
- AWS Batchはコンテナベースのフルマネージドバッチ処理サービスで、キャパシティ管理が不要
- Spotインスタンス活用で最大90%のコスト削減が可能
- Step Functionsとの統合で複雑なワークフローも簡単に構築できる
「大量のデータ処理をAWSでやりたいけど、EC2のスケーリングが面倒」「バッチ処理のコストを削減したい」「AWS BatchとLambdaの使い分けがわからない」
AWS Batchは、コンテナベースのバッチ処理を完全にマネージドで実行するサービスです。 キャパシティ管理、スケーリング、ジョブスケジューリングをすべてAWSに任せることで、エンジニアはビジネスロジックに集中できます。Spotインスタンスの活用により、大規模処理でも驚くほどのコスト削減が可能です。
この記事では、AWS完全攻略シリーズEp.52として、AWS Batchの基礎から実践的な運用パターンまでを徹底解説します。
- AWS Batchの基本概念とアーキテクチャ
- コンピューティング環境の設計パターン
- Spotインスタンスによるコスト最適化
- Step Functionsとの統合ワークフロー
AWS Batchとは?フルマネージドバッチ処理の基礎
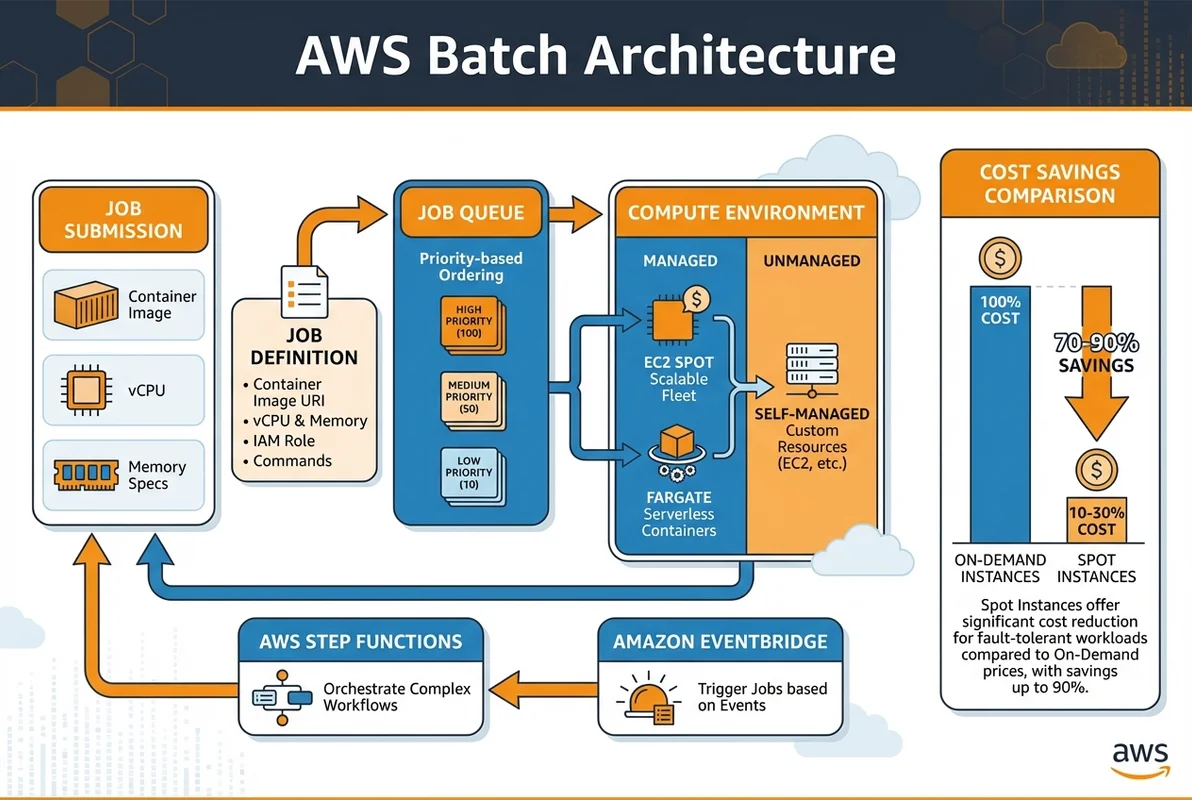
AWS Batchの基本コンポーネント
AWS Batchは以下の4つの主要コンポーネントで構成されています。
ジョブ定義(Job Definition)
→ 実行するコンテナイメージ、CPU/メモリ要件を定義
ジョブ(Job)
→ 実際に実行される処理の単位
ジョブキュー(Job Queue)
→ ジョブの投入先。優先度と紐づくコンピューティング環境を管理
コンピューティング環境(Compute Environment)
→ 実際にジョブを実行するインフラ(EC2 or Fargate)AWS Batch vs Lambda vs ECS の使い分け
| 特性 | AWS Batch | Lambda | ECS |
|---|---|---|---|
| 実行時間制限 | なし | 15分 | なし |
| 最大メモリ | 制限なし | 10GB | 制限なし |
| スケーリング | 自動 | 自動 | 手動/Auto Scaling |
| コスト | 実行時間のみ | 呼び出し回数 | 常時起動 |
| GPU対応 | ✅ | ❌ | ✅ |
| 適用シーン | バッチ処理 | イベント駆動 | 常時稼働サービス |
AWS Batchを選ぶべきシーン:
- 処理時間が15分を超える
- 大量のメモリやCPUが必要
- GPUを利用する機械学習ジョブ
- 数百〜数千のジョブを並列実行
- Spotインスタンスでコスト最適化したい
AWS Batchの構築方法
Step 1: コンピューティング環境の作成
# Fargate型コンピューティング環境(サーバーレス)
aws batch create-compute-environment \
--compute-environment-name my-fargate-env \
--type MANAGED \
--state ENABLED \
--compute-resources '{
"type": "FARGATE",
"maxvCpus": 256,
"subnets": ["subnet-12345678", "subnet-87654321"],
"securityGroupIds": ["sg-12345678"]
}'# EC2 Spotインスタンス型(コスト最適化)
aws batch create-compute-environment \
--compute-environment-name my-spot-env \
--type MANAGED \
--state ENABLED \
--compute-resources '{
"type": "SPOT",
"allocationStrategy": "SPOT_PRICE_CAPACITY_OPTIMIZED",
"minvCpus": 0,
"maxvCpus": 1024,
"desiredvCpus": 0,
"instanceTypes": ["m6i.xlarge", "m6i.2xlarge", "m5.xlarge", "m5.2xlarge"],
"subnets": ["subnet-12345678"],
"securityGroupIds": ["sg-12345678"],
"instanceRole": "arn:aws:iam::123456789012:instance-profile/ecsInstanceRole",
"bidPercentage": 60,
"spotIamFleetRole": "arn:aws:iam::123456789012:role/AmazonEC2SpotFleetRole"
}'Step 2: ジョブキューの作成
# 優先度の異なる2つのキュー
aws batch create-job-queue \
--job-queue-name high-priority-queue \
--state ENABLED \
--priority 10 \
--compute-environment-order '[
{"order": 1, "computeEnvironment": "my-fargate-env"}
]'
aws batch create-job-queue \
--job-queue-name low-priority-queue \
--state ENABLED \
--priority 1 \
--compute-environment-order '[
{"order": 1, "computeEnvironment": "my-spot-env"}
]'Step 3: ジョブ定義の作成
// job-definition.json
{
"jobDefinitionName": "data-processing-job",
"type": "container",
"platformCapabilities": ["FARGATE"],
"containerProperties": {
"image": "123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/batch-processor:latest",
"resourceRequirements": [
{"type": "VCPU", "value": "4"},
{"type": "MEMORY", "value": "8192"}
],
"executionRoleArn": "arn:aws:iam::123456789012:role/ecsTaskExecutionRole",
"jobRoleArn": "arn:aws:iam::123456789012:role/batchJobRole",
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/aws/batch/data-processing",
"awslogs-region": "ap-northeast-1",
"awslogs-stream-prefix": "batch"
}
},
"environment": [
{"name": "ENV", "value": "production"},
{"name": "REGION", "value": "ap-northeast-1"}
],
"secrets": [
{
"name": "DATABASE_URL",
"valueFrom": "arn:aws:secretsmanager:ap-northeast-1:123456789012:secret:db-url"
}
]
},
"retryStrategy": {
"attempts": 3,
"evaluateOnExit": [
{"onStatusReason": "Host EC2*", "action": "RETRY"},
{"onReason": "CannotPullContainerError*", "action": "RETRY"},
{"onExitCode": "1", "action": "EXIT"}
]
},
"timeout": {
"attemptDurationSeconds": 3600
}
}# ジョブ定義の登録
aws batch register-job-definition --cli-input-json file://job-definition.jsonStep 4: ジョブの実行
# 単一ジョブの実行
aws batch submit-job \
--job-name process-2026-q1 \
--job-queue high-priority-queue \
--job-definition data-processing-job \
--container-overrides '{
"environment": [
{"name": "INPUT_PATH", "value": "s3://my-bucket/input/2026-q1/"},
{"name": "OUTPUT_PATH", "value": "s3://my-bucket/output/2026-q1/"}
]
}'
# Array Job(並列バッチ)
aws batch submit-job \
--job-name parallel-process \
--job-queue low-priority-queue \
--job-definition data-processing-job \
--array-properties '{"size": 100}' \
--container-overrides '{
"environment": [
{"name": "TOTAL_SHARDS", "value": "100"}
]
}'Spotインスタンスによるコスト最適化
Spotインスタンスの基礎
Spotインスタンスは、AWSの余剰キャパシティを最大90%割引で利用できるサービスです。ただし、AWSの需要に応じて2分前通知で中断される可能性があります。
オンデマンド価格: m6i.xlarge = $0.192/h
スポット価格: m6i.xlarge = $0.058/h(約70%割引)
1000ジョブ × 1時間/ジョブの場合:
オンデマンド: $192.00
スポット: $58.00($134の節約)中断耐性の設計
# batch_processor.py - チェックポイント対応のバッチ処理
import boto3
import json
import os
import signal
s3 = boto3.client('s3')
CHECKPOINT_BUCKET = os.environ['CHECKPOINT_BUCKET']
JOB_ID = os.environ.get('AWS_BATCH_JOB_ID', 'local')
class BatchProcessor:
def __init__(self):
self.checkpoint = self.load_checkpoint()
self.processed_count = self.checkpoint.get('processed_count', 0)
signal.signal(signal.SIGTERM, self.handle_termination)
def load_checkpoint(self):
try:
response = s3.get_object(
Bucket=CHECKPOINT_BUCKET,
Key=f'checkpoints/{JOB_ID}.json'
)
return json.loads(response['Body'].read())
except s3.exceptions.NoSuchKey:
return {}
def save_checkpoint(self):
s3.put_object(
Bucket=CHECKPOINT_BUCKET,
Key=f'checkpoints/{JOB_ID}.json',
Body=json.dumps({
'processed_count': self.processed_count,
'last_item_id': self.last_item_id
})
)
def handle_termination(self, signum, frame):
print(f"SIGTERM受信。チェックポイント保存中... ({self.processed_count}件処理済み)")
self.save_checkpoint()
exit(0)
def process(self, items):
# チェックポイントから再開
start_index = self.checkpoint.get('processed_count', 0)
for i, item in enumerate(items[start_index:], start=start_index):
self.process_item(item)
self.processed_count = i + 1
self.last_item_id = item['id']
# 100件ごとにチェックポイント保存
if self.processed_count % 100 == 0:
self.save_checkpoint()
print(f"チェックポイント保存: {self.processed_count}件完了")
self.save_checkpoint()
print(f"全{self.processed_count}件の処理完了")
def process_item(self, item):
# 実際のビジネスロジック
pass最適なインスタンスタイプ戦略
{
"computeResources": {
"type": "SPOT",
"allocationStrategy": "SPOT_PRICE_CAPACITY_OPTIMIZED",
"instanceTypes": [
"m6i.xlarge", "m6i.2xlarge",
"m5.xlarge", "m5.2xlarge",
"m6a.xlarge", "m6a.2xlarge",
"c6i.xlarge", "c6i.2xlarge",
"r6i.xlarge"
]
}
}SPOT_PRICE_CAPACITY_OPTIMIZED は、価格とキャパシティのバランスを最適化する推奨戦略です。
Step Functionsとの統合
ETLパイプラインの構築
{
"Comment": "AWS Batch ETL Pipeline",
"StartAt": "ExtractData",
"States": {
"ExtractData": {
"Type": "Task",
"Resource": "arn:aws:states:::batch:submitJob.sync",
"Parameters": {
"JobDefinition": "arn:aws:batch:ap-northeast-1:123456789012:job-definition/extract-job:1",
"JobName": "extract-data",
"JobQueue": "high-priority-queue",
"ContainerOverrides": {
"Environment": [
{"Name": "SOURCE_DB", "Value.$": "$.sourceDb"},
{"Name": "DATE_RANGE", "Value.$": "$.dateRange"}
]
}
},
"ResultPath": "$.extractResult",
"Next": "TransformData",
"Retry": [
{
"ErrorEquals": ["Batch.ServerException"],
"IntervalSeconds": 30,
"MaxAttempts": 3,
"BackoffRate": 2
}
]
},
"TransformData": {
"Type": "Task",
"Resource": "arn:aws:states:::batch:submitJob.sync",
"Parameters": {
"JobDefinition": "arn:aws:batch:ap-northeast-1:123456789012:job-definition/transform-job:1",
"JobName": "transform-data",
"JobQueue": "high-priority-queue",
"ArrayProperties": {
"Size": 10
}
},
"ResultPath": "$.transformResult",
"Next": "LoadData"
},
"LoadData": {
"Type": "Task",
"Resource": "arn:aws:states:::batch:submitJob.sync",
"Parameters": {
"JobDefinition": "arn:aws:batch:ap-northeast-1:123456789012:job-definition/load-job:1",
"JobName": "load-data",
"JobQueue": "high-priority-queue"
},
"ResultPath": "$.loadResult",
"Next": "NotifyCompletion"
},
"NotifyCompletion": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "arn:aws:sns:ap-northeast-1:123456789012:batch-notifications",
"Message.$": "States.Format('ETLパイプライン完了: {}', $.loadResult.Status)"
},
"End": true
}
}
}EventBridgeによるスケジュール実行
# 毎日午前2時にETLパイプラインを実行
aws events put-rule \
--name daily-etl-pipeline \
--schedule-expression "cron(0 17 * * ? *)" \
--state ENABLED
aws events put-targets \
--rule daily-etl-pipeline \
--targets '[{
"Id": "etl-step-function",
"Arn": "arn:aws:states:ap-northeast-1:123456789012:stateMachine:etl-pipeline",
"Input": "{\"sourceDb\": \"production\", \"dateRange\": \"yesterday\"}"
}]'Terraform(IaC)によるAWS Batch構築
# main.tf
resource "aws_batch_compute_environment" "spot" {
compute_environment_name = "spot-compute-env"
type = "MANAGED"
state = "ENABLED"
compute_resources {
type = "SPOT"
allocation_strategy = "SPOT_PRICE_CAPACITY_OPTIMIZED"
bid_percentage = 60
min_vcpus = 0
max_vcpus = 1024
desired_vcpus = 0
instance_type = [
"m6i.xlarge", "m6i.2xlarge",
"m5.xlarge", "m5.2xlarge"
]
subnets = var.subnet_ids
security_group_ids = [aws_security_group.batch.id]
instance_role = aws_iam_instance_profile.batch.arn
spot_iam_fleet_role = aws_iam_role.spot_fleet.arn
}
service_role = aws_iam_role.batch_service.arn
}
resource "aws_batch_job_queue" "main" {
name = "main-queue"
state = "ENABLED"
priority = 10
compute_environment_order {
order = 1
compute_environment = aws_batch_compute_environment.spot.arn
}
}
resource "aws_batch_job_definition" "processor" {
name = "data-processor"
type = "container"
platform_capabilities = ["EC2"]
container_properties = jsonencode({
image = "${var.ecr_repo_url}:latest"
resourceRequirements = [
{ type = "VCPU", value = "4" },
{ type = "MEMORY", value = "8192" }
]
executionRoleArn = aws_iam_role.execution.arn
jobRoleArn = aws_iam_role.job.arn
logConfiguration = {
logDriver = "awslogs"
options = {
"awslogs-group" = aws_cloudwatch_log_group.batch.name
"awslogs-region" = var.region
"awslogs-stream-prefix" = "batch"
}
}
})
retry_strategy {
attempts = 3
evaluate_on_exit {
on_status_reason = "Host EC2*"
action = "RETRY"
}
}
timeout {
attempt_duration_seconds = 3600
}
}監視とアラート
CloudWatchダッシュボード
# ジョブの状態監視
aws batch describe-jobs --jobs $JOB_ID \
| jq '{status: .jobs[0].status, startedAt: .jobs[0].startedAt, stoppedAt: .jobs[0].stoppedAt}'
# キューの状態確認
aws batch describe-job-queues --job-queues main-queue \
| jq '.jobQueues[0].status'CloudWatchアラーム
# ジョブ失敗アラーム
aws cloudwatch put-metric-alarm \
--alarm-name batch-job-failure \
--metric-name FailedJobCount \
--namespace AWS/Batch \
--statistic Sum \
--period 300 \
--threshold 5 \
--comparison-operator GreaterThanThreshold \
--evaluation-periods 1 \
--alarm-actions "arn:aws:sns:ap-northeast-1:123456789012:alerts"SES案件でのAWS Batch活用事例
事例1: 金融データの日次バッチ処理
大手金融機関のSES案件で、日次の取引データ処理にAWS Batchを導入しました。
成果:
- 処理時間: 8時間→45分(10倍以上高速化)
- コスト: Spot活用で月額$3,200→$800に削減
- 運用工数: EC2管理が不要になり、月20時間の削減
事例2: ECサイトの商品画像一括変換
数百万枚の商品画像のリサイズ・フォーマット変換をAWS Batchで並列処理しました。
成果:
- 100万枚の処理を2時間で完了
- Array Jobで500並列実行
- Spotインスタンス活用でコスト85%削減
事例3: ログ分析パイプライン
数TB/日のアプリケーションログをAWS Batchで解析し、異常検知を行うパイプラインを構築しました。
成果:
- リアルタイムに近い分析(15分遅延)
- Step Functionsとの統合で完全自動化
- 異常検知の精度が手動分析と同等以上
まとめ: AWS Batchで大規模処理をスマートに
AWS Batchは、大規模なバッチ処理をサーバーレスに近い運用負荷で実行できる強力なサービスです。
AWS Batchを選ぶべきポイント:
- ✅ 処理時間が15分を超えるジョブ
- ✅ 並列化で高速化したい大量処理
- ✅ Spotインスタンスでコスト最適化したい
- ✅ GPU対応の機械学習バッチが必要
- ✅ Step Functionsで複雑なワークフローを組みたい
SESエンジニアとしてAWS Batchの設計・運用スキルを身につけることで、データエンジニアリングやMLOps分野での活躍の幅が大きく広がります。
- AWS Batchの実装経験は、データエンジニア案件で高い需要がある
- Spotインスタンスのコスト最適化スキルは、FinOps案件でも評価される
- Step Functions統合の設計経験は、アーキテクトへのキャリアアップに直結





