- DynamoDB経験者のSES案件単価は70〜105万円 — サーバーレス構成の中核DBとして需要急増中
- パーティションキー・ソートキーの設計を押さえれば、数十億レコードでもミリ秒応答を実現できる
- Lambda + API Gateway + DynamoDB の「サーバーレス三種の神器」を使いこなせるエンジニアは市場価値が高い
なぜSESエンジニアにDynamoDBスキルが必要なのか
Amazon DynamoDB は、AWS が提供するフルマネージドNoSQLデータベースサービスです。2012年のリリース以来、ゲーム・EC・IoT・フィンテックなど幅広い業界で採用されており、2026年現在のSES案件市場でもサーバーレスアーキテクチャの中核データベースとして需要が急増しています。
従来のSES案件では RDS(MySQL/PostgreSQL)が主流でしたが、マイクロサービス化やサーバーレス化の波を受けて「DynamoDB設計ができるエンジニア」の募集が増えています。RDBだけでなくNoSQLも設計できるエンジニアは、案件の選択肢が大幅に広がります。
- DynamoDB × SES案件の需要と単価相場
- DynamoDBの基礎(テーブル・パーティションキー・ソートキー)
- 実務で使えるテーブル設計パターン
- GSI(グローバルセカンダリインデックス)の活用法
- コスト最適化とキャパシティモード選定
DynamoDB × SES案件の需要と単価【2026年】
NoSQLエンジニアの市場動向
2026年のSES案件市場では、DynamoDBを含むNoSQLデータベースの経験を求める案件が前年比30%増で伸びています。特に以下の領域で需要が顕著です。
- サーバーレスバックエンド: Lambda + API Gateway + DynamoDB構成
- リアルタイムアプリ: WebSocket API + DynamoDB Streamsを使ったチャット・通知
- IoTデータストア: 大量デバイスからのデータ蓄積・参照
- ゲームバックエンド: ユーザープロフィール・ランキング・セッション管理
DynamoDB経験者の単価レンジ
| 経験レベル | 月単価目安 | 求められるスキル |
|---|---|---|
| 初級(〜1年) | 60〜70万円 | 基本的なCRUD操作、既存テーブルへのクエリ |
| 中級(1〜3年) | 70〜85万円 | テーブル設計、GSI設計、DynamoDB Streams連携 |
| 上級(3年〜) | 85〜105万円 | シングルテーブルデザイン、DAX活用、大規模運用 |
💡 ポイント: DynamoDB単体よりも「Lambda + DynamoDB」「API Gateway + DynamoDB」のようにサーバーレスのセットで経験をアピールすると、単価交渉で有利になります。
DynamoDBの基礎知識
RDBとNoSQLの違い
DynamoDBを理解するには、まずRDB(リレーショナルデータベース)との違いを把握しましょう。
| 比較項目 | RDB(RDS/Aurora) | NoSQL(DynamoDB) |
|---|---|---|
| データモデル | テーブル・行・列 | テーブル・アイテム・属性 |
| スキーマ | 固定(事前定義必須) | 柔軟(キー以外は自由) |
| スケーリング | 垂直(インスタンスサイズ変更) | 水平(自動パーティショニング) |
| クエリ | SQL(JOIN、サブクエリ可) | キーベース(JOINなし) |
| トランザクション | 強力(ACID完全準拠) | 制限付き(25アイテムまで) |
| 適するワークロード | 複雑なリレーション | 高スループット・低レイテンシ |
**重要なのは「どちらが優れているか」ではなく「ワークロードに合った選択ができるか」**です。面接やSES案件の参画時に「なぜDynamoDBを選んだか」を論理的に説明できるエンジニアは高く評価されます。
DynamoDBの基本構造
DynamoDBのデータモデルを理解するための重要な用語を整理します。
テーブル(Table)
└── アイテム(Item) ≒ RDBの「行」
├── パーティションキー(PK) ← 必須
├── ソートキー(SK) ← オプション
└── その他の属性 ← 自由に追加可能パーティションキー(Partition Key)
テーブル内のアイテムを物理的に分散配置するためのキーです。DynamoDBはこの値をハッシュ関数に通して、データを格納するパーティションを決定します。
// 良い例:カーディナリティが高い
PK = "USER#user-12345"
// 悪い例:特定の値に偏る(ホットパーティション)
PK = "STATUS#active" ← ほぼ全ユーザーがactiveならNGソートキー(Sort Key)
同じパーティションキーを持つアイテムの並び順を決めるキーです。範囲クエリ(begins_with、between)が可能になります。
PK = "USER#12345", SK = "ORDER#2026-03-01"
PK = "USER#12345", SK = "ORDER#2026-03-05"
PK = "USER#12345", SK = "PROFILE"この設計により、
PK = "USER#12345"でクエリすれば、そのユーザーの注文履歴とプロフィールを1回のクエリで取得できます。
キャパシティモード
DynamoDBには2つのキャパシティモードがあり、ワークロードの特性に応じて選択します。
| モード | 特徴 | 向いているケース |
|---|---|---|
| オンデマンド | リクエスト数に応じた従量課金 | トラフィック予測が困難、スパイクが多い |
| プロビジョンド | 事前にRCU/WCUを指定 | トラフィックが安定、コスト最適化したい |
SES案件での実務ポイント: 開発・ステージング環境はオンデマンド、本番環境はプロビジョンド+Auto Scalingという組み合わせが一般的です。
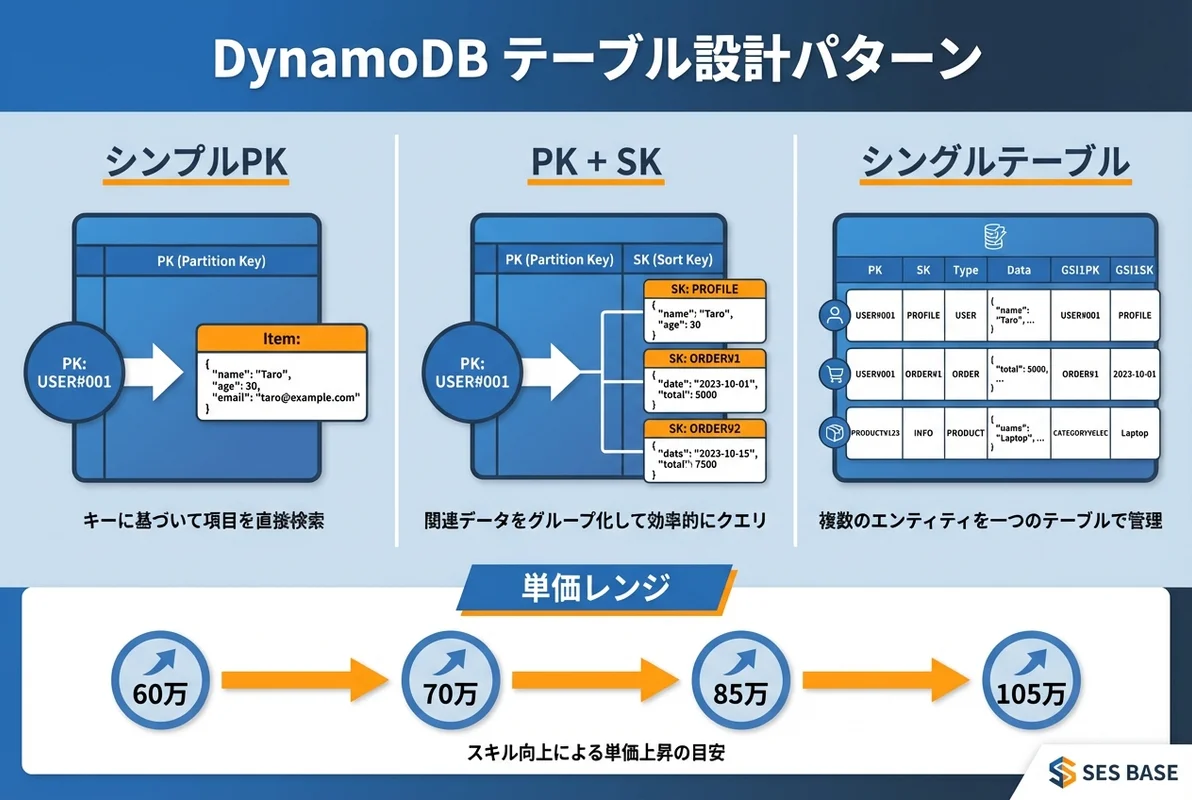
実践:DynamoDBテーブル設計パターン
パターン1:ユーザー管理テーブル
SES案件で最も基本的な設計パターンです。
テーブル名: Users
PK: USER#<userId>
SK: METADATA
属性例:
{
"PK": "USER#u-001",
"SK": "METADATA",
"email": "[email protected]",
"name": "田中太郎",
"role": "engineer",
"createdAt": "2026-01-15T09:00:00Z"
}パターン2:1対多のリレーション(注文履歴)
RDBならJOINで取得するデータを、DynamoDBではアイテムコレクションとして1テーブルに格納します。
// ユーザー情報
PK: USER#u-001, SK: PROFILE
{ "name": "田中太郎", "email": "[email protected]" }
// 同じユーザーの注文履歴
PK: USER#u-001, SK: ORDER#2026-01-15
{ "product": "AWS入門書", "amount": 3980 }
PK: USER#u-001, SK: ORDER#2026-02-20
{ "product": "Terraform実践ガイド", "amount": 4500 }この設計なら PK = USER#u-001 でクエリするだけで、ユーザー情報と全注文履歴を1回のAPI呼び出しで取得できます。
パターン3:シングルテーブルデザイン
上級者向けですが、SES案件の設計レビューで評価されるパターンです。複数のエンティティを1つのテーブルに格納します。
// ユーザー
PK: USER#u-001, SK: PROFILE → ユーザー情報
PK: USER#u-001, SK: ORDER#2026-01 → 注文
// 商品
PK: PRODUCT#p-100, SK: DETAIL → 商品情報
PK: PRODUCT#p-100, SK: REVIEW#r-01 → レビュー
// GSI1で「商品ごとの注文一覧」を取得
GSI1PK: PRODUCT#p-100, GSI1SK: ORDER#2026-01⚠️ シングルテーブルデザインはアクセスパターンの事前分析が必須です。「とりあえずシングルテーブル」は逆にメンテナンス性を下げるので注意しましょう。
GSI(グローバルセカンダリインデックス)の活用
GSIとは
DynamoDBのテーブルは、パーティションキーとソートキーでしかクエリできません。別の属性でもクエリしたい場合に使うのがGSIです。
例えば、ユーザーテーブルで「メールアドレスからユーザーを検索」したい場合:
// メインテーブル
PK: USER#u-001, SK: PROFILE, email: [email protected]
// GSI: EmailIndex
GSI-PK: [email protected] → USER#u-001 のアイテムがヒットGSI設計のベストプラクティス
SES案件の設計レビューで押さえるべきポイントです。
- アクセスパターンから逆算して設計する: テーブルを先に作ってからGSIを追加するのではなく、「どんなクエリが必要か」を洗い出してからテーブル設計を始める
- GSIは最大20個: 上限があるため、汎用的なGSIを設計する(GSI Overloading)
- 射影属性を最小化する: GSIにコピーされる属性が多いとコストが増大する
- スパースインデックスを活用する: GSIのキーに該当する属性を持つアイテムだけがインデックスに含まれる特性を使う
// スパースインデックスの例:「プレミアム会員だけを検索」
// 通常会員: premiumTier属性を持たない → GSIに含まれない
// プレミアム: premiumTier = "gold" → GSIに含まれる
GSI: PremiumIndex
GSI-PK: premiumTier
GSI-SK: createdAtDynamoDB Streams × Lambda連携
リアルタイムイベント駆動
DynamoDB Streamsは、テーブルへのデータ変更をリアルタイムにキャプチャする機能です。Lambda関数をトリガーとして接続すると、データの変更に応じた自動処理が実現できます。
[DynamoDB テーブル]
↓ データ変更(INSERT/MODIFY/REMOVE)
[DynamoDB Streams]
↓ トリガー
[Lambda関数]
↓ 処理実行
[SNS通知 / SQS / 別テーブル更新 など]SES案件でよく見る活用パターン
| パターン | 説明 |
|---|---|
| データ集計 | 注文データが追加されたら売上集計テーブルを自動更新 |
| 通知 | ユーザー登録時にウェルカムメール送信 |
| データ同期 | DynamoDBのデータをElasticsearchに同期して全文検索 |
| 監査ログ | データの変更履歴を別テーブルに自動保存 |
💡 面接対策: 「DynamoDB Streams + Lambdaでイベント駆動処理を実装した」という経験は、サーバーレス案件の選考で非常に強力なアピールポイントになります。
コスト最適化の実践
読み書きコストの計算
DynamoDBのコストは読み取り/書き込みリクエスト数とストレージ容量で決まります。
オンデマンドモード(東京リージョン):
- 書き込み: $1.4846 / 100万WRU
- 読み取り: $0.2969 / 100万RRU
- ストレージ: $0.285 / GB・月
プロビジョンドモード(東京リージョン):
- 書き込み: $0.000742 / WCU・時間
- 読み取り: $0.000148 / RCU・時間
コスト削減の3つの戦略
1. 結果整合性読み取りを活用する
デフォルトの「結果整合性のある読み取り」は、「強力な整合性のある読み取り」の半分のコストです。リアルタイム性が不要な場面(一覧表示、レポートなど)では結果整合性を選びましょう。
2. TTL(Time to Live)でデータを自動削除
不要になったデータを自動削除することで、ストレージコストとスキャンコストを削減できます。
// セッションデータに TTL を設定
{
"PK": "SESSION#abc123",
"SK": "DATA",
"userId": "u-001",
"ttl": 1741276800 // Unix timestamp: 2026-03-06T12:00:00Z
}3. リザーブドキャパシティを活用
1年または3年のコミットで最大77%割引を受けられます。安定した本番ワークロードにはリザーブドキャパシティが有効です。
DynamoDB × サーバーレス構成の実践例
SES案件で頻出するLambda + API Gateway + DynamoDBの構成例を紹介します。
[クライアント]
↓ HTTPS
[API Gateway]
↓ REST API
[Lambda関数]
↓ AWS SDK
[DynamoDB]Lambda関数のサンプル(ユーザー取得)
import { DynamoDBClient } from "@aws-sdk/client-dynamodb";
import { DynamoDBDocumentClient, GetCommand } from "@aws-sdk/lib-dynamodb";
const client = new DynamoDBClient({});
const docClient = DynamoDBDocumentClient.from(client);
export const handler = async (event) => {
const userId = event.pathParameters.userId;
const result = await docClient.send(new GetCommand({
TableName: "Users",
Key: {
PK: `USER#${userId}`,
SK: "PROFILE"
}
}));
if (!result.Item) {
return { statusCode: 404, body: JSON.stringify({ error: "User not found" }) };
}
return { statusCode: 200, body: JSON.stringify(result.Item) };
};この構成はLambda入門記事やAPI Gateway実践ガイドでも詳しく解説していますので、あわせてご覧ください。
SES案件でのDynamoDB面接対策
よく聞かれる質問と回答例
Q: DynamoDBを選択する基準は?
A: アクセスパターンが明確で、高スループット・低レイテンシが求められるワークロードに適しています。具体的には、キー・バリュー型のアクセスが中心で、複雑なJOINが不要なケースです。逆に、アドホックなクエリや集計が多い場合はRDSの方が適しています。
Q: ホットパーティションをどう防ぎますか?
A: パーティションキーのカーディナリティを高くすることが基本です。例えばユーザーIDやUUIDをパーティションキーに使います。日付やステータスなど偏りやすい値は避けるか、ランダムサフィックスを付与して分散させます。
Q: DynamoDBのトランザクション制限を教えてください
A: TransactWriteItemsで最大100アイテム(25グループ)、4MB以内の制約があります。大量データの一括処理にはBatchWriteItem(25アイテム/回)を使い、トランザクション保証が必要な部分だけTransactWriteItemsを使用します。
まとめ:DynamoDBスキルで案件の幅を広げよう
DynamoDBは、サーバーレスアーキテクチャの普及とともにSES案件市場での需要が急増しているサービスです。
この記事のポイントを振り返りましょう:
- DynamoDB経験者の単価は70〜105万円で、RDB+NoSQLの両方ができると差別化になる
- パーティションキー・ソートキーの設計がパフォーマンスの鍵
- GSIを活用して多様なアクセスパターンに対応する
- DynamoDB Streams + Lambda でイベント駆動アーキテクチャを構築する
- コスト最適化(結果整合性・TTL・リザーブド)を理解しておく
まずはAWS公式のDynamoDBチュートリアルで手を動かし、本記事のテーブル設計パターンを実際に試してみましょう。サーバーレス構成全体を学びたい方は、Ep2: サーバーレス案件ガイドもあわせてご覧ください。
出典・参考文献: