
- AWS Bedrock Prompt ManagementでLLMプロンプトをコードと同様にバージョン管理できる
- A/Bテスト・自動評価パイプラインで最適なプロンプトを科学的に選定
- SES案件で急増する生成AI基盤構築スキルの習得にPrompt Managementが必須
「プロンプトの変更でAIの出力品質が急に下がった」「誰がいつプロンプトを変更したのか追跡できない」「どのプロンプトバージョンが最も成果を出しているのかわからない」——生成AIを本番運用する企業が増える中、プロンプトの管理が新たな課題として浮上しています。
2026年現在、AWS BedrockのPrompt Management機能は、これらの課題を体系的に解決するマネージドサービスとして注目を集めています。プロンプトのバージョン管理、A/Bテスト、デプロイパイプラインを、AWSのエコシステム内で一元管理できます。
この記事では、AWS Bedrock Prompt Managementの機能と実践的な活用方法を、SES現場で使えるレベルまで詳しく解説します。
- Prompt Managementの基本概念とアーキテクチャ
- プロンプトのバージョン管理とデプロイフロー
- A/Bテストによるプロンプトの最適化手法
- 自動評価パイプラインの構築
- SES案件での活用パターンと年収への影響
AWS Bedrock Prompt Managementとは
基本概念
Bedrock Prompt Managementは、LLMに渡すプロンプトを構造化して管理するためのサービスです。ソフトウェア開発におけるコードのバージョン管理と同様に、プロンプトの変更履歴・テスト・デプロイを体系的に管理します。
# Prompt Managementの構成要素
┌─────────────────────────────────────┐
│ Prompt Management │
│ │
│ ┌──────────┐ ┌──────────────────┐ │
│ │ Prompt │ │ Prompt Version │ │
│ │ Template │ │ (v1, v2, v3...) │ │
│ └────┬─────┘ └────┬─────────────┘ │
│ │ │ │
│ ┌────┴─────┐ ┌────┴─────────────┐ │
│ │ Variable │ │ Model Config │ │
│ │ Slots │ │ (temp, topP...) │ │
│ └──────────┘ └──────────────────┘ │
└─────────────────────────────────────┘主要コンポーネント
| コンポーネント | 説明 | 具体例 |
|---|---|---|
| Prompt Template | プロンプトのひな形 | カスタマーサポート用応答テンプレート |
| Variable Slots | 動的に埋め込む変数 | {{customer_name}}, {{issue_type}} |
| Version | プロンプトのバージョン | v1(初版)→ v2(改善版)→ v3(最適化版) |
| Model Config | モデル固有の設定 | temperature: 0.3, topP: 0.9 |
プロンプトの作成とバージョン管理
AWS CLIでのプロンプト作成
# プロンプトテンプレートの作成
aws bedrock-agent create-prompt \
--name "customer-support-v1" \
--description "カスタマーサポート用の応答生成プロンプト" \
--variants '[
{
"name": "default",
"modelId": "anthropic.claude-sonnet-4-20250514-v1:0",
"templateType": "TEXT",
"templateConfiguration": {
"text": {
"text": "あなたは{{company_name}}のカスタマーサポート担当者です。\n\n以下の顧客からの問い合わせに、丁寧かつ正確に回答してください。\n\n## 顧客情報\n- 名前: {{customer_name}}\n- プラン: {{plan_type}}\n- 契約期間: {{contract_period}}\n\n## 問い合わせ内容\n{{inquiry}}\n\n## 回答ルール\n1. 敬語を使い、親しみやすいトーンで回答\n2. 不明点は正直に「確認します」と伝える\n3. 関連するFAQリンクがあれば提示する\n4. 200文字以内で簡潔に回答する",
"inputVariables": [
{"name": "company_name"},
{"name": "customer_name"},
{"name": "plan_type"},
{"name": "contract_period"},
{"name": "inquiry"}
]
}
},
"inferenceConfiguration": {
"text": {
"temperature": 0.3,
"topP": 0.9,
"maxTokens": 500
}
}
}
]'バージョニング戦略
プロンプトのバージョン管理には、以下の戦略を推奨します。
# バージョニングフロー
Draft → Review → Test → Staging → Production
v1.0 (Production) ← 現在の本番プロンプト
v1.1 (Staging) ← A/Bテスト中
v2.0 (Draft) ← 大幅改修中# プロンプトバージョンの作成
aws bedrock-agent create-prompt-version \
--prompt-identifier "PROMPT_ID" \
--description "v1.1: 回答の丁寧さを改善、FAQリンク追加"Infrastructure as Code(CloudFormation)
# cloudformation/prompt-management.yaml
AWSTemplateFormatVersion: '2010-09-09'
Description: Bedrock Prompt Management Stack
Resources:
CustomerSupportPrompt:
Type: AWS::Bedrock::Prompt
Properties:
Name: customer-support
Description: カスタマーサポート応答生成
DefaultVariant: claude-sonnet
Variants:
- Name: claude-sonnet
ModelId: anthropic.claude-sonnet-4-20250514-v1:0
TemplateType: TEXT
TemplateConfiguration:
Text:
Text: !Sub |
あなたは${CompanyName}のカスタマーサポート担当者です。
{{inquiry}}に対して丁寧に回答してください。
InputVariables:
- Name: inquiry
InferenceConfiguration:
Text:
Temperature: 0.3
MaxTokens: 500
PromptAlias:
Type: AWS::Bedrock::PromptVersion
Properties:
PromptId: !Ref CustomerSupportPrompt
Description: Production version
Parameters:
CompanyName:
Type: String
Default: SES BASEA/Bテストによるプロンプト最適化
A/Bテストの設計
プロンプトのA/Bテストは、同じ入力に対して異なるプロンプトバージョンの出力を比較し、最も良い結果を出すバージョンを選定する手法です。
# A/Bテストの構成
ユーザーリクエスト
↓
┌───────────────────┐
│ Traffic Router │
│ (50% / 50%) │
└───┬───────────┬───┘
↓ ↓
┌───────┐ ┌───────┐
│Prompt │ │Prompt │
│ v1.0 │ │ v1.1 │
└───┬───┘ └───┬───┘
↓ ↓
┌───────┐ ┌───────┐
│Result │ │Result │
│ A │ │ B │
└───┬───┘ └───┬───┘
↓ ↓
┌───────────────────┐
│ Evaluation │
│ (品質メトリクス) │
└───────────────────┘評価メトリクスの定義
| メトリクス | 測定方法 | 目標値 |
|---|---|---|
| 正確性 | LLMによる自動評価 | 90%以上 |
| トーンの適切さ | 感情分析スコア | 4.0/5.0以上 |
| 回答の簡潔さ | 文字数チェック | 200字以内 |
| ユーザー満足度 | フィードバックボタン | 80%以上 |
| レスポンスタイム | API計測 | 3秒以内 |
Pythonでの A/Bテスト実装
# prompt_ab_test.py
import boto3
import json
import random
from datetime import datetime
bedrock_agent = boto3.client('bedrock-agent-runtime')
bedrock = boto3.client('bedrock-runtime')
class PromptABTest:
def __init__(self, prompt_id: str, versions: list[str], weights: list[float]):
self.prompt_id = prompt_id
self.versions = versions
self.weights = weights
self.results = {v: [] for v in versions}
def select_version(self) -> str:
"""重み付きランダムでバージョンを選択"""
return random.choices(self.versions, weights=self.weights, k=1)[0]
def invoke(self, variables: dict) -> dict:
"""プロンプトを実行してA/Bテスト結果を記録"""
version = self.select_version()
start_time = datetime.now()
response = bedrock_agent.invoke_prompt(
promptIdentifier=self.prompt_id,
promptVersion=version,
variables=[
{"name": k, "value": v} for k, v in variables.items()
]
)
elapsed = (datetime.now() - start_time).total_seconds()
output = response['output']['text']
result = {
'version': version,
'input': variables,
'output': output,
'latency_seconds': elapsed,
'timestamp': datetime.now().isoformat(),
'char_count': len(output),
}
self.results[version].append(result)
return result
def get_summary(self) -> dict:
"""A/Bテスト結果のサマリーを取得"""
summary = {}
for version, results in self.results.items():
if not results:
continue
latencies = [r['latency_seconds'] for r in results]
char_counts = [r['char_count'] for r in results]
summary[version] = {
'count': len(results),
'avg_latency': sum(latencies) / len(latencies),
'avg_char_count': sum(char_counts) / len(char_counts),
'p95_latency': sorted(latencies)[int(len(latencies) * 0.95)],
}
return summary
# 使用例
ab_test = PromptABTest(
prompt_id="PROMPT_ABC123",
versions=["1", "2"],
weights=[0.5, 0.5]
)
# テスト実行
test_cases = [
{"customer_name": "山田太郎", "inquiry": "請求書の再発行をお願いします"},
{"customer_name": "田中花子", "inquiry": "プランの変更方法を教えてください"},
{"customer_name": "佐藤一郎", "inquiry": "解約手続きはどうすればいいですか"},
]
for case in test_cases:
result = ab_test.invoke(case)
print(f"Version {result['version']}: {result['output'][:100]}...")
print(json.dumps(ab_test.get_summary(), indent=2, ensure_ascii=False))自動評価パイプラインの構築
Step Functionsで評価ワークフローを構築
{
"Comment": "Prompt Evaluation Pipeline",
"StartAt": "LoadTestCases",
"States": {
"LoadTestCases": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:123:function:load-test-cases",
"Next": "RunABTest"
},
"RunABTest": {
"Type": "Map",
"ItemsPath": "$.testCases",
"Iterator": {
"StartAt": "InvokePrompt",
"States": {
"InvokePrompt": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:123:function:invoke-prompt",
"Next": "EvaluateOutput"
},
"EvaluateOutput": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:123:function:evaluate-output",
"End": true
}
}
},
"Next": "AggregateResults"
},
"AggregateResults": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:123:function:aggregate-results",
"Next": "DecideWinner"
},
"DecideWinner": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.winner",
"StringEquals": "version_b",
"Next": "PromoteVersionB"
}
],
"Default": "KeepCurrentVersion"
},
"PromoteVersionB": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:123:function:promote-prompt",
"End": true
},
"KeepCurrentVersion": {
"Type": "Pass",
"End": true
}
}
}LLM-as-a-Judge(LLMによる自動評価)
# evaluate_output.py
import boto3
import json
bedrock = boto3.client('bedrock-runtime')
def evaluate_with_llm(original_query: str, response: str, criteria: list[str]) -> dict:
"""LLMを使ってプロンプト出力を自動評価する"""
evaluation_prompt = f"""以下のカスタマーサポート応答を評価してください。
## 顧客の問い合わせ
{original_query}
## AIの応答
{response}
## 評価基準
{json.dumps(criteria, ensure_ascii=False)}
## 出力形式(JSON)
{{
"scores": {{
"accuracy": 1-5の整数,
"tone": 1-5の整数,
"conciseness": 1-5の整数,
"helpfulness": 1-5の整数
}},
"overall": 1-5の整数,
"feedback": "改善点のコメント"
}}
JSONのみを出力してください。"""
result = bedrock.invoke_model(
modelId='anthropic.claude-sonnet-4-20250514-v1:0',
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 500,
"messages": [{"role": "user", "content": evaluation_prompt}]
})
)
response_body = json.loads(result['body'].read())
evaluation = json.loads(response_body['content'][0]['text'])
return evaluation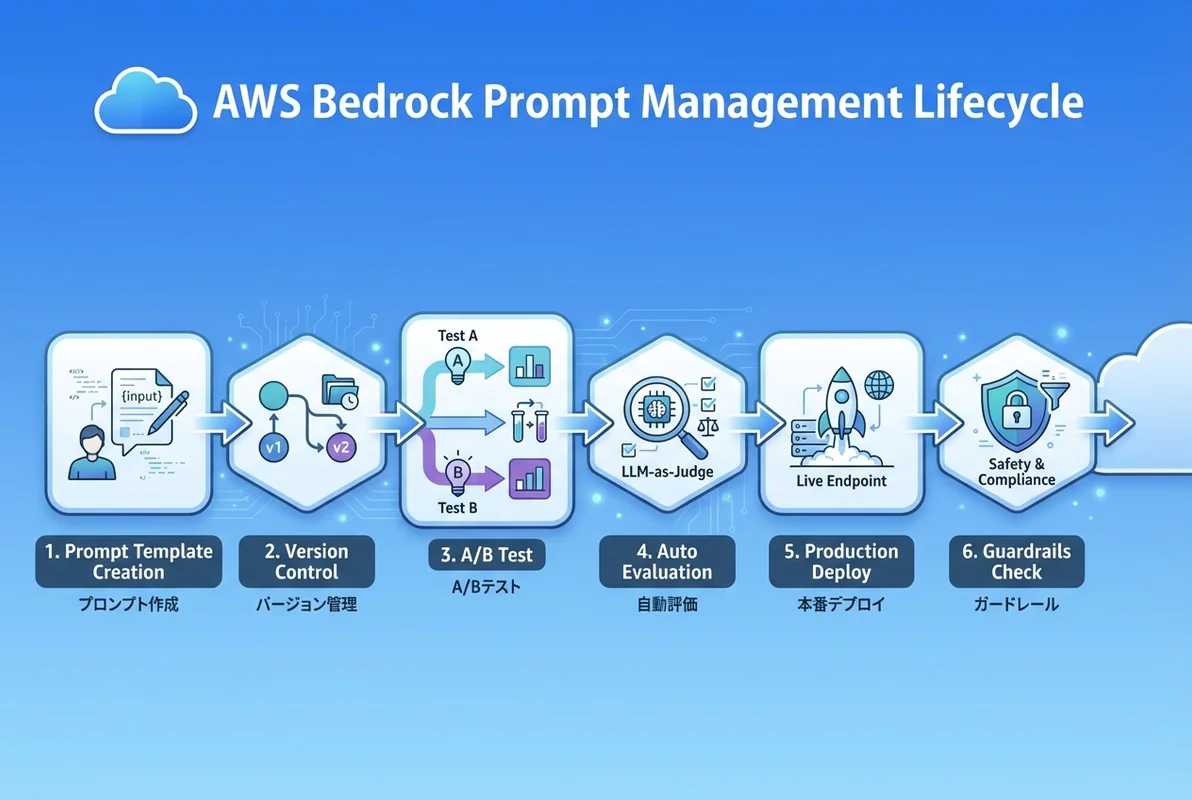
Guardrailsとの統合
プロンプト出力の安全性確保
Bedrock Guardrailsと組み合わせることで、プロンプトの出力が安全基準を満たしていることを保証します。
# Guardrailの作成
aws bedrock create-guardrail \
--name "customer-support-guardrail" \
--description "カスタマーサポート用の安全性ガードレール" \
--content-policy-config '{
"filtersConfig": [
{"type": "SEXUAL", "inputStrength": "HIGH", "outputStrength": "HIGH"},
{"type": "VIOLENCE", "inputStrength": "HIGH", "outputStrength": "HIGH"},
{"type": "HATE", "inputStrength": "HIGH", "outputStrength": "HIGH"},
{"type": "INSULTS", "inputStrength": "HIGH", "outputStrength": "HIGH"}
]
}' \
--sensitive-information-policy-config '{
"piiEntitiesConfig": [
{"type": "EMAIL", "action": "ANONYMIZE"},
{"type": "PHONE", "action": "ANONYMIZE"},
{"type": "CREDIT_DEBIT_CARD_NUMBER", "action": "BLOCK"}
]
}' \
--blocked-input-messaging "この内容にはお答えできません。" \
--blocked-output-messaging "回答の生成中にエラーが発生しました。"コスト最適化
プロンプトのコスト分析
# prompt_cost_analyzer.py
def analyze_prompt_cost(prompt_text: str, avg_output_tokens: int, daily_requests: int):
"""プロンプトのコストを分析"""
import tiktoken
# トークン数の概算
input_tokens = len(prompt_text) // 3 # 日本語は約3文字/トークン
# Claude Sonnet 4の料金(2026年4月時点)
input_cost_per_1k = 0.003 # $3/1M tokens
output_cost_per_1k = 0.015 # $15/1M tokens
daily_input_cost = (input_tokens * daily_requests / 1000) * input_cost_per_1k
daily_output_cost = (avg_output_tokens * daily_requests / 1000) * output_cost_per_1k
daily_total = daily_input_cost + daily_output_cost
return {
"input_tokens_per_request": input_tokens,
"daily_cost_usd": round(daily_total, 2),
"monthly_cost_usd": round(daily_total * 30, 2),
"cost_per_request_usd": round(daily_total / daily_requests, 6),
"optimization_tips": [
f"プロンプトを{input_tokens * 0.3:.0f}トークン削減すれば月${daily_total * 30 * 0.3:.2f}節約",
"キャッシュ対象のクエリを特定し、Prompt Cachingを活用",
"低頻度クエリにはHaikuモデルを使用してコスト削減",
]
}SES案件でのPrompt Management活用
活用パターンと単価
| パターン | スキル要件 | 想定単価 | 案件期間 |
|---|---|---|---|
| チャットボット品質管理 | Bedrock + Prompt Management | 75-95万円/月 | 6ヶ月〜 |
| 社内AI基盤構築 | Bedrock + Step Functions + S3 | 85-110万円/月 | 1年〜 |
| AIレビュー自動化 | Bedrock + Guardrails + Lambda | 80-100万円/月 | 3ヶ月〜 |
求められるスキルセット
■ 必須スキル
├── AWS Bedrock(モデル呼び出し・Prompt Management)
├── Python / TypeScript
├── CloudFormation / CDK
└── CI/CD パイプライン
■ あると有利なスキル
├── 機械学習の基礎知識
├── プロンプトエンジニアリング
├── LLM評価手法(BLEU, ROUGE, LLM-as-Judge)
└── コスト最適化(Reserved Throughput)まとめ
AWS Bedrock Prompt Managementを活用したプロンプト管理・最適化について、実践的な手法を解説しました。
- Prompt Managementはプロンプトのバージョン管理・テスト・デプロイを体系化するサービス
- A/Bテストと自動評価パイプラインで、プロンプトの品質を科学的に最適化できる
- Guardrailsとの統合で、出力の安全性とコンプライアンスを保証
- CloudFormation / CDKでInfrastructure as Codeとして管理可能
- SES案件で生成AI基盤スキルは75〜110万円/月の高単価案件に直結する
次のステップ: Prompt Managementの基礎を押さえたら、AWS Bedrockで生成AIアプリケーションを構築する方法で、より包括的なAI基盤構築に挑戦しましょう。
関連記事:





