
「バックアップを取っていたはずなのに、復旧できなかった」「DR(ディザスタリカバリ)の設計を任されたが、何から始めればいいかわからない」「バックアップコストが膨らんで予算を超過している」——SES現場でインフラ運用を担当するエンジニアにとって、バックアップとDRは避けて通れない重要テーマです。
**AWS Backupは、AWSの主要サービスのバックアップを一元管理し、ディザスタリカバリまで統合的に実現するフルマネージドサービスです。**EC2、RDS、DynamoDB、EFS、S3など20以上のAWSサービスのバックアップを、統一されたポリシーで管理できます。
本記事では、AWS Backupの基礎から、クロスリージョンDR、コスト最適化まで、SESエンジニアが現場で即活用できる実践的な内容を解説します。
AWS Backupとは
従来のバックアップ運用の課題
AWS Backup登場以前は、サービスごとに個別のバックアップ設定が必要でした。
| サービス | 従来の方法 | 課題 |
|---|---|---|
| EC2 | AMI/スナップショット手動作成 | スケジュール管理が煩雑 |
| RDS | 自動バックアップ + 手動スナップショット | 保持期間の統一が困難 |
| DynamoDB | オンデマンドバックアップ | クロスリージョンコピー非対応 |
| EFS | AWS Backupのみ | — |
| S3 | バージョニング + ライフサイクル | 一元管理不可 |
AWS Backupの統合管理
AWS Backupでは、これらすべてのサービスをバックアッププランという統一されたポリシーで管理できます。
主な機能:
- バックアッププラン:スケジュール・保持期間・ライフサイクルを定義
- バックアップボールト:バックアップの保管場所(暗号化対応)
- クロスリージョンコピー:別リージョンへの自動レプリケーション
- クロスアカウントコピー:別アカウントへのバックアップ転送
- バックアップ監査マネージャー:コンプライアンス準拠の監視
AWS IAMセキュリティガイドで解説したアクセス制御と組み合わせると、より堅牢なバックアップ体制を構築できます。
バックアッププランの設計
RTO/RPOに基づく設計
ディザスタリカバリの設計は、**RTO(目標復旧時間)とRPO(目標復旧地点)**から始めます。
RPO(Recovery Point Objective)
= 「どこまでのデータロスを許容できるか」
例: RPO 1時間 → 最大1時間分のデータが失われる可能性
RTO(Recovery Time Objective)
= 「復旧にどれだけの時間をかけられるか」
例: RTO 4時間 → 障害発生から4時間以内に復旧バックアッププランの段階設計
{
"BackupPlan": {
"BackupPlanName": "production-backup-plan",
"Rules": [
{
"RuleName": "hourly-backup",
"ScheduleExpression": "cron(0 * * * ? *)",
"StartWindowMinutes": 60,
"CompletionWindowMinutes": 120,
"Lifecycle": {
"DeleteAfterDays": 7
},
"TargetBackupVaultName": "production-vault",
"CopyActions": [
{
"DestinationBackupVaultArn": "arn:aws:backup:ap-northeast-3:123456789012:backup-vault:dr-vault",
"Lifecycle": {
"DeleteAfterDays": 3
}
}
]
},
{
"RuleName": "daily-backup",
"ScheduleExpression": "cron(0 3 * * ? *)",
"StartWindowMinutes": 60,
"CompletionWindowMinutes": 180,
"Lifecycle": {
"MoveToColdStorageAfterDays": 30,
"DeleteAfterDays": 365
},
"TargetBackupVaultName": "production-vault",
"CopyActions": [
{
"DestinationBackupVaultArn": "arn:aws:backup:ap-northeast-3:123456789012:backup-vault:dr-vault",
"Lifecycle": {
"MoveToColdStorageAfterDays": 30,
"DeleteAfterDays": 365
}
}
]
},
{
"RuleName": "monthly-backup",
"ScheduleExpression": "cron(0 3 1 * ? *)",
"StartWindowMinutes": 120,
"CompletionWindowMinutes": 360,
"Lifecycle": {
"MoveToColdStorageAfterDays": 90,
"DeleteAfterDays": 2555
},
"TargetBackupVaultName": "production-vault"
}
]
}
}Terraformでの実装
# バックアップボールト
resource "aws_backup_vault" "production" {
name = "production-vault"
kms_key_arn = aws_kms_key.backup.arn
tags = {
Environment = "production"
ManagedBy = "terraform"
}
}
# DRリージョンのバックアップボールト
resource "aws_backup_vault" "dr" {
provider = aws.dr_region
name = "dr-vault"
kms_key_arn = aws_kms_key.backup_dr.arn
}
# バックアッププラン
resource "aws_backup_plan" "production" {
name = "production-backup-plan"
# 毎時バックアップ(7日保持)
rule {
rule_name = "hourly-backup"
target_vault_name = aws_backup_vault.production.name
schedule = "cron(0 * * * ? *)"
lifecycle {
delete_after = 7
}
copy_action {
destination_vault_arn = aws_backup_vault.dr.arn
lifecycle {
delete_after = 3
}
}
}
# 日次バックアップ(1年保持、30日後にコールドストレージ)
rule {
rule_name = "daily-backup"
target_vault_name = aws_backup_vault.production.name
schedule = "cron(0 3 * * ? *)"
lifecycle {
cold_storage_after = 30
delete_after = 365
}
copy_action {
destination_vault_arn = aws_backup_vault.dr.arn
lifecycle {
cold_storage_after = 30
delete_after = 365
}
}
}
# 月次バックアップ(7年保持)
rule {
rule_name = "monthly-backup"
target_vault_name = aws_backup_vault.production.name
schedule = "cron(0 3 1 * ? *)"
lifecycle {
cold_storage_after = 90
delete_after = 2555
}
}
}
# バックアップ対象のリソース選択
resource "aws_backup_selection" "production" {
name = "production-resources"
iam_role_arn = aws_iam_role.backup.arn
plan_id = aws_backup_plan.production.id
# タグベースの選択
selection_tag {
type = "STRINGEQUALS"
key = "Backup"
value = "true"
}
}
# バックアップ用IAMロール
resource "aws_iam_role" "backup" {
name = "aws-backup-role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "backup.amazonaws.com"
}
}
]
})
}
resource "aws_iam_role_policy_attachment" "backup" {
role = aws_iam_role.backup.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSBackupServiceRolePolicyForBackup"
}
resource "aws_iam_role_policy_attachment" "restore" {
role = aws_iam_role.backup.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSBackupServiceRolePolicyForRestores"
}クロスリージョン・ディザスタリカバリ
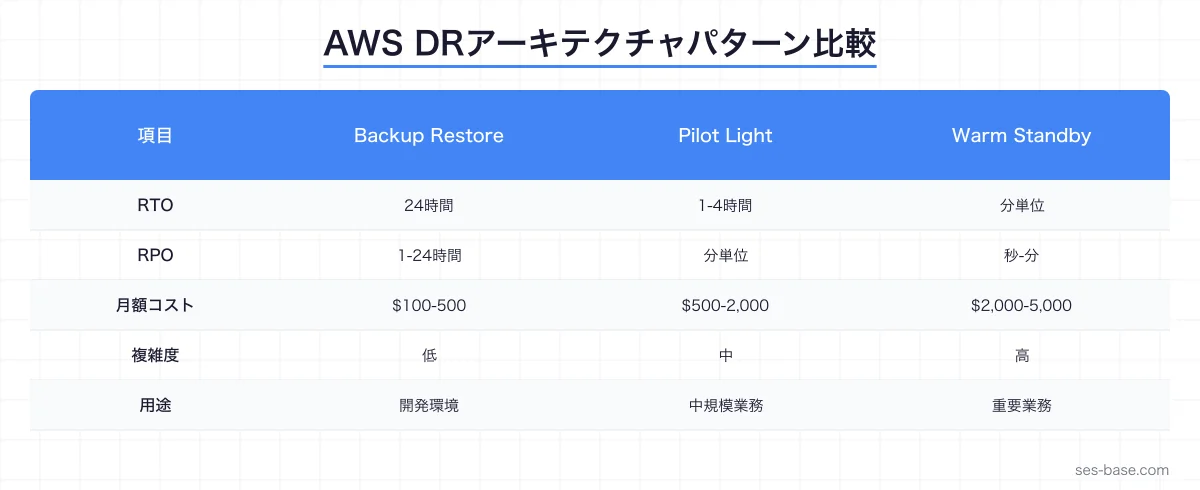
DRアーキテクチャパターン
AWSのDRパターンは、コストとRTOのバランスで4段階に分類されます。
| パターン | RTO | RPO | 月額コスト例 | ユースケース |
|---|---|---|---|---|
| Backup & Restore | 24時間 | 1-24時間 | $100-500 | 開発環境、非重要システム |
| Pilot Light | 1-4時間 | 分単位 | $500-2,000 | 中規模業務システム |
| Warm Standby | 分単位 | 秒-分単位 | $2,000-5,000 | 重要業務システム |
| Multi-Site Active | ゼロ | ゼロ | $5,000+ | ミッションクリティカル |
Backup & Restore パターンの実装
最もコスト効率の良いパターンとして、Backup & Restore の実装を詳しく見ていきます。
#!/bin/bash
# dr-restore.sh
# DRリージョンでの復旧スクリプト
set -euo pipefail
DR_REGION="ap-northeast-3" # 大阪
SOURCE_REGION="ap-northeast-1" # 東京
BACKUP_VAULT="dr-vault"
echo "🔄 ディザスタリカバリ復旧開始"
echo "DRリージョン: $DR_REGION"
# 1. 最新のバックアップリカバリポイントを取得
echo "📋 リカバリポイントの確認..."
RECOVERY_POINTS=$(aws backup list-recovery-points-by-backup-vault \
--backup-vault-name "$BACKUP_VAULT" \
--region "$DR_REGION" \
--query 'RecoveryPoints | sort_by(@, &CreationDate) | [-5:]' \
--output json)
echo "$RECOVERY_POINTS" | jq -r '.[] | "\(.ResourceType) | \(.CreationDate) | \(.Status)"'
# 2. RDSの復旧
echo "🗄️ RDS復旧開始..."
RDS_RECOVERY=$(echo "$RECOVERY_POINTS" | jq -r '[.[] | select(.ResourceType == "RDS")] | last | .RecoveryPointArn')
if [ "$RDS_RECOVERY" != "null" ]; then
aws backup start-restore-job \
--recovery-point-arn "$RDS_RECOVERY" \
--iam-role-arn "arn:aws:iam::123456789012:role/aws-backup-role" \
--metadata '{
"DBInstanceIdentifier": "production-db-dr",
"DBInstanceClass": "db.r6g.large",
"MultiAZ": "false",
"PubliclyAccessible": "false"
}' \
--region "$DR_REGION"
echo "✅ RDS復旧ジョブ開始"
fi
# 3. EC2の復旧
echo "🖥️ EC2復旧開始..."
EC2_RECOVERY=$(echo "$RECOVERY_POINTS" | jq -r '[.[] | select(.ResourceType == "EC2")] | last | .RecoveryPointArn')
if [ "$EC2_RECOVERY" != "null" ]; then
aws backup start-restore-job \
--recovery-point-arn "$EC2_RECOVERY" \
--iam-role-arn "arn:aws:iam::123456789012:role/aws-backup-role" \
--metadata '{
"InstanceType": "m6g.large",
"SubnetId": "subnet-dr-12345",
"SecurityGroupIds": "sg-dr-12345"
}' \
--region "$DR_REGION"
echo "✅ EC2復旧ジョブ開始"
fi
# 4. DynamoDBの復旧
echo "📊 DynamoDB復旧開始..."
DYNAMO_RECOVERY=$(echo "$RECOVERY_POINTS" | jq -r '[.[] | select(.ResourceType == "DynamoDB")] | last | .RecoveryPointArn')
if [ "$DYNAMO_RECOVERY" != "null" ]; then
aws backup start-restore-job \
--recovery-point-arn "$DYNAMO_RECOVERY" \
--iam-role-arn "arn:aws:iam::123456789012:role/aws-backup-role" \
--metadata '{
"targetTableName": "production-table-dr"
}' \
--region "$DR_REGION"
echo "✅ DynamoDB復旧ジョブ開始"
fi
echo "🔄 全復旧ジョブ開始完了 — 復旧状況をモニタリングしてください"Pilot Light パターンの実装
# DRリージョンにミニマム構成を常時稼働
# 障害時にスケールアップする
# DRリージョンの最小RDS(常時稼働)
resource "aws_db_instance" "dr_pilot" {
provider = aws.dr_region
identifier = "production-db-dr"
engine = "mysql"
engine_version = "8.0"
instance_class = "db.t3.micro" # 最小インスタンス
allocated_storage = 20
# 本番リージョンからのリードレプリカとして設定
replicate_source_db = aws_db_instance.production.arn
tags = {
Role = "dr-pilot-light"
}
}
# 障害時にスケールアップ
# aws rds modify-db-instance \
# --db-instance-identifier production-db-dr \
# --db-instance-class db.r6g.large \
# --apply-immediatelyバックアップの監視とアラート
CloudWatch アラームの設定
# バックアップジョブの失敗監視
resource "aws_cloudwatch_metric_alarm" "backup_failed" {
alarm_name = "backup-job-failed"
comparison_operator = "GreaterThanThreshold"
evaluation_periods = 1
metric_name = "NumberOfBackupJobsFailed"
namespace = "AWS/Backup"
period = 86400 # 24時間
statistic = "Sum"
threshold = 0
alarm_description = "バックアップジョブが失敗しました"
alarm_actions = [aws_sns_topic.alerts.arn]
dimensions = {
BackupVaultName = aws_backup_vault.production.name
}
}
# バックアップサイズの異常検知
resource "aws_cloudwatch_metric_alarm" "backup_size_anomaly" {
alarm_name = "backup-size-anomaly"
comparison_operator = "GreaterThanThreshold"
evaluation_periods = 1
metric_name = "BackupVaultTotalRecoveryPointSize"
namespace = "AWS/Backup"
period = 86400
statistic = "Average"
threshold = 1099511627776 # 1TB
alarm_description = "バックアップの合計サイズが1TBを超えました"
alarm_actions = [aws_sns_topic.alerts.arn]
}バックアップ監査マネージャー
# バックアップ監査フレームワーク
resource "aws_backup_framework" "compliance" {
name = "backup-compliance-framework"
control {
name = "BACKUP_RESOURCES_PROTECTED_BY_BACKUP_PLAN"
input_parameter {
name = "resourceType"
value = "RDS"
}
}
control {
name = "BACKUP_RECOVERY_POINT_MINIMUM_RETENTION_CHECK"
input_parameter {
name = "requiredRetentionDays"
value = "35"
}
}
control {
name = "BACKUP_RECOVERY_POINT_ENCRYPTED"
}
control {
name = "BACKUP_PLAN_MIN_FREQUENCY_AND_MIN_RETENTION_CHECK"
input_parameter {
name = "requiredFrequencyUnit"
value = "hours"
}
input_parameter {
name = "requiredFrequencyValue"
value = "24"
}
input_parameter {
name = "requiredRetentionDays"
value = "35"
}
}
}コスト最適化
バックアップコストの構造
AWS Backupのコストは以下で構成されます。
- ストレージ料金:ウォームストレージ $0.05/GB/月、コールドストレージ $0.01/GB/月
- リストア料金:サービスごとに異なる
- クロスリージョンコピー:データ転送料金 + ストレージ料金
コスト削減のベストプラクティス
# ライフサイクルポリシーでコスト最適化
resource "aws_backup_plan" "cost_optimized" {
name = "cost-optimized-plan"
rule {
rule_name = "daily-with-lifecycle"
target_vault_name = aws_backup_vault.production.name
schedule = "cron(0 3 * * ? *)"
lifecycle {
# 7日後にコールドストレージへ移行($0.05 → $0.01/GB)
cold_storage_after = 7
# 90日後に削除
delete_after = 90
}
}
}コスト削減チェックリスト:
- ✅ 不要な古いリカバリポイントを定期的に削除
- ✅ コールドストレージへの移行を早期に設定
- ✅ クロスリージョンコピーの保持期間を短く
- ✅ 開発/ステージング環境のバックアップ頻度を下げる
- ✅ タグベースの選択で不要なリソースを除外
AWS FinOpsガイドも参照してコスト管理全般の知見を深めてください。
DR訓練(ゲームデー)の実施
訓練計画テンプレート
## DR訓練計画書
### 概要
- 日時: 2026年4月15日 10:00-16:00 JST
- 対象: 本番環境のバックアップ/復旧
- 参加者: インフラチーム3名
### 訓練シナリオ
1. 東京リージョンのRDSが完全停止
2. AWS Backupから大阪リージョンに復旧
3. Route 53のフェイルオーバーで切り替え
### 成功基準
- RTO 4時間以内に復旧完了
- RPO 1時間以内(最新バックアップからのデータロスが1時間以内)
- 全APIエンドポイントが正常応答
### 実施手順
1. 【10:00】訓練開始宣言
2. 【10:15】復旧スクリプトの実行
3. 【12:00】RDS復旧完了確認
4. 【13:00】アプリケーション起動・接続確認
5. 【14:00】動作確認テスト実行
6. 【15:00】振り返り・改善点の洗い出し
7. 【16:00】訓練完了・報告書作成自動DR訓練スクリプト
#!/bin/bash
# dr-drill.sh - DR訓練自動化スクリプト
set -euo pipefail
LOG_FILE="dr-drill-$(date +%Y%m%d-%H%M%S).log"
log() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1" | tee -a "$LOG_FILE"
}
# 1. 最新バックアップの確認
log "📋 Step 1: 最新バックアップの確認"
LATEST_BACKUP=$(aws backup list-recovery-points-by-backup-vault \
--backup-vault-name dr-vault \
--region ap-northeast-3 \
--query 'RecoveryPoints | sort_by(@, &CreationDate) | [-1].CreationDate' \
--output text)
log "最新バックアップ: $LATEST_BACKUP"
# 2. 復旧の実行
log "🔄 Step 2: 復旧ジョブの開始"
START_TIME=$(date +%s)
RESTORE_JOB_ID=$(aws backup start-restore-job \
--recovery-point-arn "$(aws backup list-recovery-points-by-backup-vault \
--backup-vault-name dr-vault \
--region ap-northeast-3 \
--query 'RecoveryPoints | sort_by(@, &CreationDate) | [-1].RecoveryPointArn' \
--output text)" \
--iam-role-arn "arn:aws:iam::123456789012:role/aws-backup-role" \
--metadata '{"DBInstanceIdentifier":"dr-drill-db","DBInstanceClass":"db.t3.medium"}' \
--region ap-northeast-3 \
--output text --query 'RestoreJobId')
log "復旧ジョブID: $RESTORE_JOB_ID"
# 3. 復旧完了待ち
log "⏳ Step 3: 復旧完了待ち..."
while true; do
STATUS=$(aws backup describe-restore-job \
--restore-job-id "$RESTORE_JOB_ID" \
--region ap-northeast-3 \
--query 'Status' --output text)
log "ステータス: $STATUS"
if [ "$STATUS" = "COMPLETED" ]; then
break
elif [ "$STATUS" = "FAILED" ]; then
log "❌ 復旧失敗"
exit 1
fi
sleep 60
done
END_TIME=$(date +%s)
DURATION=$(( (END_TIME - START_TIME) / 60 ))
log "✅ 復旧完了 (所要時間: ${DURATION}分)"
# 4. クリーンアップ
log "🧹 Step 4: 訓練用リソースのクリーンアップ"
aws rds delete-db-instance \
--db-instance-identifier dr-drill-db \
--skip-final-snapshot \
--region ap-northeast-3
log "📊 DR訓練完了 — RTO実績: ${DURATION}分"SES現場でのバックアップ運用提案
クライアントへの提案ポイント
- 現状の可視化:「バックアップ未設定のリソースが○○件あります」
- リスク定量化:「現在のRPOは24時間 → 最悪1日分のデータロスが発生」
- 段階的な改善:Phase 1(基本バックアップ) → Phase 2(クロスリージョンDR) → Phase 3(自動DR訓練)
- コスト試算:「月額$○○で、RTOを24時間から4時間に短縮可能」
AWS Well-Architected Frameworkガイドの信頼性の柱も参照してください。
まとめ|AWS Backupで「守りのインフラ」を固める
AWS Backupは、SESエンジニアがインフラ運用の信頼性を大幅に向上させるための強力なツールです。
- バックアッププランでスケジュール・保持期間・ライフサイクルを一元管理
- クロスリージョンコピーで地域災害にも対応したDR体制を構築
- Terraformでバックアップ設定をIaC化し、再現性と監査性を確保
- コールドストレージで長期保持のコストを80%削減
- DR訓練を定期実施し、復旧手順の実効性を検証
「バックアップは保険」です。事故が起きてからでは遅い。AWS Backupを正しく設計・運用して、クライアントのビジネスを守りましょう。
CloudTrailセキュリティガイドやVPCネットワークガイドも合わせて参照し、インフラセキュリティの総合力を高めてください。
AWSの活用法をさらに深く学びたい方は、AWSシリーズをご覧ください。最新の実践ガイドを随時更新しています。





