=!{timestamp:yyyy}/month=!{timestamp:MM}/",
"BufferingHints": {
"SizeInMBs": 64,
"IntervalInSeconds": 60
},
"CompressionFormat": "GZIP"
}
}S3ストレージガイドでも、データレイクの基本設計を解説しています。
データ変換とバッファリング最適化
Firehoseには配信前のデータ変換機能があり、Lambda関数で変換処理を挟むことができます。
- バッファリング: サイズ(1〜128MB)と間隔(60〜900秒)を調整してI/Oを最適化
- データ変換: JSONからParquetへの変換、フィールドの追加・削除
- エラーハンドリング: 変換失敗レコードはS3のエラーバケットに自動退避
Kinesisと他のAWSサービスの連携
Lambda × Kinesis のイベント駆動処理
Lambda関数をKinesisのコンシューマーとして設定することで、サーバーレスなリアルタイム処理を実現できます。
# SAM Template(Lambda + Kinesis連携)
Resources:
ProcessFunction:
Type: AWS::Serverless::Function
Properties:
Handler: index.handler
Runtime: python3.12
Events:
KinesisEvent:
Type: Kinesis
Properties:
Stream: !GetAtt SensorStream.Arn
StartingPosition: LATEST
BatchSize: 100Lambda サーバーレスガイドでも、Lambda活用パターンを解説しています。
Step Functions × Kinesis のワークフロー構築
複雑な処理パイプラインには、Step Functionsでワークフローを組む方法が効果的です。
パイプラインの例:
- Kinesis Data Streams でデータ受信
- Lambda でバリデーション+前処理
- Step Functions で分岐処理(正常データ→集計、異常データ→アラート)
- Firehose でS3に永続化
CloudWatch × Kinesis のモニタリング
Kinesisの健全性を監視するために、以下のCloudWatchメトリクスを常時チェックしましょう。
- IncomingRecords: 入力レコード数の推移
- GetRecords.IteratorAgeMilliseconds: 処理の遅延(理想は0に近い値)
- WriteProvisionedThroughputExceeded: スロットリング発生頻度
- ReadProvisionedThroughputExceeded: 読み取り側のスロットリング
コスト最適化のベストプラクティス
On-Demandモードとプロビジョニングの使い分け
| モード | 向いているケース | 料金特性 |
|---|---|---|
| On-Demand | トラフィック変動が大きい | 従量課金(割高) |
| Provisioned | トラフィックが予測できる | 固定+超過分(割安) |
経験則: 最初はOn-Demandで始め、トラフィックパターンが見えてきたらProvisionedに移行するのがコスト効率が良い戦略です。
データ保持期間の最適化
Kinesisのデータ保持期間はデフォルト24時間、最大365日まで延長可能ですが、保持期間が長いほどコストが増加します。
- リアルタイム処理のみ: 24時間(デフォルト)
- リプレイ可能性が必要: 72時間
- コンプライアンス要件: 7日以上(S3への永続化も併用推奨)
Glue ETLデータパイプラインガイドでも、データパイプラインのコスト最適化を解説しています。
まとめ:リアルタイム処理スキルでSES市場価値を高める
AWS Kinesisを使ったリアルタイムデータ処理は、バッチ処理中心のスキルセットから一歩抜け出すための最適なステップです。
学習ロードマップ:
- Kinesis Data Streamsの基本(プロデューサー・コンシューマー)を理解する
- Lambda連携でサーバーレスなリアルタイム処理を試す
- Firehoseでデータレイクへの配信を構築する
- コスト最適化とモニタリングを実装する
- SES BASEでリアルタイムデータ処理案件を検索する
**リアルタイムデータ処理は、DXが進む2026年以降もSES市場で高い需要が続く成長分野です。**今から学習を始めることで、高単価案件への道が開けます。
SES BASEでは、AWS・データエンジニアリング関連のSES案件を多数掲載しています。案件を検索するからチェックしてみてください。