
- Bedrock Knowledge BasesはS3にドキュメントを置くだけでRAG検索基盤を構築できるフルマネージドサービス
- ベクトルDB(OpenSearch Serverless / Aurora)の自動管理により、インフラ運用の手間なくRAGを実現
- SES現場で需要急増中のRAG構築スキルを習得すれば、AI案件の単価アップに直結する
2026年、企業のAI活用で最も注目されているのが**RAG(Retrieval-Augmented Generation)**です。社内文書をAIが検索・参照して回答を生成するこの技術は、企業のDXプロジェクトに欠かせない要素になっています。
AWS Bedrock Knowledge Basesは、RAGをフルマネージドで構築できるサービスです。S3にドキュメントを配置し、数回の設定でベクトル検索基盤が完成します。インフラの運用負荷を最小限に抑えながら、高品質なAI検索を実現できるのが最大の強みです。
本記事では、Bedrock Knowledge Basesを使ったRAG構築の手順を、アーキテクチャ設計から実装・運用まで実践的に解説します。
- RAG(検索拡張生成)の仕組みと企業での活用シーン
- Bedrock Knowledge Basesのアーキテクチャと構成要素
- S3 + OpenSearch Serverlessでの構築手順
- SES案件でのRAG構築スキルの市場価値
RAGとは?なぜ企業で求められているのか
RAGの基本概念
RAG(Retrieval-Augmented Generation)は、AIの回答精度を向上させるためのアーキテクチャパターンです。
従来のLLM(大規模言語モデル)は、学習データに含まれる情報のみで回答を生成します。そのため、社内固有の情報(社内規定、製品仕様、議事録など)に対しては正確に回答できません。
RAGは以下のフローで、この問題を解決します。
- 検索(Retrieval): ユーザーの質問に関連するドキュメントをベクトル検索で取得
- 拡張(Augmentation): 取得したドキュメントをLLMのプロンプトに追加
- 生成(Generation): ドキュメントの内容を踏まえてLLMが回答を生成
[ユーザーの質問]
↓
[ベクトル検索] → 関連ドキュメントを取得
↓
[プロンプト構築] = 質問 + 関連ドキュメント
↓
[LLM(Claude / Titan等)] → 回答生成
↓
[ユーザーへの回答](出典付き)企業でのRAG活用事例
| 活用シーン | 対象ドキュメント | 効果 |
|---|---|---|
| 社内ヘルプデスク | 社内規定・FAQ・マニュアル | 問い合わせ対応時間70%削減 |
| カスタマーサポート | 製品マニュアル・FAQ | 回答精度・速度の向上 |
| 法務・コンプライアンス | 契約書・法令・ガイドライン | 法的リスクの早期発見 |
| 技術文書検索 | API仕様書・設計書・議事録 | エンジニアの調査時間短縮 |
| 営業支援 | 提案書・事例集・価格表 | 提案品質の標準化 |
Bedrock Knowledge Basesのアーキテクチャ
サービスの全体像
Bedrock Knowledge Basesは、以下のコンポーネントで構成されています。
[S3バケット(ドキュメント保管)]
↓
[Data Source(データソース設定)]
↓
[Chunking(ドキュメント分割)]
↓
[Embedding Model(ベクトル化)]
↓
[Vector Store(ベクトルDB)]
├── OpenSearch Serverless(推奨)
├── Amazon Aurora PostgreSQL
├── Pinecone
└── Redis Enterprise
[検索時]
[ユーザークエリ] → [Embedding] → [Vector Search] → [関連チャンク取得]
↓
[Foundation Model(Claude等)] → [回答生成]構成要素の選択肢
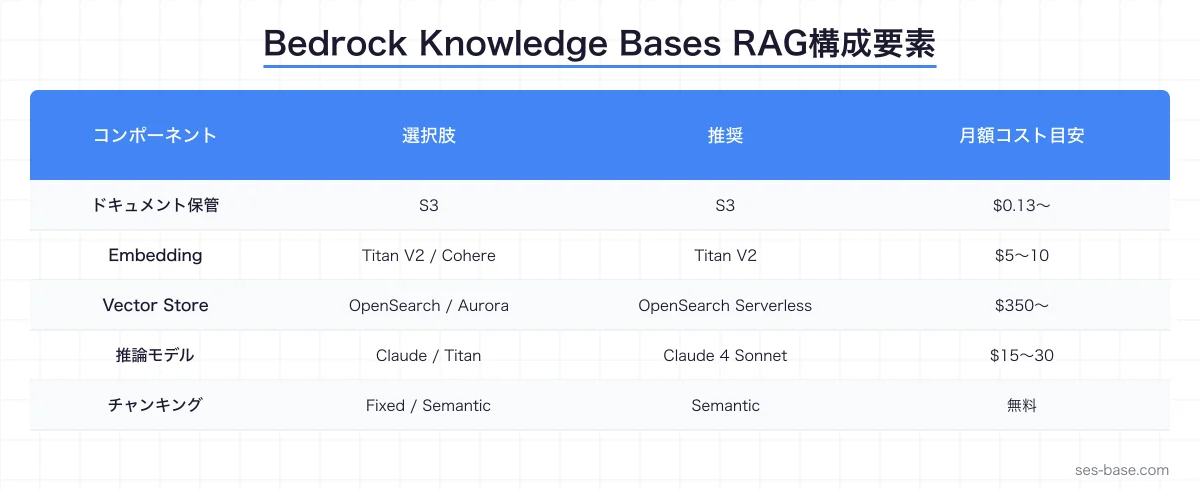
| コンポーネント | 選択肢 | 推奨 |
|---|---|---|
| ドキュメント保管 | S3 | S3(一択) |
| Embedding Model | Titan Embeddings V2 / Cohere Embed | Titan V2 |
| Vector Store | OpenSearch Serverless / Aurora / Pinecone | OpenSearch Serverless |
| Foundation Model | Claude 3.5 Sonnet / Claude 4 / Titan | Claude 4 Sonnet |
| チャンキング | Fixed / Semantic / Hierarchical | Semantic(推奨) |
構築手順
Step 1: S3バケットの準備
RAGの元となるドキュメントをS3に配置します。
# ドキュメント用のS3バケットを作成
aws s3 mb s3://my-company-knowledge-base-docs --region ap-northeast-1
# ドキュメントをアップロード
aws s3 sync ./documents/ s3://my-company-knowledge-base-docs/
# サポートされているファイル形式
# PDF, TXT, MD, HTML, DOC, DOCX, CSV, XLS, XLSXドキュメントの品質がRAGの精度を大きく左右します。以下のポイントに注意しましょう。
- 最新の情報: 古いドキュメントは削除または更新
- 構造化: 見出し・段落が適切に構成されたドキュメント
- 重複排除: 同じ内容の複数バージョンを避ける
- メタデータ: ファイル名に日付やカテゴリを含める
Step 2: Knowledge Baseの作成
AWSコンソールまたはCLIでKnowledge Baseを作成します。
# AWS CLIでKnowledge Baseを作成
aws bedrock-agent create-knowledge-base \
--name "company-knowledge-base" \
--description "社内ドキュメント検索用ナレッジベース" \
--role-arn "arn:aws:iam::123456789012:role/BedrockKBRole" \
--knowledge-base-configuration '{
"type": "VECTOR",
"vectorKnowledgeBaseConfiguration": {
"embeddingModelArn": "arn:aws:bedrock:ap-northeast-1::foundation-model/amazon.titan-embed-text-v2:0"
}
}' \
--storage-configuration '{
"type": "OPENSEARCH_SERVERLESS",
"opensearchServerlessConfiguration": {
"collectionArn": "arn:aws:aoss:ap-northeast-1:123456789012:collection/xxx",
"vectorIndexName": "kb-index",
"fieldMapping": {
"vectorField": "vector",
"textField": "text",
"metadataField": "metadata"
}
}
}'Step 3: データソースの設定
S3バケットをデータソースとして登録します。
# データソースを追加
aws bedrock-agent create-data-source \
--knowledge-base-id "KB-XXXXXXXXXX" \
--name "company-docs" \
--data-source-configuration '{
"type": "S3",
"s3Configuration": {
"bucketArn": "arn:aws:s3:::my-company-knowledge-base-docs"
}
}' \
--vector-ingestion-configuration '{
"chunkingConfiguration": {
"chunkingStrategy": "SEMANTIC",
"semanticChunkingConfiguration": {
"maxTokens": 300,
"bufferSize": 0,
"breakpointPercentileThreshold": 95
}
}
}'Step 4: データの同期(インジェスション)
ドキュメントをベクトル化してVector Storeに格納します。
# データの同期を開始
aws bedrock-agent start-ingestion-job \
--knowledge-base-id "KB-XXXXXXXXXX" \
--data-source-id "DS-XXXXXXXXXX"
# 同期状態の確認
aws bedrock-agent get-ingestion-job \
--knowledge-base-id "KB-XXXXXXXXXX" \
--data-source-id "DS-XXXXXXXXXX" \
--ingestion-job-id "JOB-XXXXXXXXXX"Step 5: テストクエリの実行
構築したKnowledge Baseにクエリを送信してテストします。
# Retrieve APIでテスト(検索のみ)
aws bedrock-agent-runtime retrieve \
--knowledge-base-id "KB-XXXXXXXXXX" \
--retrieval-query '{"text": "有給休暇の申請方法を教えてください"}' \
--retrieval-configuration '{
"vectorSearchConfiguration": {
"numberOfResults": 5
}
}'
# RetrieveAndGenerate APIでテスト(検索+回答生成)
aws bedrock-agent-runtime retrieve-and-generate \
--input '{"text": "有給休暇の申請方法を教えてください"}' \
--retrieve-and-generate-configuration '{
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "KB-XXXXXXXXXX",
"modelArn": "arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-v4-sonnet"
}
}'チャンキング戦略の最適化
チャンキングとは
チャンキングは、長いドキュメントを検索に適したサイズの断片(チャンク)に分割する処理です。チャンキングの品質がRAGの精度を大きく左右します。
チャンキング方式の比較
| 方式 | 特徴 | 適用シーン |
|---|---|---|
| Fixed Size | 固定トークン数で分割 | 均一な構造のドキュメント |
| Semantic | 意味の区切りで分割 | 一般的なビジネス文書(推奨) |
| Hierarchical | 大チャンク+小チャンクの2層 | 長い技術文書・法律文書 |
| None | 分割しない | 短い文書(FAQ等) |
Semanticチャンキングは、文の意味的なまとまりを認識して分割するため、最も自然な検索結果が得られます。技術文書や社内規定など、見出しと本文が構造化されたドキュメントに最適です。
チャンクサイズの調整
{
"chunkingStrategy": "SEMANTIC",
"semanticChunkingConfiguration": {
"maxTokens": 300,
"bufferSize": 0,
"breakpointPercentileThreshold": 95
}
}- maxTokens: 1チャンクの最大トークン数。300〜500が推奨
- breakpointPercentileThreshold: 文の区切りの閾値。95がデフォルト
チャンクが小さすぎると文脈が失われ、大きすぎると検索精度が下がります。ドキュメントの性質に応じて調整しましょう。
コストの見積もり
料金体系
Bedrock Knowledge Basesの料金は以下の要素で構成されます。
| コンポーネント | 料金(東京リージョン目安) |
|---|---|
| S3ストレージ | $0.025/GB/月 |
| Titan Embeddings V2 | $0.00002/1Kトークン |
| OpenSearch Serverless | $0.24/OCU/時間(最小2 OCU) |
| Claude 4 Sonnet(推論) | $0.003/1K入力トークン |
| データ同期 | $0.001/ファイル |
コスト試算例
社内ドキュメント1,000件(平均10ページ)のRAG基盤の月額コスト試算を示します。
| 項目 | 月額コスト |
|---|---|
| S3ストレージ(5GB) | $0.13 |
| Embedding(初回+更新) | $5〜10 |
| OpenSearch Serverless | $350〜700 |
| 推論(1日100クエリ) | $15〜30 |
| 合計 | $370〜740 |
OpenSearch Serverlessのコストが大きいため、小規模な場合はAurora PostgreSQL + pgvectorの選択も検討しましょう。
# コスト比較(月額概算)
OpenSearch Serverless: $350〜(最小2 OCU固定)
Aurora Serverless v2: $50〜(最小0.5 ACU、使用量に応じて拡張)SES案件でのRAG構築スキルの価値
RAGエンジニアの需要と単価
2026年、RAG関連のSES案件は急増しています。
| スキルレベル | 月額単価(目安) | 求められるスキル |
|---|---|---|
| ジュニア | 60〜75万円 | Bedrock基本操作、S3連携 |
| ミドル | 75〜95万円 | チャンキング最適化、精度チューニング |
| シニア | 95〜120万円 | アーキテクチャ設計、マルチモーダルRAG |
差別化ポイント
RAG案件で高単価を実現するためのスキルセットを紹介します。
- チャンキング戦略の設計: ドキュメントの特性に応じた最適な分割方式の選択
- 精度評価と改善: 検索精度(Recall / Precision)の測定とチューニング
- ハイブリッド検索: ベクトル検索 + キーワード検索の組み合わせ
- セキュリティ設計: アクセス制御、データ暗号化、監査ログ
- コスト最適化: ベクトルDBの選択、キャッシュ戦略
セキュリティとガバナンス
データアクセス制御
RAGの対象ドキュメントに機密情報が含まれる場合、適切なアクセス制御が必要です。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"bedrock:RetrieveAndGenerate",
"bedrock:Retrieve"
],
"Resource": "arn:aws:bedrock:ap-northeast-1:123456789012:knowledge-base/KB-XXXXXXXXXX",
"Condition": {
"StringEquals": {
"aws:PrincipalTag/Department": "Engineering"
}
}
}
]
}監査ログの設定
CloudTrailを使って、RAGへのアクセスログを記録します。
# CloudTrailでBedrock APIのログを有効化
aws cloudtrail put-event-selectors \
--trail-name "bedrock-audit-trail" \
--event-selectors '[{
"ReadWriteType": "All",
"IncludeManagementEvents": true,
"DataResources": [{
"Type": "AWS::Bedrock::KnowledgeBase",
"Values": ["arn:aws:bedrock:ap-northeast-1:123456789012:knowledge-base/KB-XXXXXXXXXX"]
}]
}]'まとめ: Bedrock Knowledge BasesでRAGを始めよう
AWS Bedrock Knowledge Basesを使えば、インフラ運用の手間を最小限に抑えながら高品質なRAG基盤を構築できます。
- 簡単セットアップ: S3にドキュメントを置いてKBを作成するだけ
- フルマネージド: ベクトルDB・Embeddingの管理不要
- 高精度: Semanticチャンキング+Claude 4で高品質な回答
- スケーラブル: ドキュメント増加に自動対応
- セキュア: IAMベースのアクセス制御、暗号化対応
SESエンジニアとしてRAG構築スキルを身につけることは、AI時代の市場価値を大きく高める投資です。本記事の手順を参考に、まずは小規模なKnowledge Baseを構築してみましょう。
関連記事
- Bedrock生成AIガイド — Bedrockの基本的な使い方
- Bedrockエージェント — AIエージェントの構築
- S3 Vectors — S3ネイティブベクトル検索
- SageMaker MLガイド — 機械学習基盤の構築
- IAMセキュリティ — AWSセキュリティの基本





